import torch
import pandas as pd
from matplotlib import pyplot as plt
import matplotlib.ticker as mtick
import torch.nn as nn
from torch.nn import Conv2d, MaxPool2d, Parameter
from torch.nn.functional import relu
from torchvision import models
from sklearn.metrics import confusion_matrix
import torch.optim as optim
from torchsummary import summary
plt.style.use('seaborn-v0_8-whitegrid')17 Deep Image Classification
Open the live notebook in Google Colab or download the live notebook
.In this set of lecture notes, we’ll work through an applied case study of deep learning for image classification. Like our last adventure with an image classification task, we’ll focus on sign-language classification using convolutional kernels. This time, however, we won’t take the kernels as given. Instead, we’ll attempt to optimize the kernels as part of the learning process.
Along the way, we’ll also study some of the practicalities of working with larger models in torch, including model inspection, GPU acceleration, and data set management.
A Note On Chips
As we’ve seen from the last several lectures, deep learning models involve a lot of linear algebra in order to compute predictions and gradients. This means that deep models, even more than many other machine learning models, strongly benefit from hardware that is good at doing linear algebra fast. As it happens, graphics processing units (GPUs) are very, very good at fast linear algebra. So, it’s very helpful when running our models to have access to GPUs; using a GPU can often result in up to 10x speedups. While some folks can use GPUs on their personal laptops, another common option for learning purposes is to use a cloud-hosted GPU. My personal recommendation is Google Colab, and I’ll supply links that allow you to open lecture notes in Colab and use their GPU runtimes.
The reason that GPUs are so good at this is that they were originally optimized for rendering complex graphics in e.g. animation and video games, and this involves lots of linear algebra.
The following torch code checks whether there is a GPU available to Python, and if so, sets a variable called device to log this fact. We’ll make sure that both our data and our models fully live on the same device when doing model training.
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Running on {device}.")Running on cuda.Now let’s acquire our data and convert it into a tensor format. We’ll continue to work on the Sign Language MNIST data set, which I retrieved from Kaggle. Our aim is still to train a model that can predict the letter represented by an image of a hand gesture.
train_url = "https://raw.githubusercontent.com/PhilChodrow/ml-notes/main/data/sign-language-mnist/sign_mnist_train.csv"
test_url = "https://raw.githubusercontent.com/PhilChodrow/ml-notes/main/data/sign-language-mnist/sign_mnist_test.csv"
df_train = pd.read_csv(train_url)
df_val = pd.read_csv(test_url)
def prep_data(df):
n, p = df.shape[0], df.shape[1] - 1
y = torch.tensor(df["label"].values)
X = df.drop(["label"], axis = 1)
X = torch.tensor(X.values)
X = torch.reshape(X, (n, 1, 28, 28))
X = X / 255
# important: move the data to GPU if available
X, y = X.to(device), y.to(device)
return X, y
X_train, y_train = prep_data(df_train)
X_val, y_val = prep_data(df_val)Like last time, our data is essentially a big stack of images:
X_train.size() # (num_images, num_color_channels, num_vertical_pixels, num_horizontal_pixels)torch.Size([27455, 1, 28, 28])Here are a few excerpts from the data.
ALPHABET = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
def show_images(X, y, rows, cols, channel = 0):
fig, axarr = plt.subplots(rows, cols, figsize = (2*cols, 2*rows))
for i, ax in enumerate(axarr.ravel()):
ax.imshow(X[i, channel].detach().cpu(), cmap = "Greys_r")
ax.set(title = f"{ALPHABET[y[i]]}")
ax.axis("off")
plt.tight_layout()
show_images(X_train, y_train, 5, 5)
Data Loaders
A data loader is an iterator that allows us to retrieve small pieces (“batches”) of the data set. This is very convenient for stochastic gradient descent – we get the piece of the data that we want, compute the loss, compute the gradients, take an optimization step, and then get the next piece of data. Let’s put both our training and validation sets into data loaders.
data_loader_train = torch.utils.data.DataLoader(
torch.utils.data.TensorDataset(X_train, y_train),
batch_size = 32,
shuffle = True
)
data_loader_val = torch.utils.data.DataLoader(
torch.utils.data.TensorDataset(X_val, y_val),
batch_size = 32,
shuffle = True
)Here’s an example of retrieving a batch of training data from the training data loader:
X, y = next(iter(data_loader_train))
print(X.size(), y.size())torch.Size([32, 1, 28, 28]) torch.Size([32])We most frequently work with data loaders via loops:
for X, y in data_loader_train:
#...An additional benefit of data loaders is that they can perform arbitrary operations in order to return data batches, including reading files from disk. So, if your overall data set is too large to hold in memory, you can write a custom data loader that reads in a batch of files, operates on them in some way, and returns the result to you as a tensor.
