In this set of notes, we begin our study of language models with two key concepts: tokens, the building blocks of sequence data, and embeddings, the vector representations of those tokens that allow us to apply machine learning techniques to them. By the end of these notes, we’ll have implemented and trained one standard embedding model using a small text data set.
Code
import torch from torch import nndevice = torch.device("cuda"if torch.cuda.is_available() else"cpu")import urllibimport pandas as pdfrom sklearn.manifold import TSNEfrom matplotlib import pyplot as plt# for appearanceimport plotly.express as pximport plotly.io as piopio.templates.default ="plotly_white"import sys if"google.colab"in sys.modules:!pip install torchinfo pio.renderers.default ='colab'else: pio.renderers.default ="notebook_connected"from torchinfo import summary
Our example for this lecture will be a combined corpus of the complete text of several books by Dr. Seuss, including Green Eggs and Ham, The Cat in the Hat, Fox in Socks, and How The Grinch Stole Christmas. The text is available online, and we can load it directly into Python using urllib.
url ="https://raw.githubusercontent.com/PhilChodrow/ml-notes-update/refs/heads/main/data/seuss.txt"text ="\n".join([line.decode('utf-8').strip() for line in urllib.request.urlopen(url)])
Here is an excerpt from the text:
print(text[0:132])
The Cat in the Hat
By Dr. Seuss
The sun did not shine.
It was too wet to play.
So we sat in the house
All that cold, cold, wet day
Tokenization
Our first order of business is to represent the text in standardized form which we can eventually feed into models. The most common approach in modern language modeling is tokenization.
Definition 15.1 (Tokenizer, Tokens, Vocabulary) A tokenizer is a map between (typically short) sequences of raw text and integer labels called tokens. The set of all tokens is called the vocabulary of the tokenizer.
It’s possible to implement and train many modern tokenizers from scratch, but for our purposes here we’ll use a pre-trained tokenizer. This particular tokenizer is the one used by the GPT-2 language model, and it is available through the transformers library.
GPT-2 preceded GPT-3, the version of GPT that became popular through ChatGPT.
from tokenizers import Tokenizerfrom transformers import AutoTokenizer, AutoModelForCausalLM# GPT2 tokenizer and modelcheckpoint ="openai-community/gpt2"tokenizer = AutoTokenizer.from_pretrained(checkpoint)
/Users/philchodrow/opt/anaconda3/envs/cs451/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Here are a few tokens from the vocabulary, along with their corresponding integer labels:
Figure 15.1: Excerpt from the vocabulary of the GPT-2 tokenizer.
You’ll notice the presence of the special character Ġ in some of the tokens. This character is used by the GPT-2 tokenizer to indicate that the token is preceded by a space in the original text. For example, the token Ġthe corresponds to the word “the” when it appears after a space, while the token the corresponds to “the” when it appears at the beginning of a string or after certain punctuation. This point is just one of many subtleties in play when creating a tokenizer that captures English text relatively faithfully.
Once we’ve created the tokenizer, we can use the encode method to convert any supplied text into a sequence of tokens.
sentence ="I do not like green eggs and ham."tokens = tokenizer.encode(sentence)token_df = pd.DataFrame({"Token": tokens})token_df["Text"] = token_df["Token"].apply(lambda x: tokenizer.decode(x))token_df.head(10)
Token
Text
0
40
I
1
466
do
2
407
not
3
588
like
4
4077
green
5
9653
eggs
6
290
and
7
8891
ham
8
13
.
We can then decode the tokens back into text:
decoded = tokenizer.decode(tokens)print(decoded)
I do not like green eggs and ham.
The complete GPT-2 tokenizer has a large vocabulary of tokens:
print("Vocabulary size:", tokenizer.vocab_size)
Vocabulary size: 50257
This is quite a bit more than the number of unique tokens which actually appear in our text data set.
tokens = tokenizer.encode(text)unique_tokens =set(tokens)print("Total number of tokens in text:", len(tokens))print("Number of unique tokens in text:", len(unique_tokens))
Token indices sequence length is longer than the specified maximum sequence length for this model (11051 > 1024). Running this sequence through the model will result in indexing errors
Total number of tokens in text: 11051
Number of unique tokens in text: 1589
Later in these notes, we’ll find it useful to distinguish tokens which are actually present in our corpus from those which are not.
