Last time, we considered the problem of learning a classification model via gradient descent to solve an empirical risk minimization problem. We assumed that we had data, a pair \((\mathbf{X}, \mathbf{y})\) where
\(\mathbf{X} \in \mathbb{R}^{n\times p}\) is the feature matrix. There are \(n\) distinct observations, encoded as rows. Each of the \(p\) columns corresponds to a feature: something about each observation that we can measure or infer. Each observation is written \(\mathbf{x}_1, \mathbf{x}_2,\ldots\). \[
\mathbf{X} = \left[\begin{matrix} & - & \mathbf{x}_1 & - \\
& - & \mathbf{x}_2 & - \\
& \vdots & \vdots & \vdots \\
& - & \mathbf{x}_{n} & - \end{matrix}\right]
\]
\(\mathbf{y}\in \mathbb{R}^{n}\) is the target vector. The target vector gives a label, value, or outcome for each observation.
Using this data, we defined the empirical risk minimization problem, which had the general form \[
\hat{\mathbf{w}} = \mathop{\mathrm{argmin\;}}_{\mathbf{w}} \; L(\mathbf{w})\;,
\tag{11.1}\] where \[
L(\mathbf{w}) = \frac{1}{n} \sum_{i = 1}^n \ell(\langle \mathbf{w}, \mathbf{x}_i \rangle, y_i)\;.
\]
In our last lecture, we studied how to compute the gradient of \(L(\mathbf{w})\) in minimize the empirical risk and find a good value \(\hat{\mathbf{w}}\) for the parameter vector. In this lecture we’re going to assume that we can cheerfully solve the empirical risk minimization for convex linear models.
Nonlinear Decision Boundaries
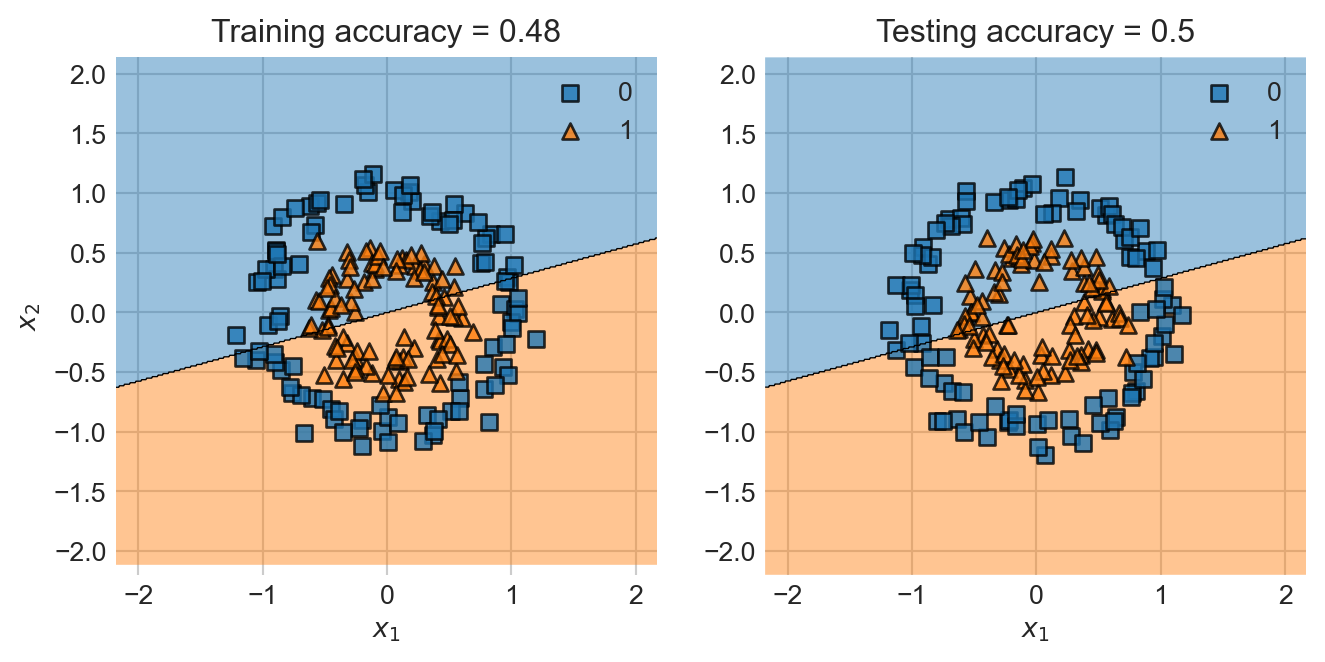
However, we are still working with an important limitation: for a long time now, we’ve focused only on linear decision boundaries. However, most of the data we care about in practice has nonlinear decision boundaries. Here’s a dramatic example. For this example and throughout today, I’m using the implementation of logistic regression from scikit-learn. The purpose is to let you follow along while still giving you the chance to implement your own logistic regression for homework. Toward the end of the notes, I’ll highlight where regularization shows up if you want to implement it in e.g. a torch model. I’m also using the plot_decision_regions function from the mlxtend package, which is a handy plotting utility for visualizing the behavior of our models.
Code
from sklearn.datasets import make_moons, make_circlesfrom mlxtend.plotting import plot_decision_regionsfrom sklearn.linear_model import LogisticRegressionfrom matplotlib import pyplot as pltimport numpy as npdef viz_decision_regions(model, X_train, y_train, X_test, y_test): fig, ax = plt.subplots(1, 2, figsize = (8, 3.5), sharex =True, sharey =True)for i, data inenumerate(["Train", "Test"]): X = [X_train, X_test][i] y = [y_train, y_test][i] plot_decision_regions(X, y, clf = model, ax = ax[i]) score = ax[i].set_title(f"{data}ing accuracy = {model.score(X, y)}") ax[i].set(xlabel =r"$x_1$")if i ==0: ax[i].set(ylabel =r"$x_2$")def plot_weights(plr): coefs = plr.named_steps["LR"].coef_.flatten() frac_zero = np.isclose(coefs, 0).mean() mean_coef = np.abs(coefs).mean() coefs_sorted = np.sort(coefs) plt.scatter(np.arange(len(coefs)), coefs_sorted, s =10, facecolors ="none", edgecolors ="black") plt.gca().set(xlabel ="weight (sorted)", ylabel ="weight value", title =fr"Mean $|w_i|$ = {mean_coef:.2f}, zero weights = {100*frac_zero:.0f}%")
First, let’s create some training and testing data:
Now let’s fit and visualize the the decision regions learned on both the training and test sets.