Interlude: Multiclass Classification
We’re actually now making our first formal study of a multiclass classification problem, in which we are trying to distinguish data observations into more than two possible categories. Whereas before we didn’t really comment on the specific structure of this problem, here we need to build up a model from scratch and therefore need to understand how it works!
Typically, classification models return a score for each class. Then, the class with the highest score is usually considered to be the model’s prediction. This means that the score function should actually return a vector of scores for each data observation.
In order to make this happen for a single-layer model, we move from a matrix-vector multiplication \(\mathbf{X}\mathbf{w}\) to a matrix-matrix multiplication \(\mathbf{X}\mathbf{W}\), where \(\mathbf{W} \in \mathbb{R}^{p \times r}\) has number of rows equal to the number of features and number of columns equal to the number of classes.
More generally, we can define our model in any way we like, as long as it returns a vector of scores for each data observation.
It is also necessary to modify the loss function for classification models. Instead of the binary cross entropy, we need to define a multiclass generalization. The most common choice of per-observation loss function between a vector of class scores \(\mathbf{s} \in \mathbb{R}^r\) and the true label \(y_i\) is
\[ \ell(\mathbf{s}_i, y_i) = \sum_{j = 1}^r \mathbb{1}[y_i = j]\log\left(\frac{e^{s_{ij}}}{\sum_{k = 1}^r e^{s_{ik}}}\right) \]
The function
\[ \mathrm{softmax}(\mathbf{s}) = \left(\begin{matrix} \frac{e^{s_1}}{\sum_{j = 1}^r e^{s_j}} \\ \frac{e^{s_2}}{\sum_{j = 1}^r e^{s_j}} \\ \vdots \\ \frac{e^{s_r}}{\sum_{j = 1}^r e^{s_j}} \end{matrix}\right) \]
is a generalization of the logistic sigmoid function to the multiclass setting. It is called the softmax function because it has a tendency to accentuate the largest value in the vector \(\mathbf{s}\). With this notation, we can write the cross-entropy loss as
\[ \ell(\mathbf{s}_i, y_i) = \sum_{j = 1}^r \mathbb{1}[y_i = j]\log \mathrm{softmax}(\mathbf{s}_i)_j\;. \]
Summing the per-observation loss over all data points gives the empirical risk to be minimized.
A First Linear Model
Let’s implement a linear model with the multiclass cross entropy. This first model is equivalent to multiclass logistic regression.
class LinearModel(nn.Module):
def __init__(self):
super().__init__()
self.pipeline = nn.Sequential(
nn.Flatten(),
nn.Linear(28*28, 26)
)
# this is the customary name for the method that computes the scores
# the loss is usually computed outside the model class during the training loop
def forward(self, x):
return self.pipeline(x)
model = LinearModel().to(device)The forward method computes a matrix of scores. Each row of this matrix gives the scores for a single observation:
scores = model(X_train)
scorestensor([[ 0.5114, 0.2543, -0.0080, ..., -0.6141, 0.5227, -0.6885],
[ 0.4821, 0.3830, -0.0839, ..., -0.7075, 0.4926, -0.6881],
[ 0.4608, 0.2377, -0.1621, ..., -0.6940, 0.6233, -0.7923],
...,
[ 0.4388, 0.4027, -0.0278, ..., -0.7697, 0.5440, -0.7831],
[ 0.6288, 0.4988, -0.0415, ..., -0.9567, 0.4030, -0.8334],
[ 0.6108, 0.5235, -0.0693, ..., -0.7299, 0.6004, -0.7167]],
device='cuda:0', grad_fn=<AddmmBackward0>)It’s very useful to get in the habit of inspecting your models in order to understand how they are organized and how many parameters need to be trained. One convenient way to do this is with the summary function provided by the torchsummary package. This function requires that we input the dimensions of a single observation:
summary(model, input_size=(1, 28, 28))----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Flatten-1 [-1, 784] 0
Linear-2 [-1, 26] 20,410
================================================================
Total params: 20,410
Trainable params: 20,410
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.01
Params size (MB): 0.08
Estimated Total Size (MB): 0.09
----------------------------------------------------------------Even this simple multiclass logistic model has over 20,000 parameters to train! Note that the output shape matches the number of possible class labels in the data.