Token Embedding
Token ids themselves are not usually suitable inputs for machine learning models because they aren’t semantically meaningful. The integer id is interpreted as an index rather than a quantity – for example, the token with id 100 isn’t necessarily more similar to the token with id 101 than it is to the token with id 500. To address this issue, we need to convert token ids into feature vectors that capture semantic information about the tokens. This process is called embedding.
Definition 15.2 (Token Embedding) A token embedding is a function \(f: \{1,2,\ldots,\text{vocab\_length}\} \to \mathbb{R}^d\) that maps each token id to a vector in \(\mathbb{R}^d\). The integer \(d\) is called the embedding dimension.
One-Hot Encoding
One way to convert token ids into feature vectors is to assign a unique vector to each token id via one-hot encoding.
As our first attempt to convert token ids into feature vectors, we’ll use one-hot encoding: we represent each token as a vector of zeros with a single one in the position corresponding to the token’s id.
Definition 15.3 (One-Hot Encoding) The one-hot encoding of a token id \(i\) is the vector in \(\mathbb{R}^d\) which has a one in the \(i\)-th position and zeros everywhere else.
Linear algebra fans in the room may also call this the \(i\)th standard basis vector.
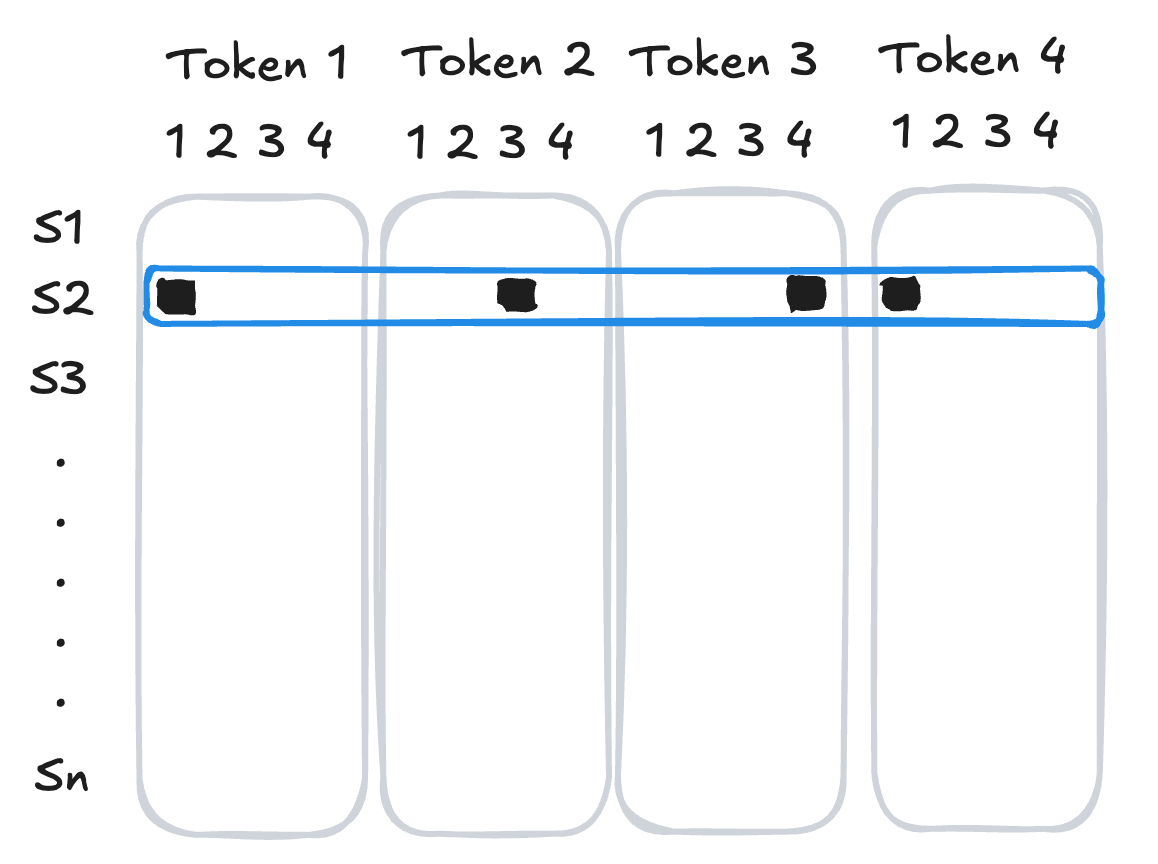
If we wanted to represent a sequence of tokens for input into a model, we could use one-hot encoding to convert each token into a vector, and then concatenate those vectors together. The result would be a feature vector of length \(d \cdot n\) for a sequence of \(n\) tokens, where \(d\) is the size of the vocabulary.