LR = LogisticRegression()LR.fit(X_train, y_train)viz_decision_regions(LR, X_train, y_train, X_test, y_test)
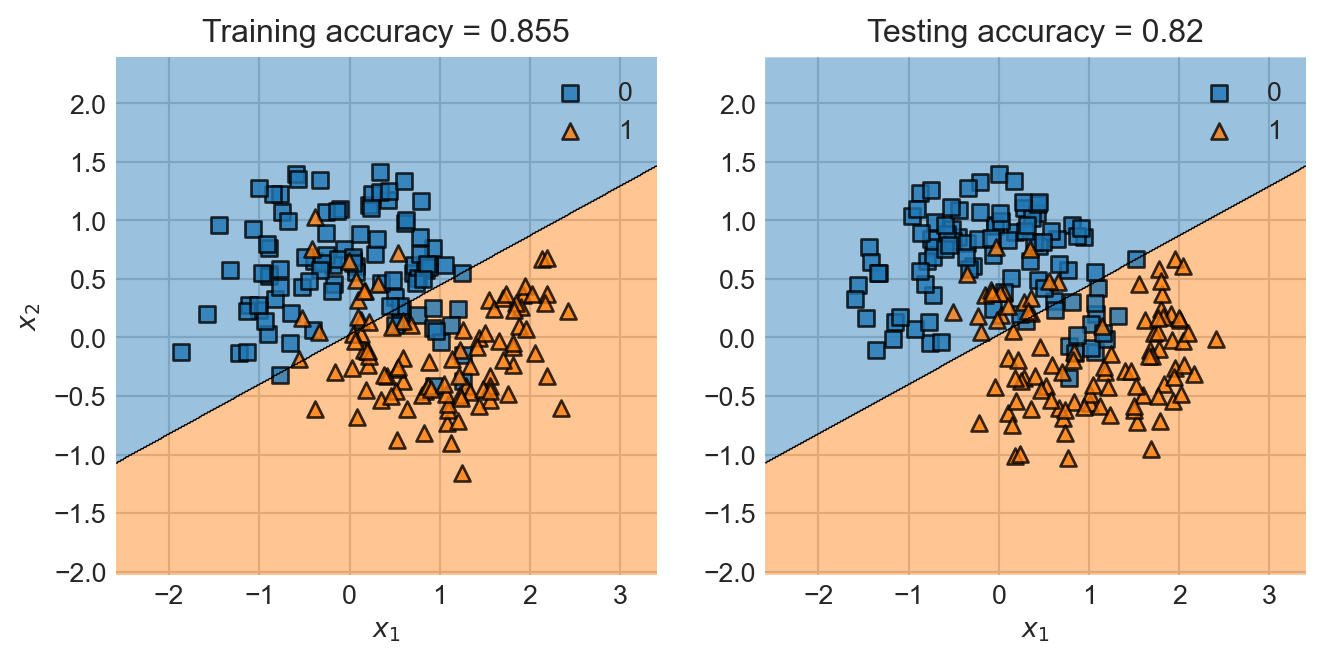
Yikes!
Visually this should be pretty easy data to classify. But the linear decision boundary clearly isn’t the way.
Given a point \(\mathbf{x}\), what information would you find most useful about that point in determining whether it should have label \(0\) or \(1\) based on this training data?
Feature Maps
Suppose that we were able to extract from each point its distance from the origin. In 2d, we could take a point \(\mathbf{x}\) and simply compute
\[
r^2 = x_1^2 + x_2^2\;.
\]
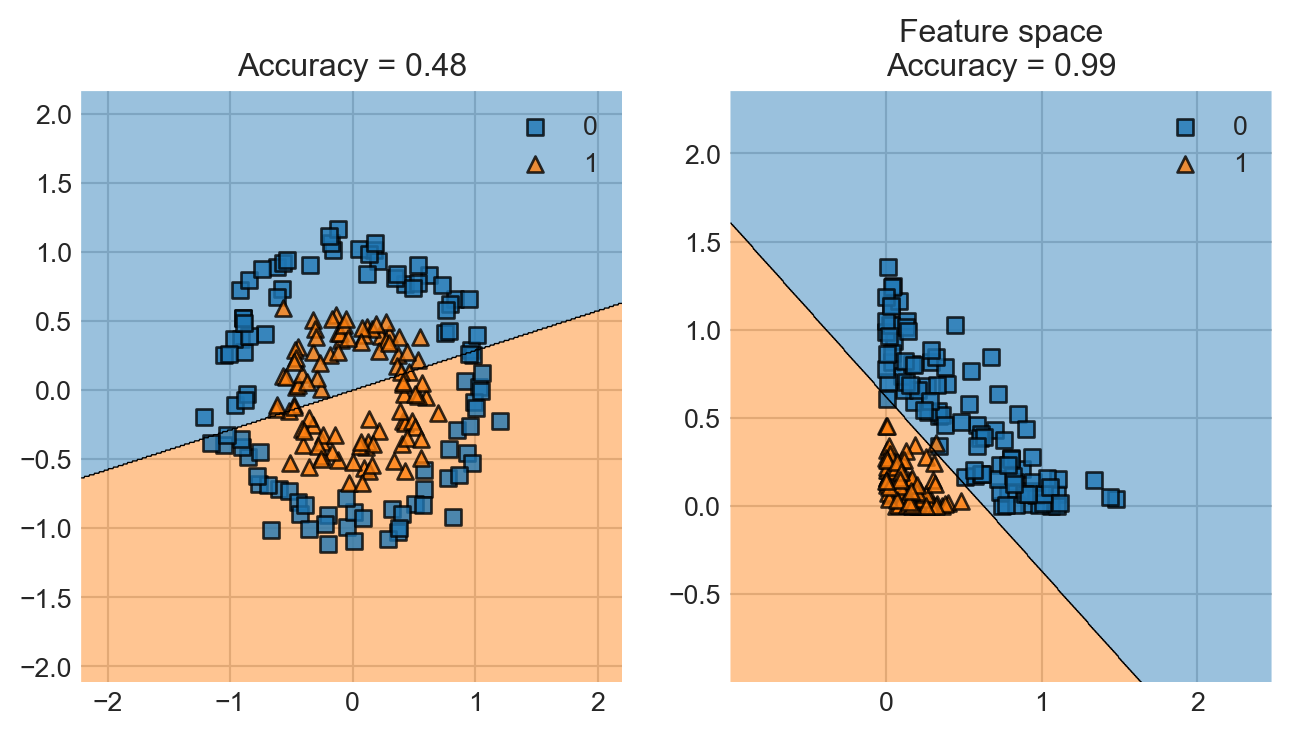
We could then make the classification based on the value of \(r^2\). In this data set, it looks like the classification rule that predicts \(1\) if \(r^2 < 1\) and \(0\) otherwise would be a pretty good one. The important insight here is that this is also a linear model, with linear predictor function
where \(\phi(\mathbf{x}) = (r^2, 1)\) and \(\mathbf{w} = (1, -1)\). We could attempt to find a value of the weight vector close to this one using empirical risk minimization using our standard methods. This means that we can use empirical risk minimization for this problem if we just transform the features \(\mathbf{X}\) first! We need to compute a matrix \(\mathbf{R}\) whose \(i\)th row is \(\mathbf{r}_i = \phi(\mathbf{x}) = (r^2_i, 1) = (x_{i1}^2 + x_{i2}^2, 1)\), and then use this matrix in place of \(\mathbf{X}\) for our classification task.