Before we start training, let’s implement a function to evaluate the model in accuracy.
def accuracy(model, data_loader = data_loader_val, multichannel = False, print_message = True):
# count the number of total observations and correct predictions
total = 0
total_correct = 0
# loop through the data loader
for X, y in data_loader:
# used for evaluating ImageNet later
if multichannel:
X = torch.tile(X, dims = (1, 3, 1, 1))
# move the data to the device (ideally, to gpu)
X, y = X.to(device), y.to(device)
# compute the predictions
scores = model(X)
y_pred = torch.argmax(scores, dim = 1)
# update the total and the number of correct predictions
total += X.size(0)
total_correct += (y_pred == y).sum().item()
acc = total_correct / total
return accaccuracy(model)0.052844394868934746Obviously our model does not do very well on the validation data, since it’s not trained yet.
Let’s therefore implement a simple training loop. This loop will include provisions to train the model while also calling the previous function to update us on the accuracy on the validation set. We’ll also measure the loss on the training and validation sets after each epoch and return those for plotting.
def train(model, k_epochs = 1, print_every = 2000, multichannel = False, plot_accuracy = True, **opt_kwargs):
# loss function is cross-entropy (multiclass logistic)
loss_fn = nn.CrossEntropyLoss()
# optimizer is SGD with momentum
optimizer = optim.SGD(model.parameters(), **opt_kwargs)
if plot_accuracy:
val_accuracy = []
train_accuracy = []
for epoch in range(k_epochs):
for i, data in enumerate(data_loader_train):
X, y = data
if multichannel:
X = torch.tile(X, dims = (1, 3, 1, 1))
X, y = X.to(device), y.to(device)
# clear any accumulated gradients
optimizer.zero_grad()
# compute the loss
y_pred = model(X)
loss = loss_fn(y_pred, y)
# compute gradients and carry out an optimization step
loss.backward()
optimizer.step()
train_accuracy += [accuracy(model, data_loader = data_loader_train, multichannel = multichannel, print_message = False)]
val_accuracy += [accuracy(model, multichannel = multichannel, print_message = False)]
return train_accuracy, val_accuracyNow we can go ahead and train our model.
train_accuracy, val_accuracy = train(model, k_epochs = 30, lr = 0.001)
plt.plot(train_accuracy, color = "black", label = "Training")
plt.plot(val_accuracy, color = "firebrick", label = "Validation")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.gca().set(ylim = (0, 1))
l = plt.legend()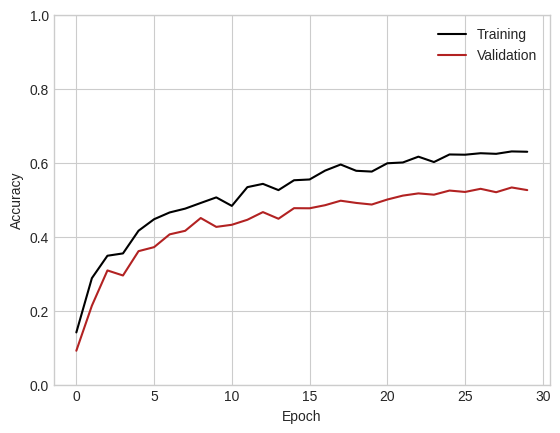
This model is able to achieve accuracy much better than random chance, and would likely improve even more if we allowed it more training epochs.
Convolutional Models
Our favorite logistic regression is a great algorithm, but there is lots of room to improve! Last time we studied this data set, we used convolutional kernels extract more helpful features from the data before finally plugging those features into a logistic regression model. Convolutional kernels offer structured transformations that can accentuate certain features of images:

Image from Dive Into Deep Learning
We sandwiched those convolutional layers between pooling and ReLU activation layers. This time, instead of treating these kernels as given, we are going to learn them as part of the optimization routine.
