def zero_one_loss(s, y):
return 1*(s*(2*y-1) < 0)8 Convex Empirical Risk Minimization
Open the live notebook in Google Colab or download the live notebook
.Last time, we studied the binary classification problem. In this problem, we assume that we have a feature matrix \(\mathbf{X} \in \mathbb{R}^{n\times p}\). Each row of this feature matrix gives the predictor data (features) for each of \(n\) total observations:
\[ \mathbf{X} = \left[\begin{matrix} & - & \mathbf{x}_1 & - \\ & - & \mathbf{x}_2 & - \\ & \vdots & \vdots & \vdots \\ & - & \mathbf{x}_{n} & - \end{matrix}\right] \]
We also have a target vector \(\mathbf{y} \in \{0,1\}^n\). Here’s an example of how our training data might look:
For convenience, we will continue to assume that the final column of \(\mathbf{X}\) is a column of 1s; i.e. \(x_{ip} = 1\) for all \(i = 1,\ldots,n\).
Code
import torch
import numpy as np
from matplotlib import pyplot as plt
plt.style.use('seaborn-v0_8-whitegrid')
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
def classification_data(n_points = 300, noise = 0.2, p_dims = 2):
y = torch.arange(n_points) >= int(n_points/2)
y = 1.0*y
X = y[:, None] + torch.normal(0.0, noise, size = (n_points,p_dims))
X = torch.cat((X, torch.ones((X.shape[0], 1))), 1)
return X, y
X, y = classification_data(n_points = 300, noise = 0.2)
def plot_classification_data(X, y, ax):
assert X.shape[1] == 3, "This function only works for data created with p_dims == 2"
targets = [0, 1]
markers = ["o" , ","]
for i in range(2):
ix = y == targets[i]
ax.scatter(X[ix,0], X[ix,1], s = 20, c = y[ix], facecolors = "none", edgecolors = "darkgrey", cmap = "BrBG", vmin = -1, vmax = 2, alpha = 0.8, marker = markers[i])
ax.set(xlabel = r"$x_1$", ylabel = r"$x_2$")
fig, ax = plt.subplots(1, 1)
X, y = classification_data()
plot_classification_data(X, y, ax)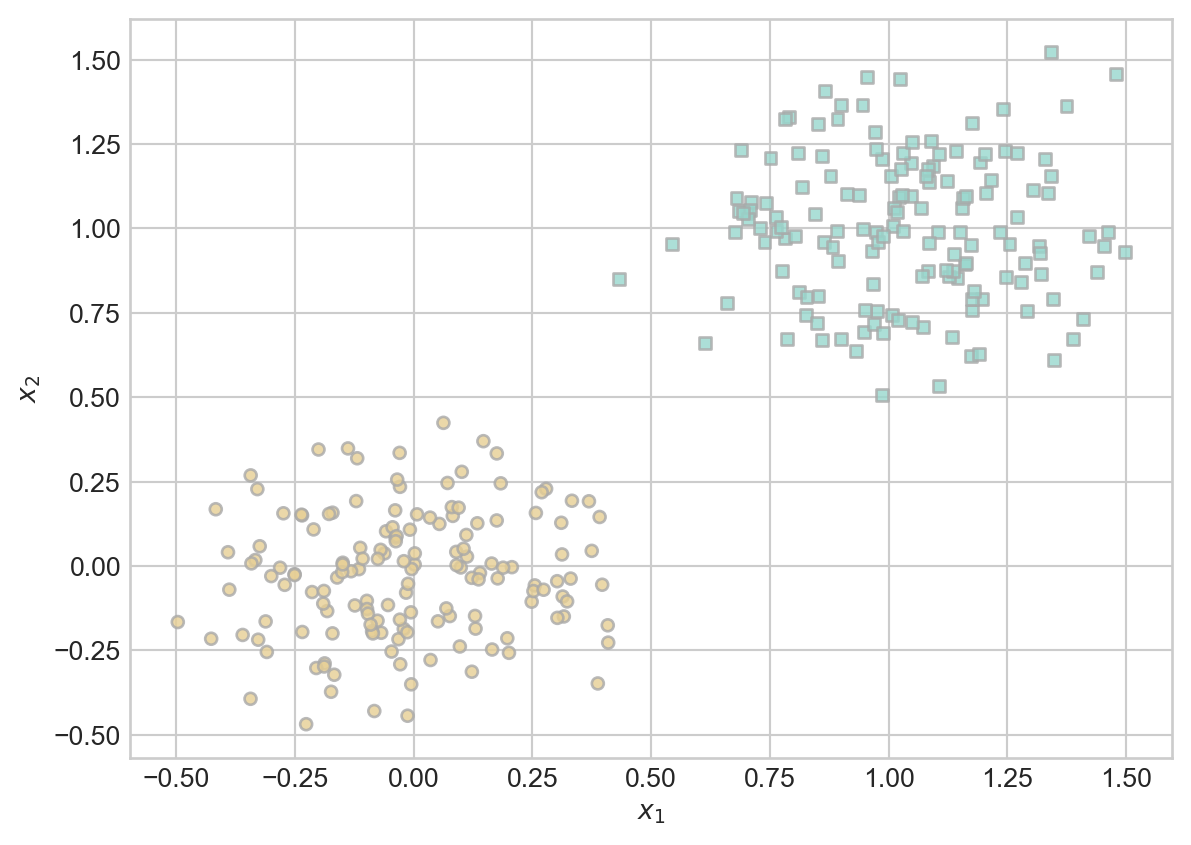
We continue to study the linear classification problem. We will find a vector of weights \(\mathbf{w}\) with the property that the hyperplane defined by the equation
\[ \langle \mathbf{w}, \mathbf{x} \rangle = 0 \]
approximately separates the two classes.
Modeling Choices
Once we have chosen linear models as our tool, we can specify a model for the binary classification task by making two additional choices:
- Loss: How will we measure the success of the model in distinguishing the two classes?
- Optimizer: What algorithm will we use in order to minimize the loss?
What choices did we make in the context of the perceptron?
The loss function was the misclassification rate. If we let \(s_i = \langle \mathbf{w}, \mathbf{x}_i\rangle\), then we can write the loss like this:
Here, the term \(2y_i - 1\) transforms a \(y_i\) with values in \(\{0,1\}\) into one with values in \(\{-1,1\}\).
\[ L(\mathbf{w}) = \frac{1}{n}\sum_{i = 1}^n \mathbb{1}[s_i (2y_i-1) < 0] \]
The optimizer we used to minimize the loss was the perceptron update, in which we picked a random point \(i\) and then performed the update
\[ \mathbf{w}^{(t+1)} = \mathbf{w}^{(t)} + \mathbb{1}[s_i (2y_i-1) < 0]y_i \mathbf{x}_i \]
If \(i\) is correctly classified (i.e. if \(s_i(2 y_i - 1) > 0\)), then the second term zeros out and nothing happens.