The transformation \(\phi: (x_1, x_2) \mapsto (x_1^2 + x_2^2, 1)\) is an example of a feature map.
Definition 11.1 Let \(\mathbf{X} \in \mathbb{R}^{n \times q}\). A feature map\(\phi\) is a function \(\phi:\mathbb{R}^q \rightarrow \mathbb{R}^q\), We call \(\phi(\mathbf{x}) in \mathbb{R}^p\) the feature vector corresponding to \(\mathbf{x}\). For a given feature map \(\phi\), we define the map \(\Phi:\mathbb{R}^{n \times q} \rightarrow \mathbb{R}^{n\times p}\) as
We often think of feature maps as taking us from a space in which the data is not linearly separable to a space in which it is (perhaps approximately). For example, consider the feature map
\[
\phi: (x_1, x_2) \mapsto (x_1^2, x_2^2)\;.
\]
This map is sufficient to express the radius information, since we can represent the radius as
Just by fitting the logistic regression model in the feature space, we were able to go from essentially random accuracy to accuracy of nearly 100% on training data.
Feature Maps in Practice
Going back to our example of trying to classify the two nested circles, we could just compute the radius. In practice, however, we don’t really know which features are going to be most useful, and so we just compute a set of features. In our case, the square of the radius is an example of a polynomial of degree 2: \[
r^2 = x_1^2 + x_2^2\;.
\]
Instead of just assuming that the radius is definitely the right thing to compute, we more frequently just compute all the monomials of degree 2 or lower. If \(\mathbf{x} = (x_1, x_2)\), then the vector of all monomials of degree up to 2 is
The important point to keep track of is that the new feature matrix \(\mathbf{X}' = \Phi(\mathbf{X})\) generally has a different number of columns from \(\mathbf{X}\). In this case, for example, \(\mathbf{X}\) had just 2 columns but \(\Phi(\mathbf{X})\) has 6. This means that \(\hat{\mathbf{w}}\) has 6 components, instead of 2!
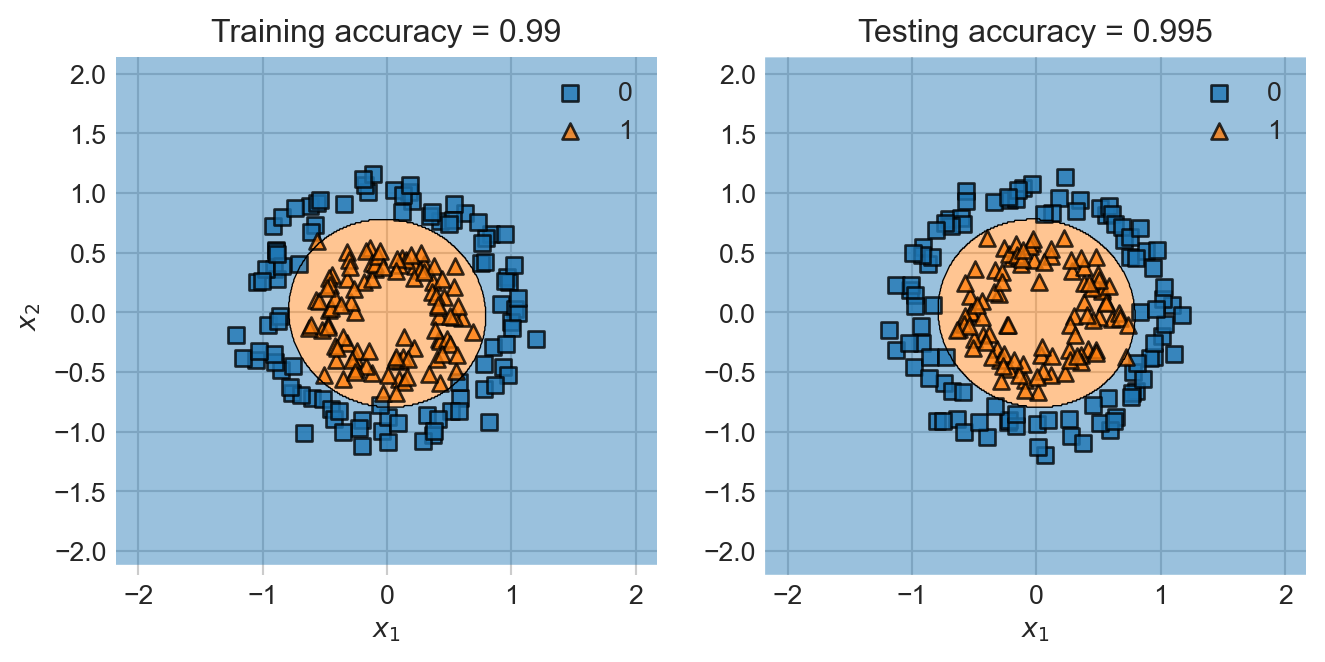
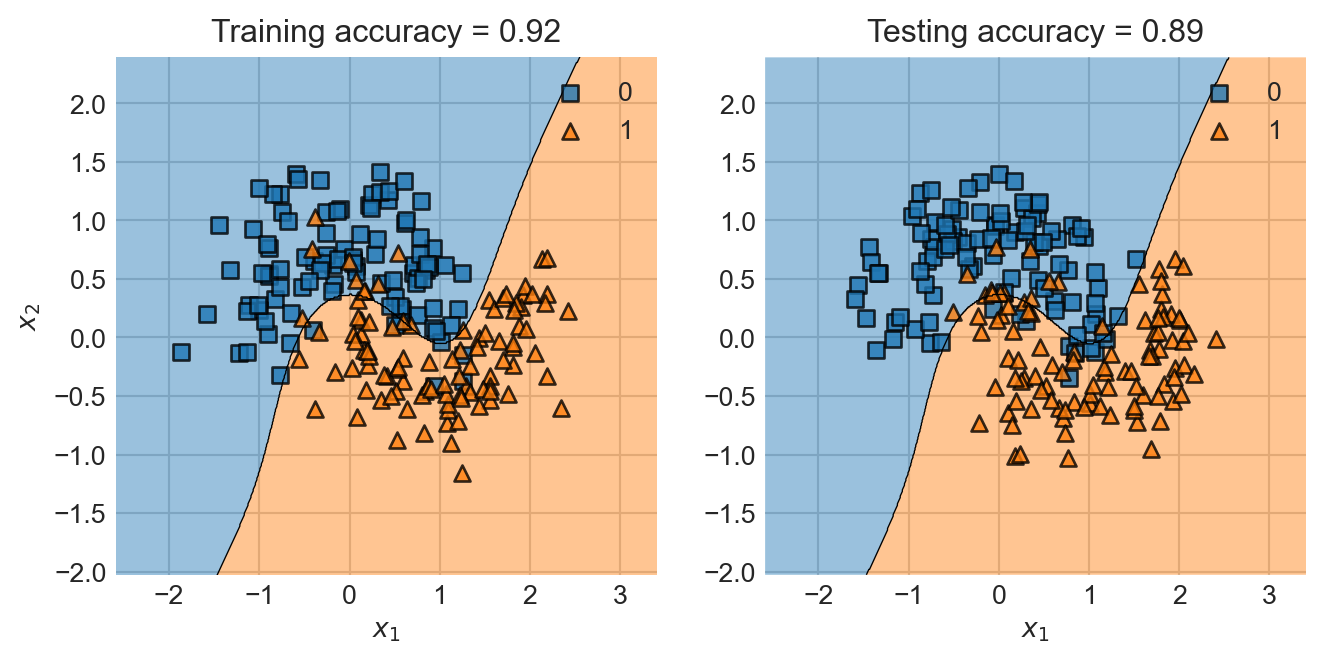
Let’s now run logistic regression with degree-2 polynomial features on this data set. The most convenient way to make this happen in the scikit-learn framework is with at Pipeline. The Pipeline first applies the feature map and then calls the model during both fitting and evaluation. We’ll wrap the pipeline in a simple function for easy reuse.