Starting from this point in the notes, it is strongly recommended to run this code with a GPU available, such as in Google Colab.
import torch.nn as nn
from torch.nn import ReLU
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
self.pipeline = torch.nn.Sequential(
nn.Conv2d(1, 100, 5),
ReLU(),
nn.Conv2d(100, 50, 3),
ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(50, 50, 3),
ReLU(),
nn.Conv2d(50, 50, 3),
ReLU(),
nn.MaxPool2d(2, 2),
nn.Flatten(),
nn.Linear(450, 512),
ReLU(),
nn.Linear(512, 128),
ReLU(),
nn.Linear(128, len(ALPHABET))
)
def forward(self, x):
return self.pipeline(x)
model = ConvNet().to(device)What does this model look like?
summary(model, input_size=(1, 28, 28))----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 100, 24, 24] 2,600
ReLU-2 [-1, 100, 24, 24] 0
Conv2d-3 [-1, 50, 22, 22] 45,050
ReLU-4 [-1, 50, 22, 22] 0
MaxPool2d-5 [-1, 50, 11, 11] 0
Conv2d-6 [-1, 50, 9, 9] 22,550
ReLU-7 [-1, 50, 9, 9] 0
Conv2d-8 [-1, 50, 7, 7] 22,550
ReLU-9 [-1, 50, 7, 7] 0
MaxPool2d-10 [-1, 50, 3, 3] 0
Flatten-11 [-1, 450] 0
Linear-12 [-1, 512] 230,912
ReLU-13 [-1, 512] 0
Linear-14 [-1, 128] 65,664
ReLU-15 [-1, 128] 0
Linear-16 [-1, 26] 3,354
================================================================
Total params: 392,680
Trainable params: 392,680
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 1.41
Params size (MB): 1.50
Estimated Total Size (MB): 2.91
----------------------------------------------------------------This model has (many) more parameters than the logistic regression model. The increased depth, as well as the use of convolutional layers, give it potential to usefully leverage the spatial structure of the predictor data.
Let’s see how it does! Note that the following experiment may not be reproducible; nonconvexity of the empirical risk means that the results we achieve may depend strongly on the initial guess for the parameters used by the optimizer.
train_accuracy, val_accuracy = train(model, k_epochs = 5, lr = 0.01, momentum = 0.9)
plt.plot(train_accuracy, color = "black", label = "Training")
plt.plot(val_accuracy, color = "firebrick", label = "Validation")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.gca().set(ylim = (0, 1))
l = plt.legend()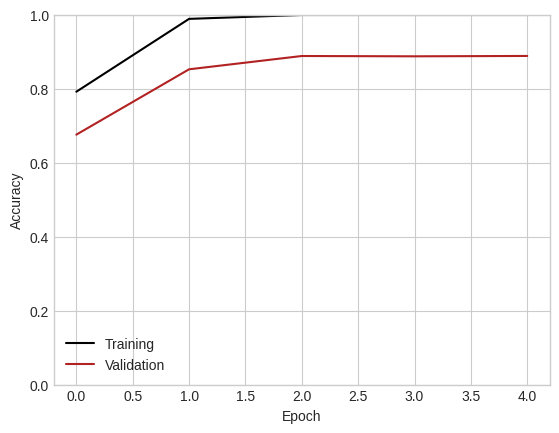
Although this model takes much longer to complete a single epoch, it is also able to achieve much higher validation accuracy than the pure logistic regression model (which, as you’ll recall from our previous work on this data set, leveled out around 67%).
Transfer Learning
Transfer learning is a fancy phrase describing the simple technique of using a pre-existing model and tweaking it slightly to be suitable for your task. This is most frequently done with largescale models that couldn’t practically be fully trained on the available computing power. The theory is that a large, powerful model for e.g. image classification on some general image classification data set may have learned a useful set of hidden features that may have generic utility for other image classification tasks.
Let’s use ImageNet, a well-known class of models trained for image classification tasks. torch.models allows you to easily create an instance of an ImageNet model:
model = models.resnet18(weights='IMAGENET1K_V1')Let’s take a look at the structure of this model. Note that the input shape is (3, 28, 28) because ImageNet is trained on color images with three RGB color channels.