However, as we saw, this doesn’t actually work that well. There are two problems:
- Our problem with the optimizer was that this update won’t actually converge if the data is not linearly separable. Maybe we could choose a better optimizer that would converge?
- Unfortunately not – as we saw last time, the very problem of minimizing \(L(\mathbf{w})\) is NP-hard. This is a problem with the loss function itself.
So, how could we choose a better loss function that would allow us to create efficient algorithms?
Per-Observation Loss Functions
Let’s start by visualizing a single term of the perceptron loss function. We’ll view this as a function of the score \(s\) and the true target value \(y\):
\[ \ell(s, y) = \mathbb{1}[s (2y-1) < 0]\;. \]
Let’s implement this function in Python:
Here’s a plot of this function for each of the two possible values of \(y\):
Code
from matplotlib import pyplot as plt
plt.style.use('seaborn-v0_8-whitegrid')
# plt.rcParams["figure.figsize"] = (10, 4)
def plot_loss(loss_fun, show_line = False):
fig, axarr = plt.subplots(1, 2, figsize = (6, 3), sharey = True)
s = torch.linspace(-1, 1, 10001)
for j in range(2):
y = [0, 1][j]
axarr[j].set_title(f"y = {y}")
axarr[j].set(xlabel = r"$s$",
ylabel = r"$\ell(s, y)$")
ix1 = s < 0
axarr[j].plot(s[ix1], loss_fun(s[ix1], y), color = "black")
ix2 = s > 0
axarr[j].plot(s[ix2], loss_fun(s[ix2], y), color = "black")
if show_line:
s1 = torch.tensor([-0.7])
s2 = torch.tensor([0.9])
axarr[j].plot([s1, s2], [loss_fun(s1, y), loss_fun(s2, y)], color = "darkgrey", linestyle = "--")
plt.tight_layout()
return fig, axarrThe zero-one loss looks like this:
fig, axarr = plot_loss(loss_fun = zero_one_loss)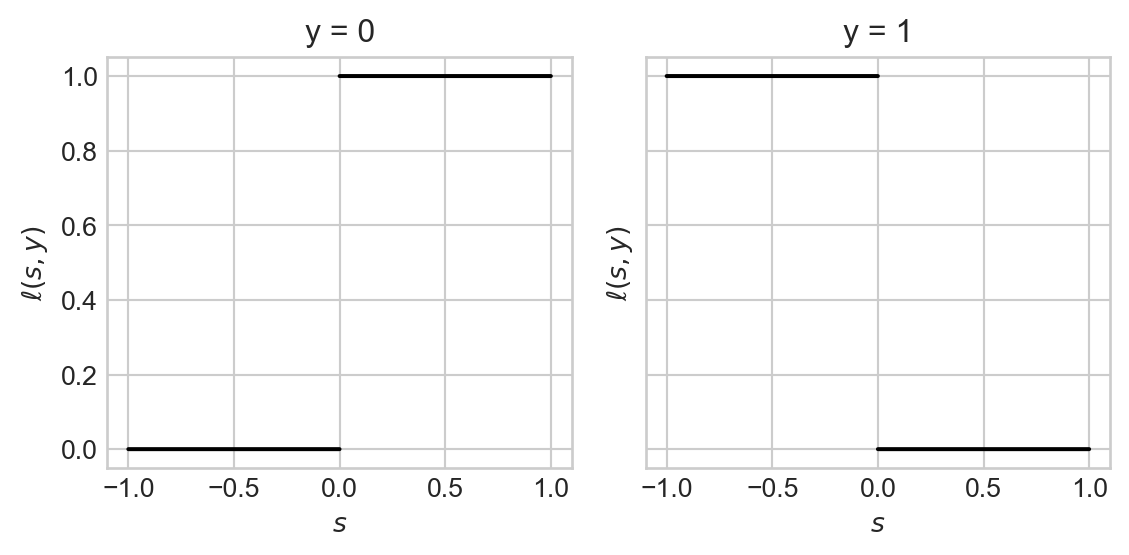
The problem with this loss function \(\ell\) is that we can “draw lines under the function.” What this means is that we can pick two points on the graph of the function, connect them with a line, and find that the line lies under the graph of the function in some regions:
fig, axarr = plot_loss(loss_fun = zero_one_loss, show_line = True)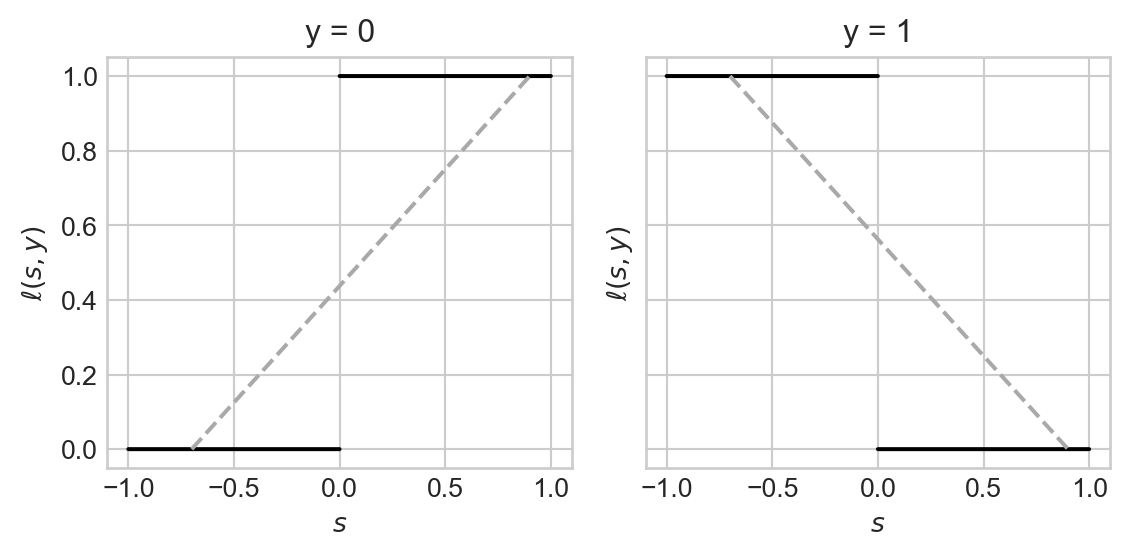
Surprisingly, this specific geometric property is what’s blocking us from achieving performant searchability for the problem of finding \(\mathbf{w}\).