Notice that two coefficients are much larger in magnitude than the others, and approximately equal. These are the coefficients for the features \(x_1^2\) and \(x_2^2\). The fact that these are approximately equal means that our model is very close to using the square radius \(r^2 = x_1^2 + x_2^2\) as a learned feature for this data, just like we’d expect. The benefit is that we didn’t have to hard-code that in; the model just detected the right pattern to find.
Part of the reason this might be beneficial is that for some data sets, we might not really know what specific features we should try. For example, here’s another one where a linear classifier doesn’t do so great (degree 1 corresponds to no transformation of the features). We’ll keep using this example as we go, and so we’ll generate both a training and a test set.
It’s not as obvious that we should use the radius or any other specific feature for our feature map. Fortunately we don’t need to think too much about it – we can just increase the degree and let the model figure things out:
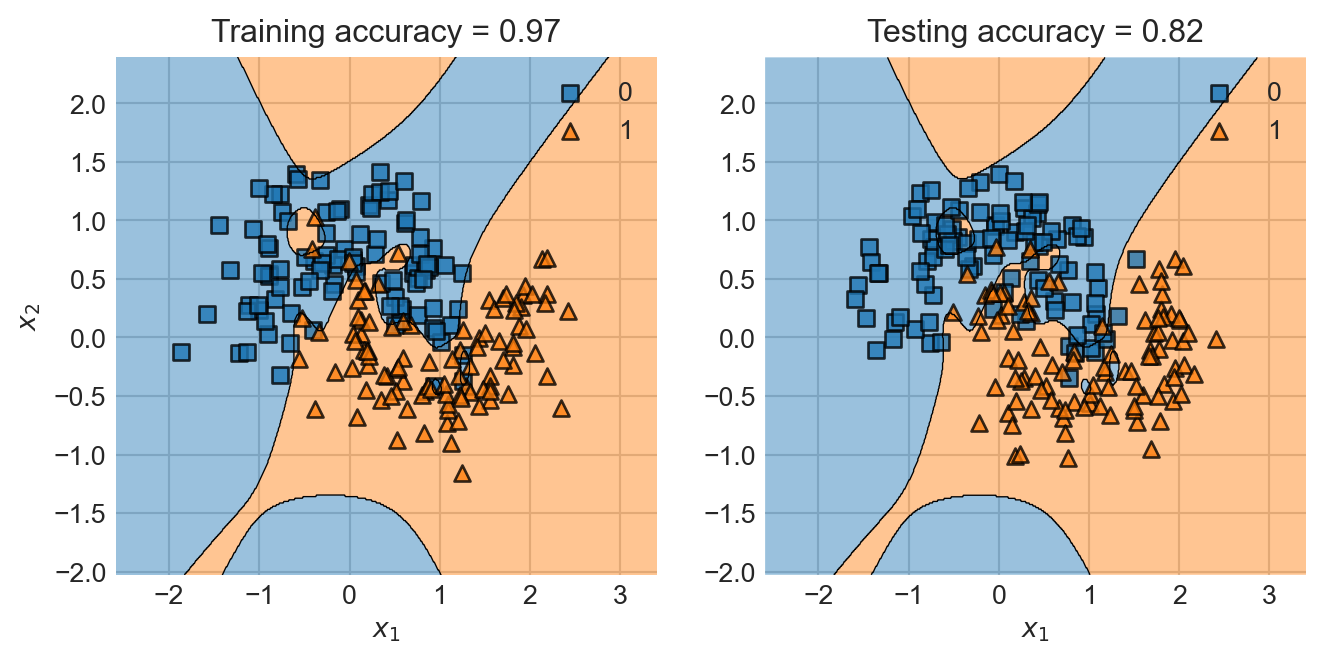
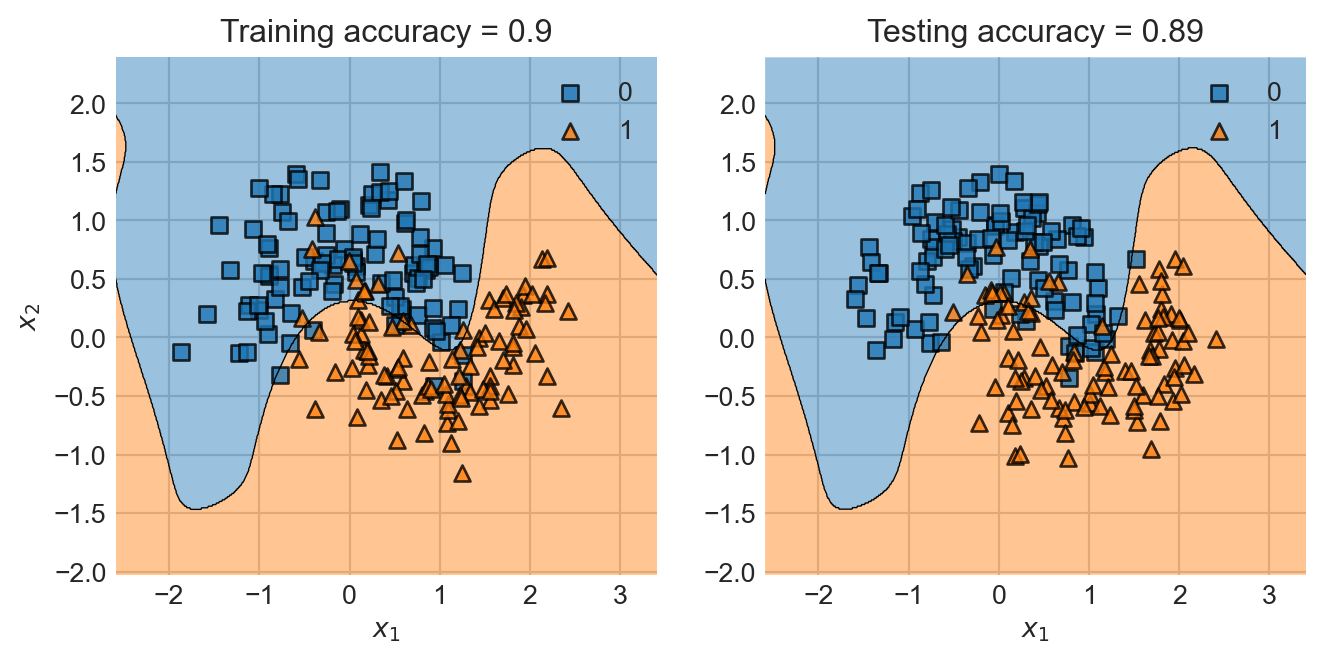
So, why don’t we just use as many features as it takes to get perfect accuracy on the training data? As usual, this would lead to overfitting, as we can observe in the following example:
I’ve had to change some parameters to the LogisticRegression in order to ensure that it fully ran the optimization procedure for this many polynomials.