INPUT_SHAPE = (3, 28, 28)
model = model.to(device)
summary(model, INPUT_SHAPE)----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 14, 14] 9,408
BatchNorm2d-2 [-1, 64, 14, 14] 128
ReLU-3 [-1, 64, 14, 14] 0
MaxPool2d-4 [-1, 64, 7, 7] 0
Conv2d-5 [-1, 64, 7, 7] 36,864
BatchNorm2d-6 [-1, 64, 7, 7] 128
ReLU-7 [-1, 64, 7, 7] 0
Conv2d-8 [-1, 64, 7, 7] 36,864
BatchNorm2d-9 [-1, 64, 7, 7] 128
ReLU-10 [-1, 64, 7, 7] 0
BasicBlock-11 [-1, 64, 7, 7] 0
Conv2d-12 [-1, 64, 7, 7] 36,864
BatchNorm2d-13 [-1, 64, 7, 7] 128
ReLU-14 [-1, 64, 7, 7] 0
Conv2d-15 [-1, 64, 7, 7] 36,864
BatchNorm2d-16 [-1, 64, 7, 7] 128
ReLU-17 [-1, 64, 7, 7] 0
BasicBlock-18 [-1, 64, 7, 7] 0
Conv2d-19 [-1, 128, 4, 4] 73,728
BatchNorm2d-20 [-1, 128, 4, 4] 256
ReLU-21 [-1, 128, 4, 4] 0
Conv2d-22 [-1, 128, 4, 4] 147,456
BatchNorm2d-23 [-1, 128, 4, 4] 256
Conv2d-24 [-1, 128, 4, 4] 8,192
BatchNorm2d-25 [-1, 128, 4, 4] 256
ReLU-26 [-1, 128, 4, 4] 0
BasicBlock-27 [-1, 128, 4, 4] 0
Conv2d-28 [-1, 128, 4, 4] 147,456
BatchNorm2d-29 [-1, 128, 4, 4] 256
ReLU-30 [-1, 128, 4, 4] 0
Conv2d-31 [-1, 128, 4, 4] 147,456
BatchNorm2d-32 [-1, 128, 4, 4] 256
ReLU-33 [-1, 128, 4, 4] 0
BasicBlock-34 [-1, 128, 4, 4] 0
Conv2d-35 [-1, 256, 2, 2] 294,912
BatchNorm2d-36 [-1, 256, 2, 2] 512
ReLU-37 [-1, 256, 2, 2] 0
Conv2d-38 [-1, 256, 2, 2] 589,824
BatchNorm2d-39 [-1, 256, 2, 2] 512
Conv2d-40 [-1, 256, 2, 2] 32,768
BatchNorm2d-41 [-1, 256, 2, 2] 512
ReLU-42 [-1, 256, 2, 2] 0
BasicBlock-43 [-1, 256, 2, 2] 0
Conv2d-44 [-1, 256, 2, 2] 589,824
BatchNorm2d-45 [-1, 256, 2, 2] 512
ReLU-46 [-1, 256, 2, 2] 0
Conv2d-47 [-1, 256, 2, 2] 589,824
BatchNorm2d-48 [-1, 256, 2, 2] 512
ReLU-49 [-1, 256, 2, 2] 0
BasicBlock-50 [-1, 256, 2, 2] 0
Conv2d-51 [-1, 512, 1, 1] 1,179,648
BatchNorm2d-52 [-1, 512, 1, 1] 1,024
ReLU-53 [-1, 512, 1, 1] 0
Conv2d-54 [-1, 512, 1, 1] 2,359,296
BatchNorm2d-55 [-1, 512, 1, 1] 1,024
Conv2d-56 [-1, 512, 1, 1] 131,072
BatchNorm2d-57 [-1, 512, 1, 1] 1,024
ReLU-58 [-1, 512, 1, 1] 0
BasicBlock-59 [-1, 512, 1, 1] 0
Conv2d-60 [-1, 512, 1, 1] 2,359,296
BatchNorm2d-61 [-1, 512, 1, 1] 1,024
ReLU-62 [-1, 512, 1, 1] 0
Conv2d-63 [-1, 512, 1, 1] 2,359,296
BatchNorm2d-64 [-1, 512, 1, 1] 1,024
ReLU-65 [-1, 512, 1, 1] 0
BasicBlock-66 [-1, 512, 1, 1] 0
AdaptiveAvgPool2d-67 [-1, 512, 1, 1] 0
Linear-68 [-1, 1000] 513,000
================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 1.10
Params size (MB): 44.59
Estimated Total Size (MB): 45.70
----------------------------------------------------------------You may notice a problem: this model is trained to classify images into one of 1000 categories, but we only have 26! This means that we need to modify the output layer. Fortunately, this is not hard to do. The output layer in ImageNet has name fc, and we can simply swap it out for a different output layer with the correct number of outputs.