Convex Functions
Intuitively, a convex function is just a function with the property that any line joining two points on the graph of the function must always lie above that graph. The geometric picture here is that a convex function is “bowl-shaped.”
Definition 8.1 A set \(S \subseteq \mathbb{R}^n\) is convex if, for any two points \(\mathbf{z}_1, \mathbf{z}_2 \in S\) and for any \(\lambda \in [0,1]\), the point \(\mathbf{z} = \lambda \mathbf{z}_1 + (1-\lambda) \mathbf{z}_2\) is also an element of \(S\).
Definition 8.2 (Convex Functions) Let \(S \subseteq \mathbb{R}^n\) be convex. A function \(f:S \rightarrow \mathbb{R}\) is convex if, for any \(\lambda \in \mathbb{R}\) and any two points \(\mathbf{z}_1, \mathbf{z}_2 \in S\), we have
\[ f(\lambda \mathbf{z}_1 + (1-\lambda)\mathbf{z}_2) \leq \lambda f( \mathbf{z}_1 ) + (1-\lambda)f(\mathbf{z}_2)\;. \]
The function \(f\) is strictly convex if the inequality is strict: for all \(\lambda\), \(\mathbf{z}_1\), and \(\mathbf{z}_2\),
\[ f(\lambda \mathbf{z}_1 + (1-\lambda)\mathbf{z}_2) < \lambda f( \mathbf{z}_1 ) + (1-\lambda)f(\mathbf{z}_2)\;. \]
The most familiar example of a convex function is our good friend the convex parabola:
x = torch.linspace(-1, 1, 10001)
y = x**2
plt.plot(x, y)
plt.gca().set(xlabel = r"$x$", ylabel = r"$f(x)$")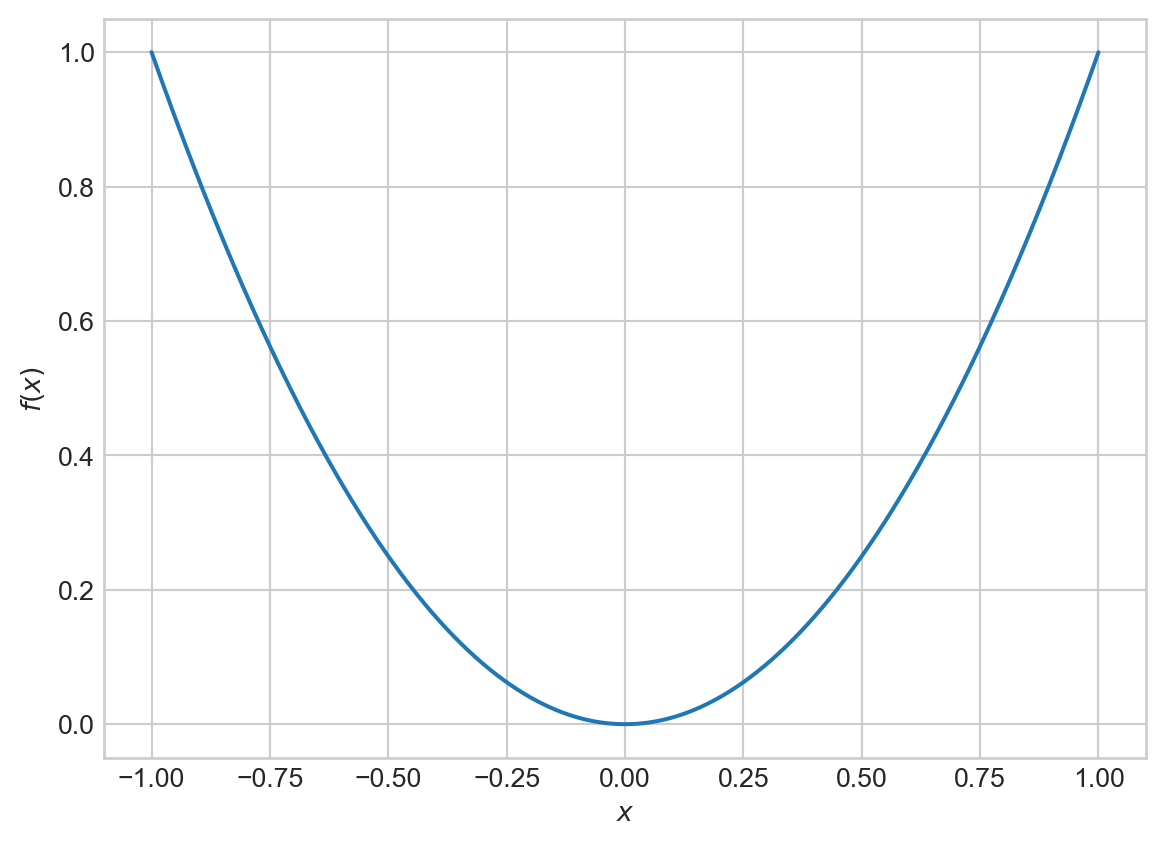
Note that any straight line connecting two points on this graph always stays above the graph of the parabola. As we saw above, the 0-1 loss function \(\ell(s, y) = \mathbb{1}[s(2y-1)<0]\) does not have this property.
Two Convex Loss Functions
The purpose of introducing convexity in this context is to replace the nonconvex 0-1 loss function with a convex substitute. Here’s an example, which is usually called the hinge loss, which is defined by the formula
Such functions are also sometimes called surrogate loss functions.