The problem here is that, although this classifier might achieve perfect training accuracy, it doesn’t really look like it’s captured “the right” pattern. This is why this classifier makes many more mistakes on the test data, even though it had much higher training accuracy. We have overfit: our model was so flexible that it was able to learn both some real patterns that we wanted it to learn and some noise that we didn’t. As a result, when it made a prediction on new data, the model’s predictions were imperfect, reflecting the noise it learned in the training process.
In machine learning practice, we don’t actually want our models to get perfect scores on the training data – we want them to generalize to new instances of unseen data. Overfitting is one way in which a model can fail to generalize.
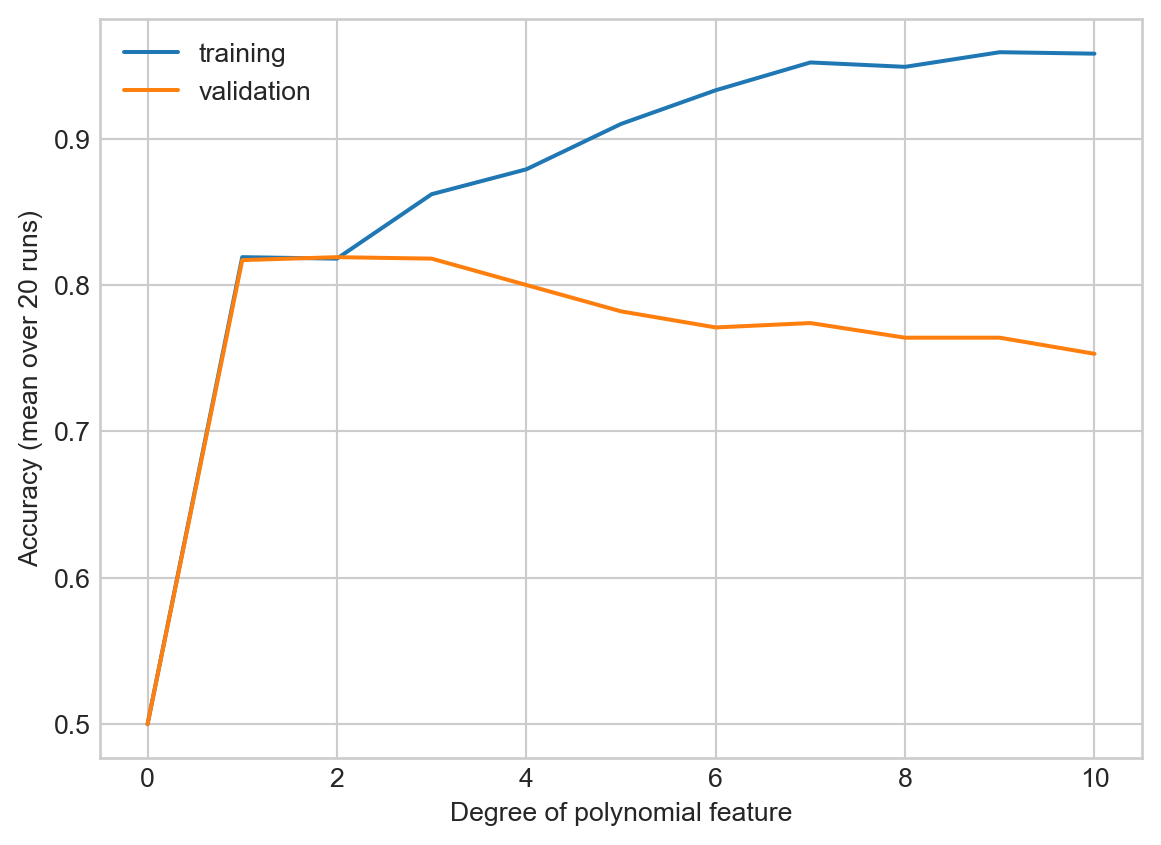
Let’s do an experiment in which we see what happens to the model’s generalization ability when we increase the number of polynomial features:
We observe that there is an optimal number of features for which the model is most able to generalize: around 3 or so. More features than that is actually harmful to the model’s predictive performance on unseen data.
So, one way to promote generalization is to try to find “the right” or “the right number” of features and use them for prediction. This problem is often called feature selection and can be done with cross-validation.