model.fc = nn.Linear(model.fc.in_features, 26)If we check our model again, we’ll see that we now have the right number of outputs:
model = model.to(device)
summary(model, INPUT_SHAPE)----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 14, 14] 9,408
BatchNorm2d-2 [-1, 64, 14, 14] 128
ReLU-3 [-1, 64, 14, 14] 0
MaxPool2d-4 [-1, 64, 7, 7] 0
Conv2d-5 [-1, 64, 7, 7] 36,864
BatchNorm2d-6 [-1, 64, 7, 7] 128
ReLU-7 [-1, 64, 7, 7] 0
Conv2d-8 [-1, 64, 7, 7] 36,864
BatchNorm2d-9 [-1, 64, 7, 7] 128
ReLU-10 [-1, 64, 7, 7] 0
BasicBlock-11 [-1, 64, 7, 7] 0
Conv2d-12 [-1, 64, 7, 7] 36,864
BatchNorm2d-13 [-1, 64, 7, 7] 128
ReLU-14 [-1, 64, 7, 7] 0
Conv2d-15 [-1, 64, 7, 7] 36,864
BatchNorm2d-16 [-1, 64, 7, 7] 128
ReLU-17 [-1, 64, 7, 7] 0
BasicBlock-18 [-1, 64, 7, 7] 0
Conv2d-19 [-1, 128, 4, 4] 73,728
BatchNorm2d-20 [-1, 128, 4, 4] 256
ReLU-21 [-1, 128, 4, 4] 0
Conv2d-22 [-1, 128, 4, 4] 147,456
BatchNorm2d-23 [-1, 128, 4, 4] 256
Conv2d-24 [-1, 128, 4, 4] 8,192
BatchNorm2d-25 [-1, 128, 4, 4] 256
ReLU-26 [-1, 128, 4, 4] 0
BasicBlock-27 [-1, 128, 4, 4] 0
Conv2d-28 [-1, 128, 4, 4] 147,456
BatchNorm2d-29 [-1, 128, 4, 4] 256
ReLU-30 [-1, 128, 4, 4] 0
Conv2d-31 [-1, 128, 4, 4] 147,456
BatchNorm2d-32 [-1, 128, 4, 4] 256
ReLU-33 [-1, 128, 4, 4] 0
BasicBlock-34 [-1, 128, 4, 4] 0
Conv2d-35 [-1, 256, 2, 2] 294,912
BatchNorm2d-36 [-1, 256, 2, 2] 512
ReLU-37 [-1, 256, 2, 2] 0
Conv2d-38 [-1, 256, 2, 2] 589,824
BatchNorm2d-39 [-1, 256, 2, 2] 512
Conv2d-40 [-1, 256, 2, 2] 32,768
BatchNorm2d-41 [-1, 256, 2, 2] 512
ReLU-42 [-1, 256, 2, 2] 0
BasicBlock-43 [-1, 256, 2, 2] 0
Conv2d-44 [-1, 256, 2, 2] 589,824
BatchNorm2d-45 [-1, 256, 2, 2] 512
ReLU-46 [-1, 256, 2, 2] 0
Conv2d-47 [-1, 256, 2, 2] 589,824
BatchNorm2d-48 [-1, 256, 2, 2] 512
ReLU-49 [-1, 256, 2, 2] 0
BasicBlock-50 [-1, 256, 2, 2] 0
Conv2d-51 [-1, 512, 1, 1] 1,179,648
BatchNorm2d-52 [-1, 512, 1, 1] 1,024
ReLU-53 [-1, 512, 1, 1] 0
Conv2d-54 [-1, 512, 1, 1] 2,359,296
BatchNorm2d-55 [-1, 512, 1, 1] 1,024
Conv2d-56 [-1, 512, 1, 1] 131,072
BatchNorm2d-57 [-1, 512, 1, 1] 1,024
ReLU-58 [-1, 512, 1, 1] 0
BasicBlock-59 [-1, 512, 1, 1] 0
Conv2d-60 [-1, 512, 1, 1] 2,359,296
BatchNorm2d-61 [-1, 512, 1, 1] 1,024
ReLU-62 [-1, 512, 1, 1] 0
Conv2d-63 [-1, 512, 1, 1] 2,359,296
BatchNorm2d-64 [-1, 512, 1, 1] 1,024
ReLU-65 [-1, 512, 1, 1] 0
BasicBlock-66 [-1, 512, 1, 1] 0
AdaptiveAvgPool2d-67 [-1, 512, 1, 1] 0
Linear-68 [-1, 26] 13,338
================================================================
Total params: 11,189,850
Trainable params: 11,189,850
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 1.09
Params size (MB): 42.69
Estimated Total Size (MB): 43.78
----------------------------------------------------------------Now we are ready to train our adapted ImageNet model for our task. Let’s see how we do in just two epochs:
train_accuracy, val_accuracy = train(model, k_epochs = 2, lr = 0.01, multichannel = True, momentum = 0.9)
print(f"Validation accuracy: {val_accuracy[-1]:.2f}")Validation accuracy: 0.97After just two epochs, we have achieved much higher accuracy on our sign-language classification task than we achieved using any of our previous methods. This is because ImageNet is a much more expressive model with a complex architecture and a higher parameter count. Fortunately, however, we didn’t have to fully train the model from scratch; we were able to just tweak the model a little bit to customize it for our specific task.