\[ \ell(s, y) = y \max \{0, s\} + (1 - y) \max\{0, -s\}\;. \]
Let’s implement and visualize the hinge loss:
def hinge(s, y):
return y * torch.max(torch.zeros_like(s), s) + (1-y) * torch.max(torch.zeros_like(s), -s)fig, axarr = plot_loss(loss_fun = hinge, show_line = True)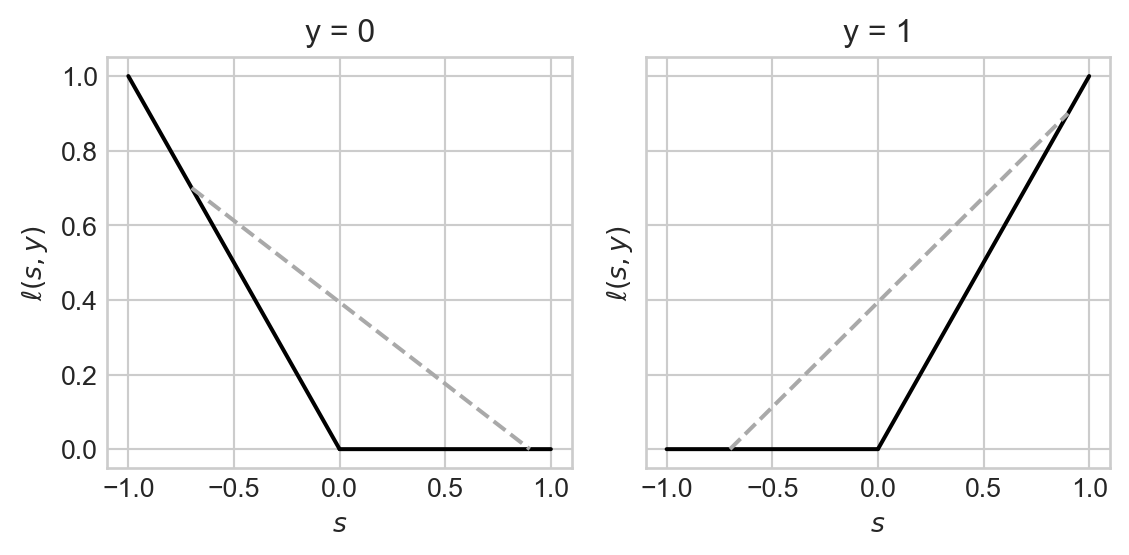
The hinge loss is not strictly convex and is not even everywhere differentiable! Despite this, the fact that it is convex has made it a modern workhorse of machine learning. The support vector machine (SVM) operates by minimizing the hinge loss. The “Rectified Linear Unit” (ReLU) is a mainstay of modern deep learning–and is just another name for the hinge loss.
Another loss function is the sigmoid binary cross entropy, which is defined by the formula \[ \begin{aligned} \ell(s, y) &= -y \log \sigma(s) - (1-y)\log (1-\sigma(s))\;, \end{aligned} \]
In this formula, \(\sigma(s) = \frac{1}{1 + e^{-s}}\) is the logistic sigmoid function.
Let’s implement this function for ourselves:
sig = lambda s: 1 / (1 + torch.exp(-s))
binary_cross_entropy = lambda s, y: -(y * sig(s).log() + (1 - y)*(1-sig(s)).log())fig, axarr = plot_loss(loss_fun = binary_cross_entropy, show_line = True)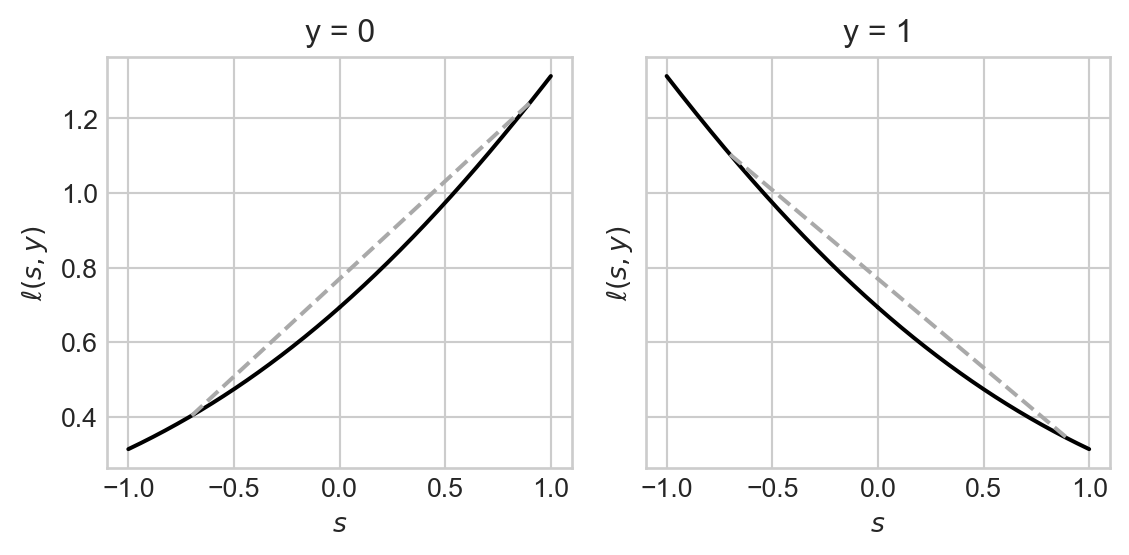
The binary cross-entropy is also convex, and has the considerable benefit of being everywhere differentiable.
Convexity In Several Dimensions
We intentionally formulated our definition of convexity for functions of many variables. Here is a convex function \(f:\mathbb{R}^2 \rightarrow \mathbb{R}\).
fig, ax = plt.subplots(subplot_kw={"projection": "3d"})
x = torch.linspace(-1, 1, 1001)[:, None]
y = torch.linspace(-1, 1, 1001)[None, :]
z = x**2 + y**2
ax.plot_surface(x, y, z, cmap="inferno_r",
linewidth=0, antialiased=False)
ax.set(xlabel = r"$x_1$", ylabel = r"$x_2$")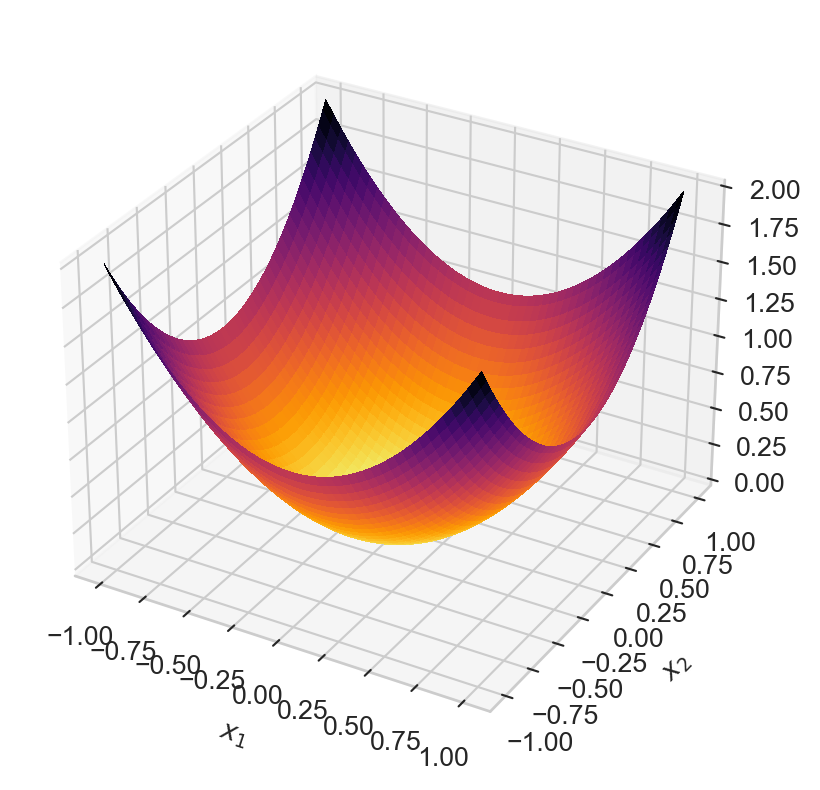
You could imagine trying to draw a straight line between two points on the graph of this function – the line would always be above the graph. When thinking about convexity in many variables, it is often sufficient to imagine a bowl-shaped function like this one.