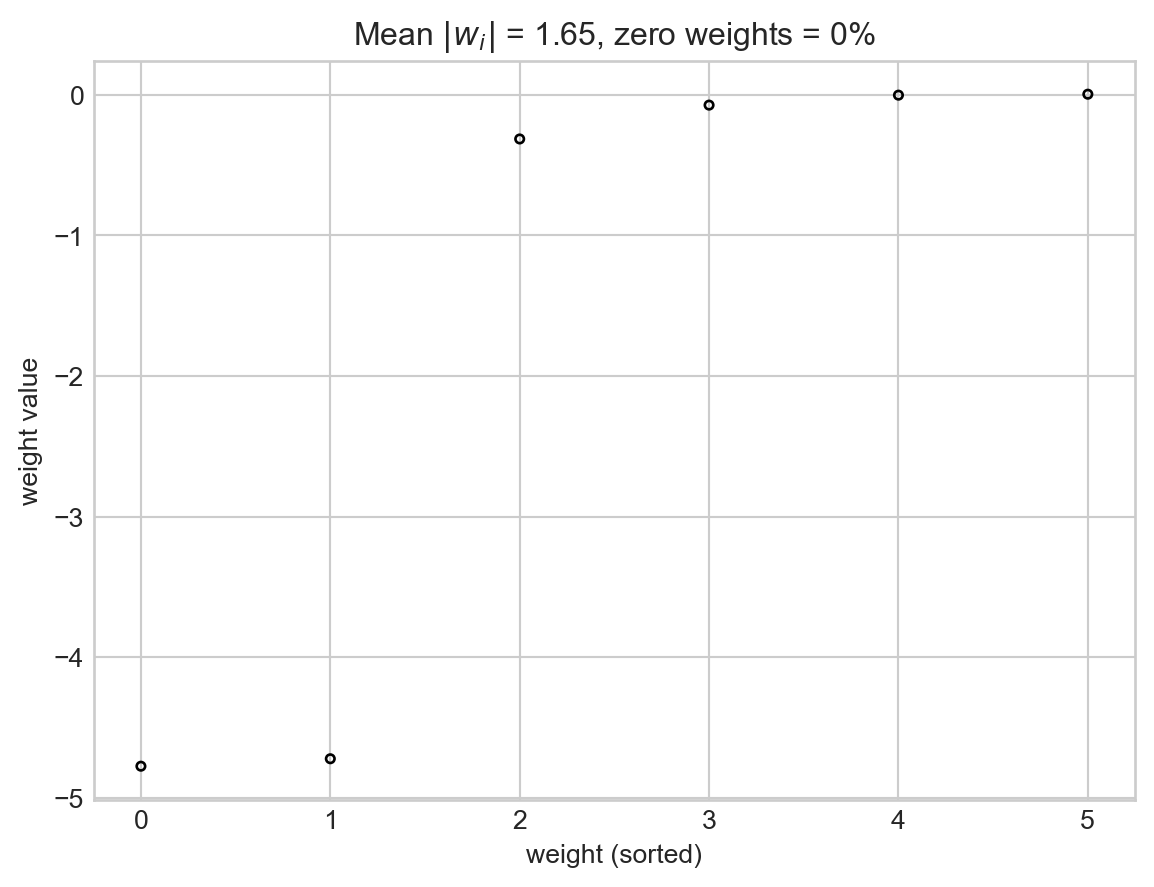
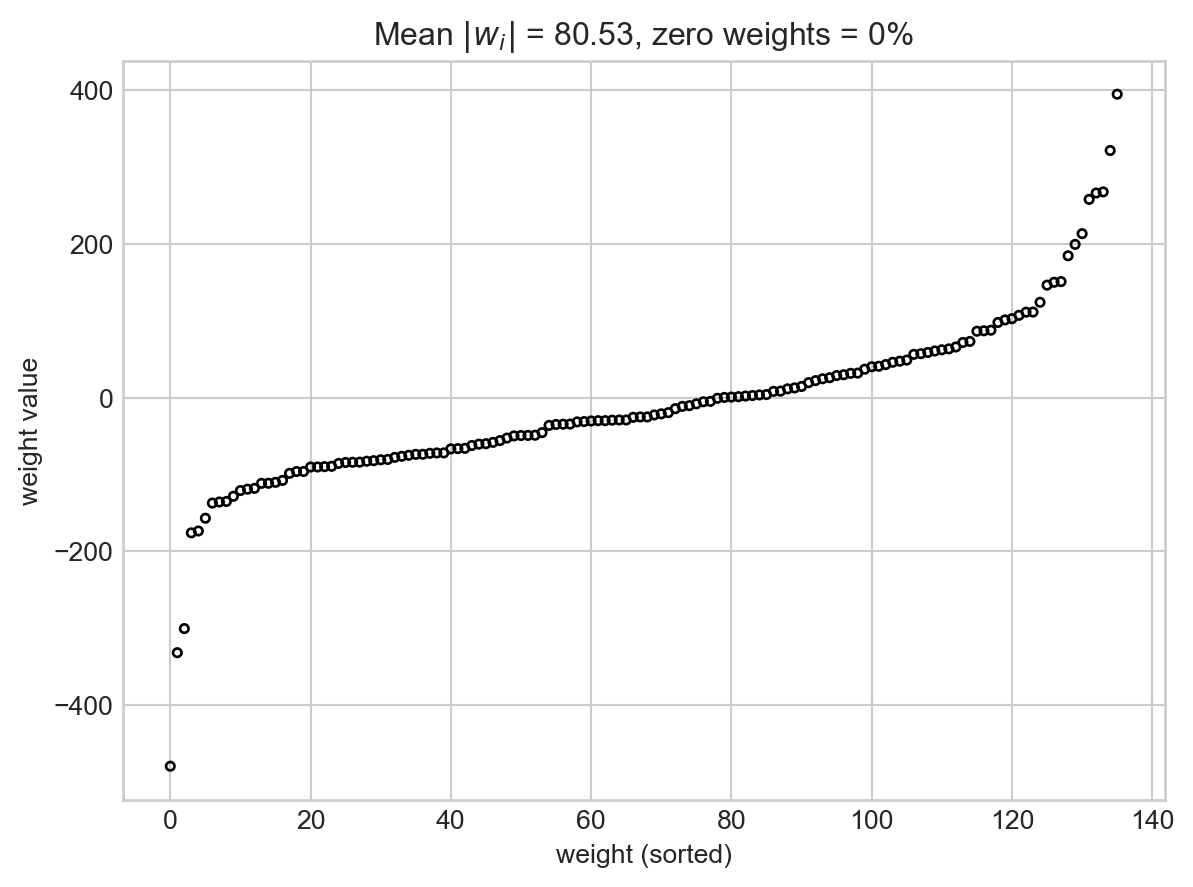
Another common approach to avoid overfitting is called regularization. Regularization proceeds from the insight that wiggly decision boundaries often come from large entries in the weight vector \(\mathbf{w}\). Let’s check this for the degree-15 polynomial features model that we trained previously:
plot_weights(plr)
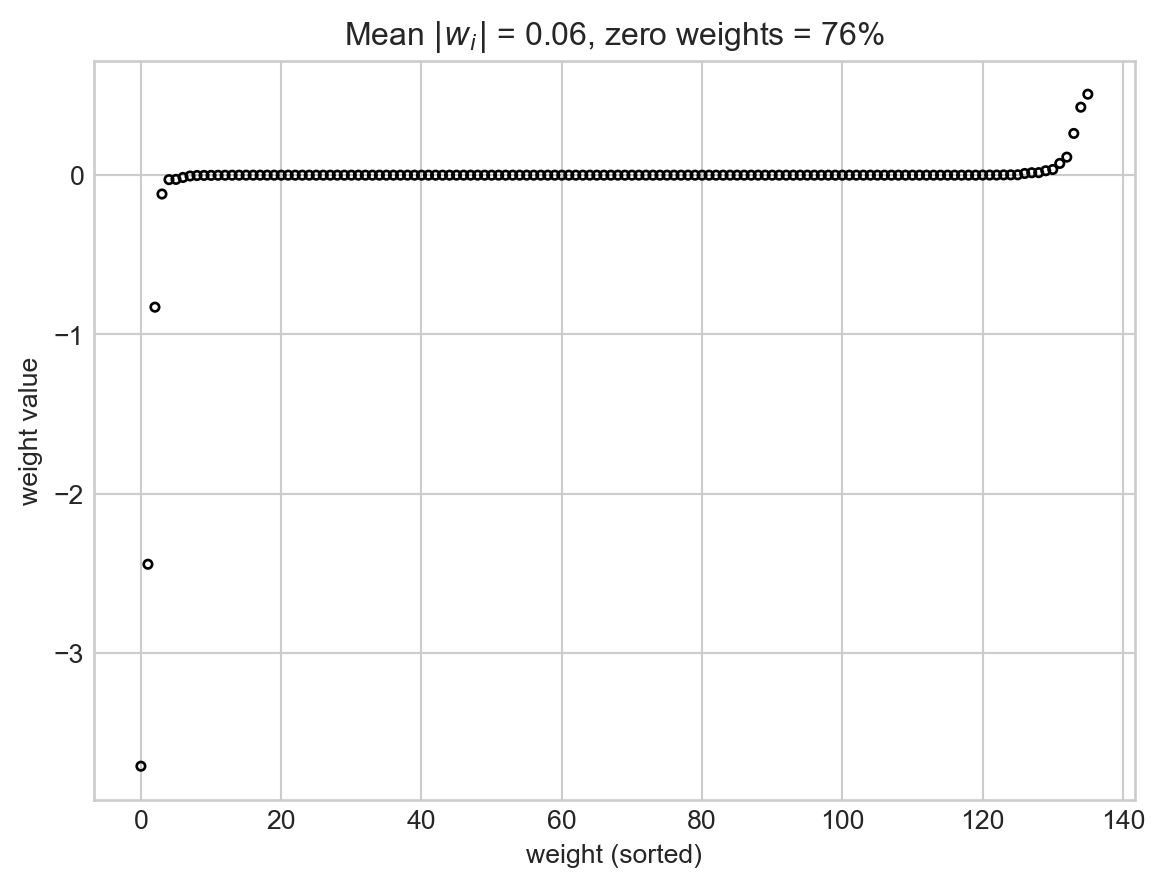
Yikes! Not only are there many weights, but many of them are extremely large.
Can we fix this? In regularization, we add a term to the empirical risk objective function that encourages entries of \(\mathbf{w}\) to be small. We consider the modified objective function \[