There is another variant of transfer learning in which we fix the parameters at the base layers and then only train the parameters in the output layer. This approach can be effective and can be quick to train, but also may perform worse than approaches that modify all the model parameters. We can implement this approach by first downloading a “clean” version of ImageNet. Then, we’ll set the requires_grad attribute of each parameter tensor to False; this will cause these layers not to be updated during optimization. This approach is often called fine-tuning.
model = models.resnet18(weights ='IMAGENET1K_V1')
# no gradients for any of the model parameters, so no updates
for param in model.parameters():
param.requires_grad = False
# Parameters of newly constructed modules have requires_grad=True by default
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 26)
model = model.to(device)summary(model, INPUT_SHAPE)----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 14, 14] 9,408
BatchNorm2d-2 [-1, 64, 14, 14] 128
ReLU-3 [-1, 64, 14, 14] 0
MaxPool2d-4 [-1, 64, 7, 7] 0
Conv2d-5 [-1, 64, 7, 7] 36,864
BatchNorm2d-6 [-1, 64, 7, 7] 128
ReLU-7 [-1, 64, 7, 7] 0
Conv2d-8 [-1, 64, 7, 7] 36,864
BatchNorm2d-9 [-1, 64, 7, 7] 128
ReLU-10 [-1, 64, 7, 7] 0
BasicBlock-11 [-1, 64, 7, 7] 0
Conv2d-12 [-1, 64, 7, 7] 36,864
BatchNorm2d-13 [-1, 64, 7, 7] 128
ReLU-14 [-1, 64, 7, 7] 0
Conv2d-15 [-1, 64, 7, 7] 36,864
BatchNorm2d-16 [-1, 64, 7, 7] 128
ReLU-17 [-1, 64, 7, 7] 0
BasicBlock-18 [-1, 64, 7, 7] 0
Conv2d-19 [-1, 128, 4, 4] 73,728
BatchNorm2d-20 [-1, 128, 4, 4] 256
ReLU-21 [-1, 128, 4, 4] 0
Conv2d-22 [-1, 128, 4, 4] 147,456
BatchNorm2d-23 [-1, 128, 4, 4] 256
Conv2d-24 [-1, 128, 4, 4] 8,192
BatchNorm2d-25 [-1, 128, 4, 4] 256
ReLU-26 [-1, 128, 4, 4] 0
BasicBlock-27 [-1, 128, 4, 4] 0
Conv2d-28 [-1, 128, 4, 4] 147,456
BatchNorm2d-29 [-1, 128, 4, 4] 256
ReLU-30 [-1, 128, 4, 4] 0
Conv2d-31 [-1, 128, 4, 4] 147,456
BatchNorm2d-32 [-1, 128, 4, 4] 256
ReLU-33 [-1, 128, 4, 4] 0
BasicBlock-34 [-1, 128, 4, 4] 0
Conv2d-35 [-1, 256, 2, 2] 294,912
BatchNorm2d-36 [-1, 256, 2, 2] 512
ReLU-37 [-1, 256, 2, 2] 0
Conv2d-38 [-1, 256, 2, 2] 589,824
BatchNorm2d-39 [-1, 256, 2, 2] 512
Conv2d-40 [-1, 256, 2, 2] 32,768
BatchNorm2d-41 [-1, 256, 2, 2] 512
ReLU-42 [-1, 256, 2, 2] 0
BasicBlock-43 [-1, 256, 2, 2] 0
Conv2d-44 [-1, 256, 2, 2] 589,824
BatchNorm2d-45 [-1, 256, 2, 2] 512
ReLU-46 [-1, 256, 2, 2] 0
Conv2d-47 [-1, 256, 2, 2] 589,824
BatchNorm2d-48 [-1, 256, 2, 2] 512
ReLU-49 [-1, 256, 2, 2] 0
BasicBlock-50 [-1, 256, 2, 2] 0
Conv2d-51 [-1, 512, 1, 1] 1,179,648
BatchNorm2d-52 [-1, 512, 1, 1] 1,024
ReLU-53 [-1, 512, 1, 1] 0
Conv2d-54 [-1, 512, 1, 1] 2,359,296
BatchNorm2d-55 [-1, 512, 1, 1] 1,024
Conv2d-56 [-1, 512, 1, 1] 131,072
BatchNorm2d-57 [-1, 512, 1, 1] 1,024
ReLU-58 [-1, 512, 1, 1] 0
BasicBlock-59 [-1, 512, 1, 1] 0
Conv2d-60 [-1, 512, 1, 1] 2,359,296
BatchNorm2d-61 [-1, 512, 1, 1] 1,024
ReLU-62 [-1, 512, 1, 1] 0