Convex Empirical Risk Minimization
We are now ready to define the primary framework in which we will conduct supervised machine learning: convex empirical risk minimization.
Definition 8.3 (Empirical Risk Minimization) Given a loss function \(\ell:\mathbb{R}\times \{0,1\} \rightarrow \mathbb{R}\), a feature matrix \(\mathbb{X} \in \mathbb{R}^{n\times p}\), a target vector \(\mathbf{y}\), and a parameter vector \(\mathbf{w} \in \mathbb{R}^p\), the empirical risk of \(\mathbf{w}\) is
\[ \begin{aligned} L(\mathbf{w}) = \frac{1}{n}\sum_{i = 1}^n \ell(s_i, y_i), \quad&\text{where }s_i = \langle \mathbf{w}, \mathbf{x}_i\rangle\;. \end{aligned} \]
The empirical risk minimization problem is to find the value of \(\mathbf{w}\) that makes \(L(\mathbf{w})\) smallest:
\[ \DeclareMathOperator*{\argmin}{argmin} \begin{aligned} \hat{\mathbf{w}} &= \argmin_{\mathbf{w}} L(\mathbf{w}) \\ &= \argmin_{\mathbf{w}} \frac{1}{n}\sum_{i = 1}^n \ell(s_i, y_i) \\ &= \argmin_{\mathbf{w}} \frac{1}{n}\sum_{i = 1}^n \ell(\langle \mathbf{w}, \mathbf{x}_i\rangle, y_i)\;. \end{aligned} \tag{8.1}\]
Proposition 8.1 (Convex \(\ell\) means convex \(L\)) If the per-observation loss function \(\ell:\mathbb{R}\times \{0,1\} \rightarrow \mathbb{R}\) is convex in its first argument, then the empirical risk \(L(\mathbf{w})\) is convex as a function of \(\mathbf{w}\).
The proof of Proposition 8.1 involves some elementary properties of convex functions:
- If \(f(\mathbf{z})\) is convex as a function of \(\mathbf{z}\), then \(g(\mathbf{z}) = f(\mathbf{A}\mathbf{z'})\) is also convex as a function of \(\mathbf{z}'\), provided that all the dimensions work out.
- Any finite sum of convex functions is convex.
So, we know that if we choose \(\ell\) to be convex in the score function, then the entire empirical risk \(L\) will be convex as a function of the weight vector \(\mathbf{w}\).
Why do we care?
Convex Functions Have Global Minimizers
We want to solve the empirical risk minimization problem:
\[ \DeclareMathOperator*{\argmin}{argmin} \begin{aligned} \hat{\mathbf{w}} &= \argmin_{\mathbf{w}} L(\mathbf{w}). \end{aligned} \]
We might ask ourselves a few questions about this problem:
- Existence: Does there exist any choice of \(\mathbf{w}\) that achieves a minimizing value for this function?
- Uniqueness: Is this choice of \(\mathbf{w}\) unique, or are there multiple candidates?
- Searchability: are there algorithms which are guaranteed to (a) terminate and (b) not get “trapped” at a bad solution?
- Performance: If it’s possible to find the best solution, can we do so efficiently using simple algorithms?
Answering these questions precisely requires a bit more math:
Definition 8.4 (Local and Global Minimizers) A point \(\mathbf{z}\in S\) is a global minimizer of the function \(f:S \rightarrow \mathbb{R}\) if \(f(\mathbf{z}) \leq f(\mathbf{z}')\) for all \(\mathbf{z}' \in S\).
A point \(\mathbf{z} \in S\) is a local minimizer of \(f:S \rightarrow \mathbb{R}\) if there exists a neighborhood \(T \subseteq S\) containing \(\mathbf{z}\) such that \(\mathbf{z}\) is a global minimizer of \(f\) on \(T\).
It’s ok if you don’t know what it means for a set to be closed – all the convex functions we will care about in this class will either be defined on sets where this theorem holds or will be otherwise defined so that the conclusions apply.
Theorem 8.1 (Properties of Convex Functions) Let \(f:S \rightarrow \mathbb{R}\) be a convex function. Then:
- If \(S\) is closed and bounded, \(f\) has a minimizer \(\mathbf{z}^*\) in \(S\).
- Furthermore, if \(\mathbf{z}^*\) is a local minimizer of \(f\), then it is also a global minimizer.
- If in addition \(f\) is strictly convex, then this minimizer is unique.
Proof. The proof of item 1 needs some tools from real analysis. The short version is:
- Every convex function is continuous.
- If \(S\subseteq \mathbb{R}^n\) is closed and bounded, then it is compact.
- Continuous functions achieve minimizers and maximizers on compact sets.