L'(\mathbf{w}) = L(\mathbf{w}) + \lambda R(\mathbf{w})\;,
\]
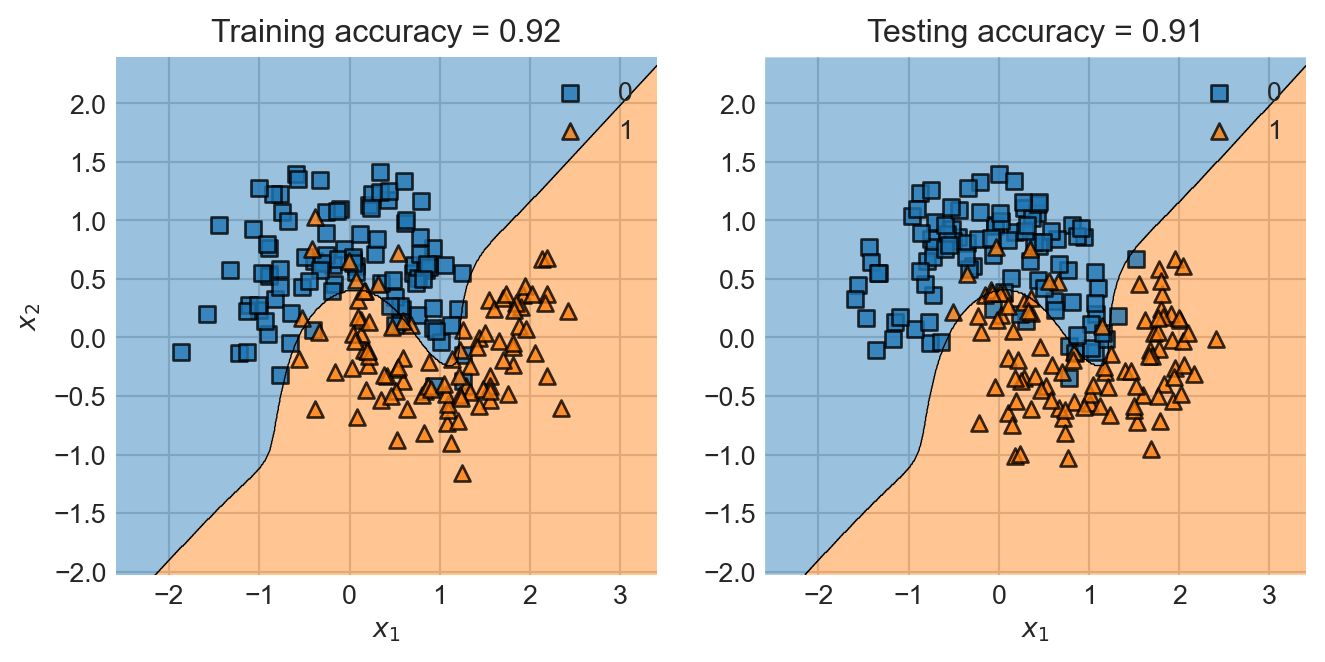
where \(\lambda\) is a regularization strength and \(R(\mathbf{w})\) is a regularization function that aims to shrink the entries of \(\mathbf{w}\) in some way. Common choices of regularization function include the \(\ell_2\) regularizer, which is simply the square Euclidean norm \(R(\mathbf{w}) = \lVert \mathbf{w} \rVert_2^2 = \sum_{j = 1}^p w_i^2\), and the \(\ell_1\) norm given by \(R(\mathbf{w}) = \sum_{j = 1}^p \lvert w_j \rvert\). To see regularization in action, let’s go back to our logistic regression model with a large number of polynomial features. We can see the presence of overfitting in the excessive “wiggliness” of the decision boundary.