Conv2d-63 [-1, 512, 1, 1] 2,359,296
BatchNorm2d-64 [-1, 512, 1, 1] 1,024
ReLU-65 [-1, 512, 1, 1] 0
BasicBlock-66 [-1, 512, 1, 1] 0
AdaptiveAvgPool2d-67 [-1, 512, 1, 1] 0
Linear-68 [-1, 26] 13,338
================================================================
Total params: 11,189,850
Trainable params: 13,338
Non-trainable params: 11,176,512
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 1.09
Params size (MB): 42.69
Estimated Total Size (MB): 43.78
----------------------------------------------------------------Note that, although we have the same number of parameters as before, the number of trainable parameters is much smaller. This leads to somewhat faster training, albeit with much less impressive results in the validation set. Fine-tuning the final several layers, rather than just the single output layer, may lead to improved performance.
train_accuracy, val_accuracy = train(model, k_epochs = 5, lr = 0.01, multichannel = True, momentum = 0.9)
print(f"Validation accuracy: {val_accuracy[-1]:.2f}")Validation accuracy: 0.49Other Considerations
We’ll highlight two practical considerations that frequently come up when working with image classification models.
Data Augmentation
One very standard technique for improving the ability of image classification models to generalize is to perform data augmentation. Data augmentation creates “new” data by applying simple transformations to the input images. For example, one kind of data augmentation is to rotate the image by a small amount.
.
You can learn more about Torch’s data augmentation capabilities in the documentation
Here is an example of applying a data augmentation pipeline to an image. The result is a sequence of new images, which would be reasonably expected to have the same true class label as the original.
from torchvision.transforms import v2
transforms = v2.Compose([
v2.RandomResizedCrop(size=(24, 24), antialias=True),
v2.RandomHorizontalFlip(p=0.5)
])
cols = 5
rows = 2
ix = 0
fig, axarr = plt.subplots(rows, cols, figsize = (2*cols, 2*rows))
for i, ax in enumerate(axarr.ravel()):
transformed = transforms(X_train[ix])
ax.imshow(transformed.detach().cpu()[0], cmap = "Greys_r")
ax.axis("off")
plt.tight_layout()
Incorporating these “new” images as part of the training set could potentially allow models to learn more complex patterns, including the idea that an image which has been flipped or rotated is still representative of the same concept.
Data Loaders from Directories
As mentioned above, it can be very helpful to use data loaders to manage the process of reading in data and passing it to your model. This is especially helpful in the case that your data set is too large to fit in RAM; the data loader can read the data from disk and pass it to the model, without ever needing to fit the entirety of data in RAM. You can learn much more about how Torch manages data sets and data loaders in the docs.
© Phil Chodrow, 2025