It’s ok if you didn’t follow this! Fortunately the second part of the proof is one we can do together. Suppose to contradiction that \(\mathbf{z}^*\) is a local minimizer of \(f\), but that there is also a point \(\mathbf{z}'\) such that \(f(\mathbf{z}') < f(\mathbf{z}^*)\). Since \(\mathbf{z}^*\) is a local minimizer, we can find some neighborhood \(T\) containing \(\mathbf{z}^*\) such that \(\mathbf{z}^*\) is a minimizer of \(f\) on \(T\). Let \(\lambda\) be some very small number and consider the point \(\mathbf{z} = \lambda \mathbf{z}' + (1-\lambda)\mathbf{z}^*\). Specifically, choose \(\lambda\) small enough so that \(\mathbf{z} \in T\) (since this makes \(\mathbf{z}\) close to \(\mathbf{z}^*\)). We can evaluate
\[ \begin{align} f(\mathbf{z}) &= f(\lambda \mathbf{z}' + (1-\lambda)\mathbf{z}^*) &\quad \text{(definition of $\mathbf{z}$)}\\ &\leq \lambda f(\mathbf{z}') + (1-\lambda)f(\mathbf{z}^*) &\quad \text{($f$ is convex)} \\ &= f(\mathbf{z}^*) + \lambda (f(\mathbf{z}') - f(\mathbf{z}^*)) &\quad \text{(algebra)}\\ &< f(\mathbf{z}^*)\;. &\quad \text{(assumption that $f(\mathbf{z}') < f(\mathbf{z}^*)$)} \end{align} \]
But this is a contradiction, since we constructed \(\mathbf{z}\) to be in the neighborhood \(T\) where \(\mathbf{z}^*\) is a local minimizer. We conclude that there is no \(\mathbf{z}'\) such that \(f(\mathbf{z}') < f(\mathbf{z}^*)\), and therefore that \(\mathbf{z}^*\) is a global minimizer.
The proof of the third part follows a very similar argument to the proof of the second part.
These properties of convex functions have very important implications for our fundamental questions on empirical risk minimization. If we choose a convex per-observation loss function \(\ell\), then our empirical risk \(L\) will also be convex, and:
Existence. The minimizer \(\hat{\mathbf{w}} = \argmin_{\mathbf{w}}L(\mathbf{w})\) will exist.
Uniqueness: The minimizer \(\hat{\mathbf{w}} = \argmin_{\mathbf{w}}L(\mathbf{w})\) will be unique: if we run a minimization algorithm repeatedly, we’ll get the same answer every time.
Searchability: When \(L\) is convex, there are also no local minimizers other than the global minimizer. Algorithmically, this is the most important property of convexity. It means that if I manage to find any local minimizer at all, that point must be the global minimizer.
If you’ve taken an algorithms class, one way of thinking of convexity is that it guarantees that greedy methods work for solving minimization problems.
Performance: Convexity significantly reduces the difficulty of our task: instead of trying to find “the best” solution, it’s sufficient for us to find any local optimum. This means that we can design our algorithms to be “greedy local minimizer hunters.” There are lots of fast algorithms to do this. An especially important class of algorithms are gradient descent methods, which we’ll discuss soon.
Demo: Logistic Regression
You may have heard of logistic regression in a course on statistics or data science. Logistic regression is simply binary classification using the binary cross-entropy loss function which we saw above:
\[ \begin{aligned} \ell(s, y) &= -y \log \sigma(s) - (1-y)\log (1-\sigma(s))\;, \end{aligned} \]
As can be proven with calculus, this function is convex as a function of \(\mathbf{s}\).
So, let’s do convex empirical risk minimization! We’ll use the following data set. Note that this data is not linearly separable and therefore the perceptron algorithm would not converge.
fig, ax = plt.subplots(1, 1)
X, y = classification_data(noise = 0.5)
plot_classification_data(X, y, ax)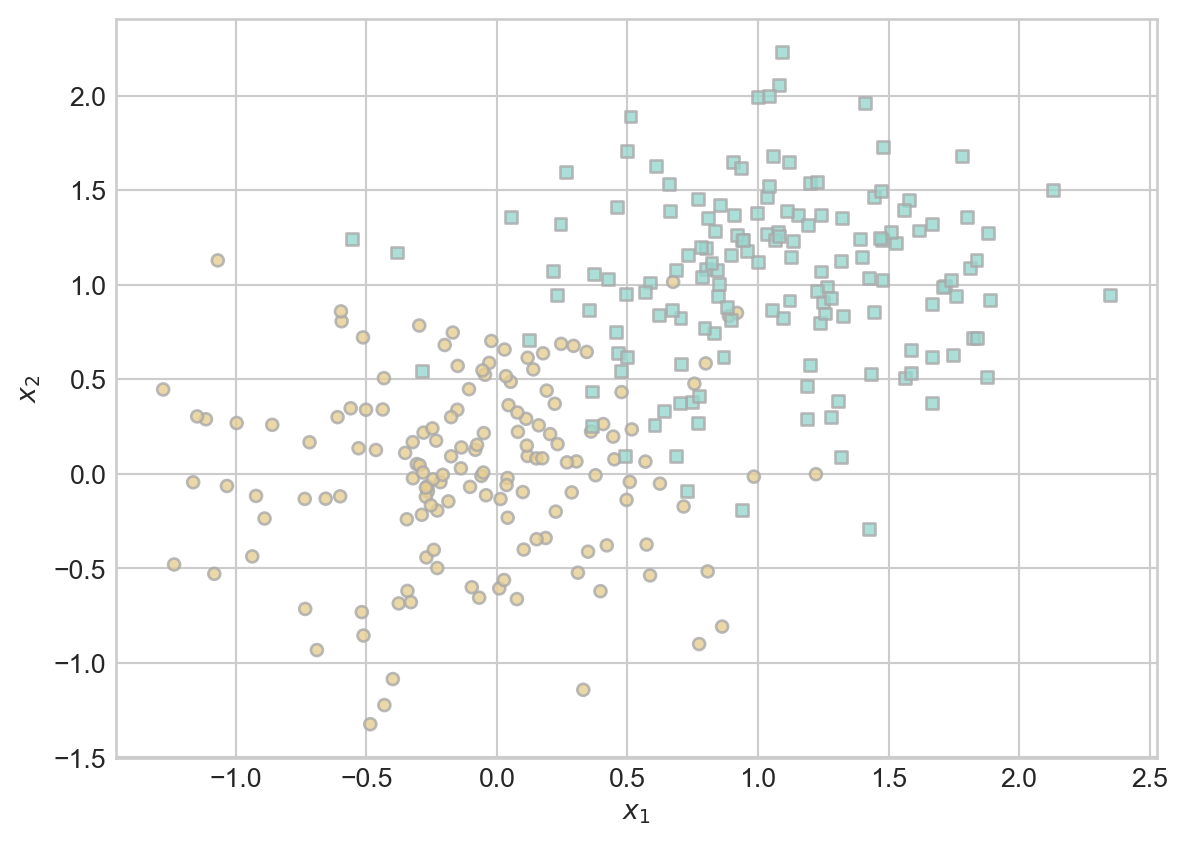
First, we’ll define a complete function for calculating the empirical risk for a given value of \(\mathbf{w}\). Since we already implemented binary_cross_entropy, this implementation is very quick:
def empirical_risk(w, X, y):
s = X@w
return binary_cross_entropy(s, y).mean()Now we’ll use the minimize function from scipy.optimize to find the value of \(\mathbf{w}\) that makes this function smallest:
We initialize
w0 as a Numpy array for compatibility reasons with scipy.optimize.minimize.from scipy.optimize import minimize
w0_array = np.array([1.0, 1.0, 1.0]) # initial guess for w
result = minimize(lambda w: empirical_risk(w, X, y).item(), x0 = w0_array)
w = result.x
print(f"""Learned parameter vector w = {w}.