If \(\mathbf{x}\) is defined in such a way that it has a constant column (e.g. \(x_{in} = 1\) for all \(n\)), then it is important not to regularize the entries of \(\mathbf{w}\) that correspond to the constant column. This issue can be avoided by assuming that all the entries of the feature matrix \(\Phi(\mathbf{X})\) are column-centered, so that each column mean is zero. This can be achieved simply by defining \(\Phi\) that way!
Fortunately for us, we can actually use regularization directly from inside the scikit-learn implementation of LogisticRegression. Below we specify the penalty (the \(\ell_2\) regularization), the strength of the penalty (in the scikit-learn implementation, you specify \(C = \frac{1}{\lambda}\) so that larger \(C\) means less regularization) and the optimization solver (not all solvers work with all penalties).
This model did much better on the test data than the overfit model.
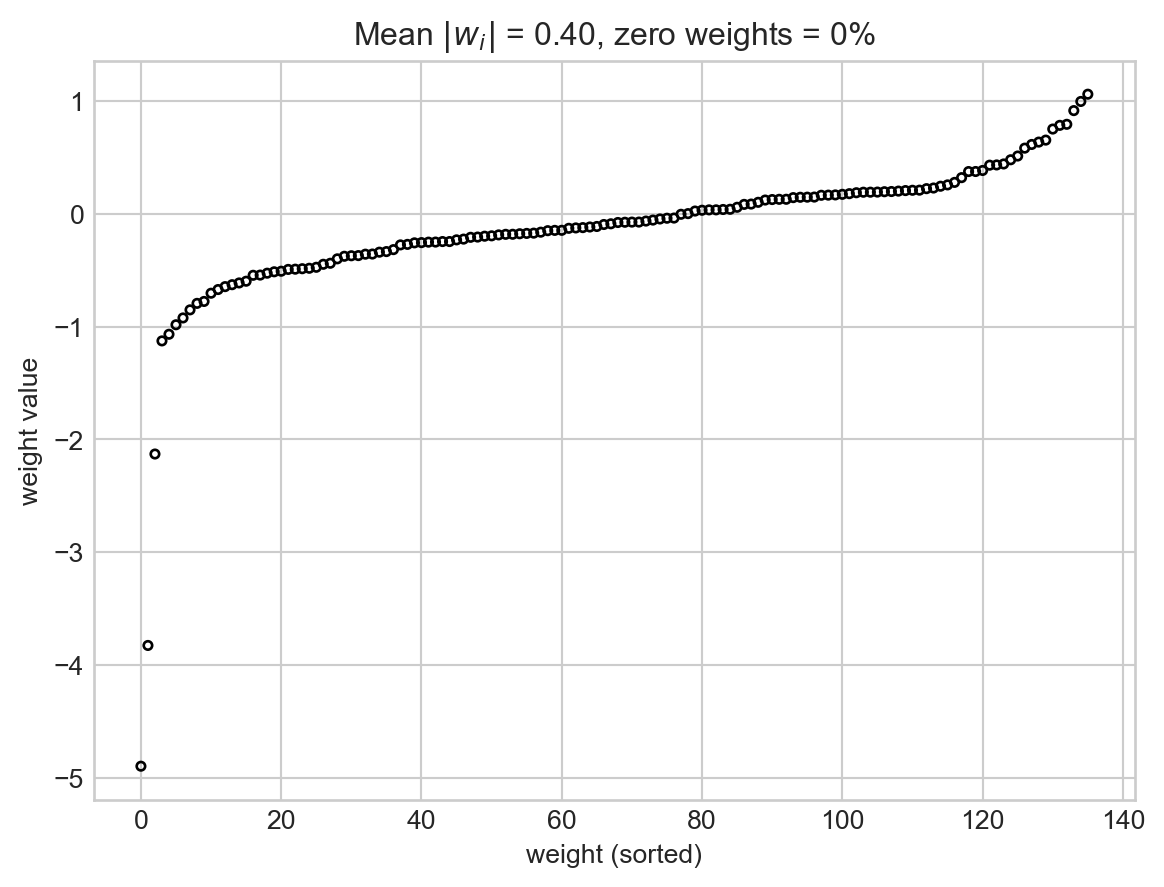
One reason for this success is that the entries of the weight vector are now much smaller:
plot_weights(plr)
In fact, we can even force some of the coefficients of the weight vector to be exactly 0. This is achieved through the use of the \(\ell_1\) regularization term \(R(\mathbf{w}) = \sum_{j = 1}^p \lvert w_j \rvert\).
The benefit of having many weights exactly equal to zero is that it is not necessary to even compute the relevant features in order to make a prediction – we’re just going to multiply them by zero later! We often refer to the resulting choices of the parameter vector \(\mathbf{w}\) as sparse, because most of their entries are zero. Sparsity plays a major role in modern machin elearning.
Gradients of Regularizers
Suppose that we wish to solve the regularized empirical minimization problem with features:
where \(R(\mathbf{w})\) is the regularization term. The gradient of the regularization term. The gradient of this expression is
\[
\begin{aligned}
\nabla L'(\mathbf{w}) = \nabla L(\mathbf{w}) + \lambda \nabla R(\mathbf{w})\;.
\end{aligned}
\] So, to compute the gradient of the regularized empirical risk, we just need the gradient of (a) the standard unregularized empirical risk and the regularization term. Here are two examples of gradients for the regularization term. Suppose that \(w_i\) is the coefficient of the constant feature in \(\mathbf{w}\), and let \(\mathbf{w}_{-i}\) be the vector of entries of \(\mathbf{w}\)excluding \(w_i\). Then, the gradients for the two most common regularization terms are given by the derivatives:
Usually, data processing pipelines are set up so that \(i = 1\) or \(i = n\).
Technically, the derivative of \(\lvert w_j \rvert\) is not defined when \(w_j = 0\). It is ok to pretend that it is and equal to zero for the purposes of optimization due to the theory of subdifferentials.
Reflecting on Empirical Risk Minimization
We have now introduced all the fundamental features of modern empirical risk minimization for training machine learning models. We aim to find a weight vector \(\hat{\mathbf{w}}\) that solves the problem
Until roughly 2005 or so, Equation 11.2 was the state of the art for a wide array of classification and regression problems. Common questions would include:
What loss functions\(\ell\) should be used for model scoring?
What feature maps\(\phi\) should be used for extracting useful features from the data?
What regularization terms should be used to guard against overfitting?
It’s not the case that all of machine learning fit into this framework; important supervised techniques that don’t fall into this category include probabilistic machine learning and tree-based methods like decision trees and random forests.
We’ll soon study two ways to move past this paradigm: kernel methods and deep learning.