The empirical risk is {result.fun:.4f}.""")Learned parameter vector w = [ 3.5629569 4.40024659 -4.07831583].
The empirical risk is 0.2056.Code
def draw_line(w, X, y, x_min, x_max, ax, **kwargs):
fig, ax = plt.subplots(1, 1)
plot_classification_data(X, y, ax)
x = torch.linspace(x_min, x_max, 101)
y = -(w[0]*x + w[2])/w[1]
l = ax.plot(x, y, **kwargs)
draw_line(w, X, y, x_min = -0.5, x_max = 1.5, ax = ax, color = "black", linestyle = "dashed")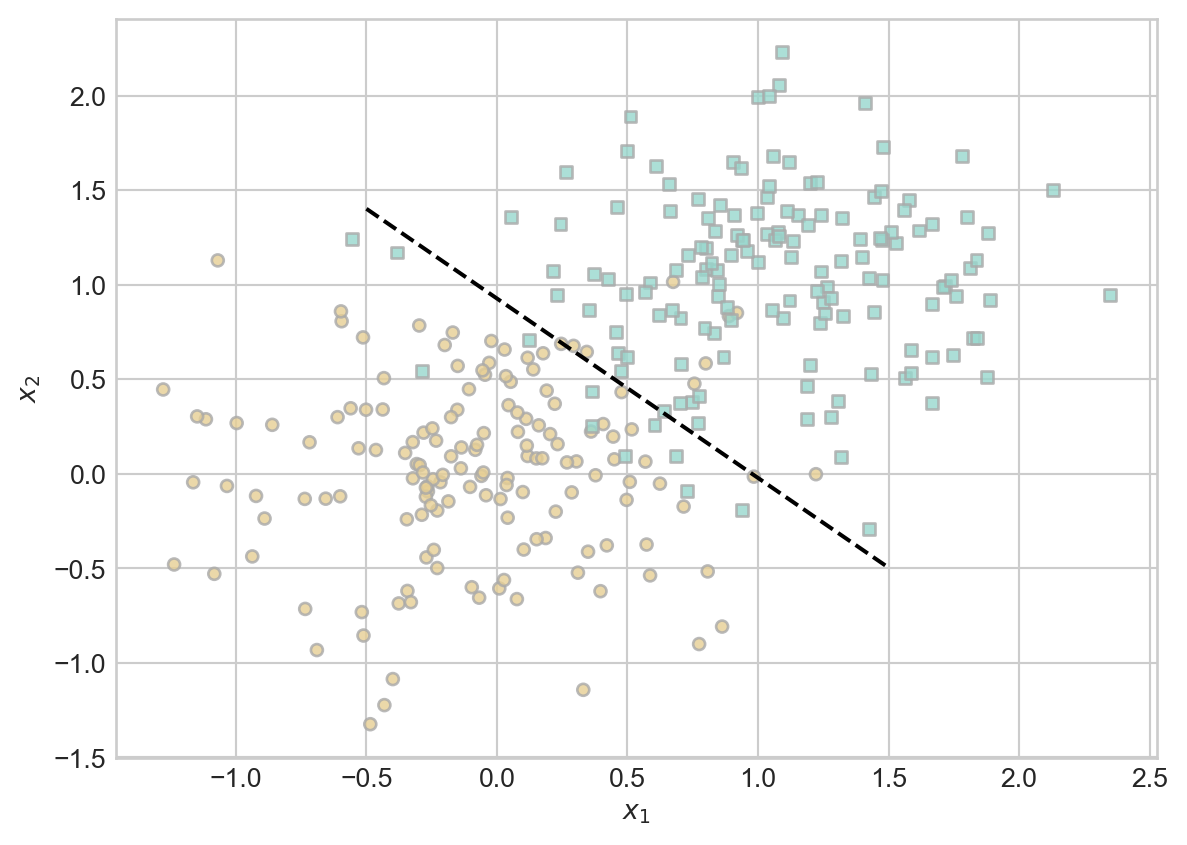
This looks pretty good. Let’s compute the accuracy.
s = X@w
accuracy = (1.0*((s>0) == y)).mean()
accuracytensor(0.9200)(Optional): A Logistic Regression Training Loop
How would we do this if we didn’t have access to the minimize function? We’ll soon discuss this question much more. For now, we can take a look at the code block below, which implements such a loop using a framework very similar to the one we learned for perceptron. This model also inherits from the LinearModel class that you previously started implementing. The training loop is also very similar to our training loop for the perceptron. The main difference is that the loss is calculated using the binary_cross_entropy function above, and the step function of the GradientDescentOptimizer works differently in a way that we will discuss in the following section.
Starting with the code block below, you won’t be able to follow along in coding these notes unless you have sneakily implemented logistic regression in a hidden module.
from hidden.logistic import LogisticRegression, GradientDescentOptimizer
# instantiate a model and an optimizer
LR = LogisticRegression()
opt = GradientDescentOptimizer(LR)
# for keeping track of loss values
loss_vec = []
for _ in range(100):
# not part of the update: just for tracking our progress
loss = LR.loss(X, y)
loss_vec.append(loss)
# only this line actually changes the parameter value
opt.step(X, y, lr = 0.02)
plt.plot(torch.arange(1, len(loss_vec)+1), loss_vec, color = "black")
plt.semilogx()
labs = plt.gca().set(xlabel = "Number of gradient descent iterations", ylabel = "Loss (binary cross entropy)")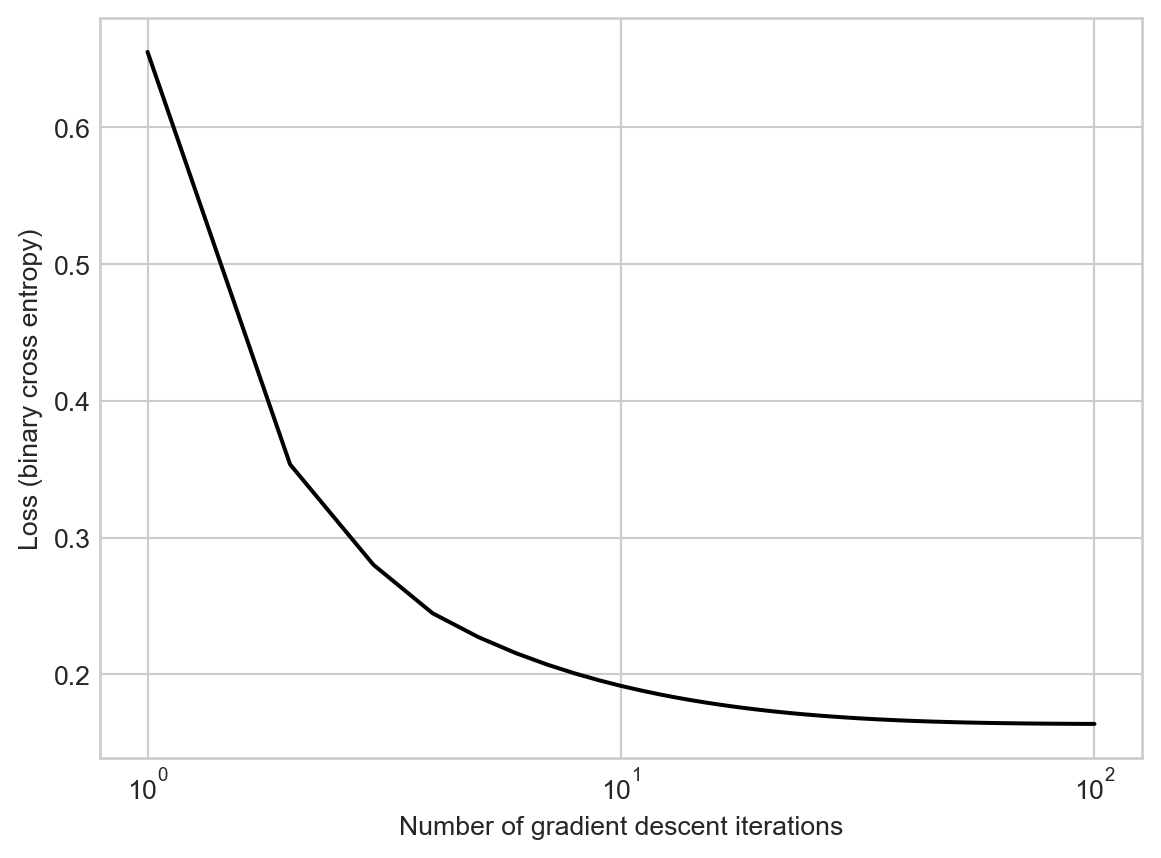
The loss quickly levels out to a constant value (which is the same as we learned with scipy.optimize.minimize). Because our theory tells us that the loss function is convex, we know that the value of \(\mathbf{w}\) we have found is the best possible, in the sense of minimizing the loss.
Let’s take a look at the separating line we found:
draw_line(LR.w, X, y,
x_min = -0.5,
x_max = 1.5,
ax = ax,
color = "black",
linestyle = "dashed")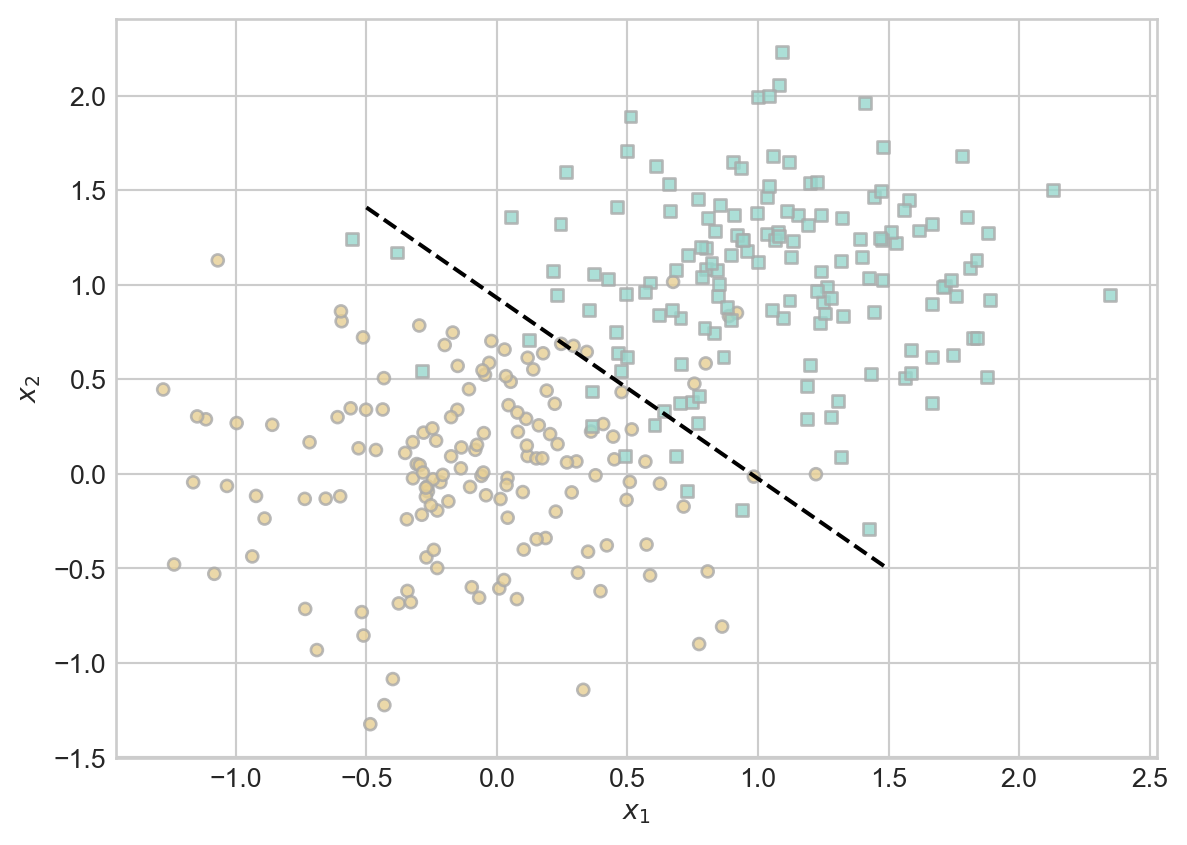
Yep, that’s the same line as we found earlier!
Although our data is not linearly separable, the separating line we have learned appears to do a reasonable job of separating the points from each other. Let’s check our accuracy:
(1.0*(LR.predict(X) == y)).mean()tensor(0.9200)
© Phil Chodrow, 2025