Figure 15.2: Visual illustration of one-hot encoding: the second sequence in the data set has token ids [1, 3, 4, 1].
Limitations of One-Hot Encoding
There are two important limitations to one-hot encoding tokens as a method for feature engineering.
Computational: Feature Vectors Too Large
In the previous batch of models, we associated to each token a one-hot vector of length equal to the number of distinct tokens in the vocabulary. This meant that a given sequence of length \(k\) was represented by a vector of length \(k \cdot \text{vocab\_length}\); this can quickly become impractical if we wish for either a large vocabulary or a long context length. In the case of even our short Dr. Seuss text, there are over 1,500 unique tokens. A one-hot encoding of a single token therefore requires a feature vector of length 1,500, and a sequence of 10 tokens would require a feature vector of length 15,000. This is not only computationally expensive, but also likely to lead to overfitting.
Semantic: Feature Vectors Not Meaningful
Since machine learning models are constructed from linear algebraic operations, the geometry of the feature vectors is our primary tool for expressing semantic relationships between tokens. There are a few ways to express linear algebraic relationships between vectors. A very common approach in the context of token embeddings is to use the inner product between vectors as a measure of similarity:
Since it’s possible that \(\mathbf{u}\) and \(\mathbf{v}\) might have very different magnitudes, it’s common to normalize the inner product by the magnitudes of the vectors, which gives us the cosine similarity:
Definition 15.4 (Cosine Similarity) The cosine similarity between two vectors \(\mathbf{u}\) and \(\mathbf{v}\) is defined as \[
\begin{aligned}
\text{CS}(\mathbf{u}, \mathbf{v}) = \frac{\langle \mathbf{u}, \mathbf{v} \rangle}{\lVert \mathbf{u} \rVert \lVert \mathbf{v} \rVert}\;.
\end{aligned}
\]
The cosine similarity is a number between -1 and 1, where 1 indicates \(\mathbf{u}\) and \(\mathbf{v}\) are parallel (i.e. \(\mathbf{v}= c \mathbf{u}\) for some \(c > 0\)), -1 indicates \(\mathbf{u}\) and \(\mathbf{v}\) are anti-parallel (i.e. \(\mathbf{v}= c \mathbf{u}\) for some \(c < 0\)), and 0 indicates \(\mathbf{u}\) and \(\mathbf{v}\) are orthogonal (i.e. \(\langle \mathbf{u}, \mathbf{v} \rangle = 0\)).
Cosine similarity highlights a major issue with one-hot encoding: all the feature vectors are orthogonal, which means that \(\mathrm{CS}(\mathbf{v}_i, \mathbf{v}_j) = 0\) for any two distinct tokens \(i\) and \(j\). This is a missed opportunity: for example, we might expect that the tokens “cat” and “dog” are somewhat more similar to each other than either is to “chair,” but this idea of similarity is not captured by one-hot encoding.
Learned Embeddings
Of course, we also don’t want to have to try to write down by hand what better feature vectors for our tokens would look like. So, in the usual spirit of machine learning, we can aim to learn meaningful representations of the tokens from data. There are many approaches to learning token embeddings, of which a few well-known examples are Word2Vec (Mikolov et al. 2013), GloVe (Pennington, Socher, and Manning 2014), and Continuous Bag Of Words (CBOW). In this set of notes, we’ll implement and train a simple version of the CBOW model.
These approaches are not all disjoint; for example, CBOW is one possible subroutine in the Word2Vec framework.
CBOW: Continuous Bag of Words
CBOW, like many other embedding models, learns token embeddings from a prediction task: we try to predict a target token \(t_k\) from its surrounding tokens \(t_{k-c}, \ldots, t_{k-1}, t_{k+1}, \ldots, t_{k+c}\), where \(c\) is a hyperparameter called the context length. The model learns token embeddings by learning to solve this prediction task. We’re going to consider a very simple version of the CBOW model in which we predict \(t_k\) from a single context token at a time. This means we need a data set that looks like this:
example ="I do not like green eggs and ham."example_tokens = tokenizer.encode(example)context_length =2data = []for i inrange(context_length, len(example_tokens)-context_length):for j inrange(-context_length, context_length+1):if j !=0: data.append((example_tokens[i+j], example_tokens[i]))for context, target in data:print(f"{tokenizer.decode(context):<6} --> {tokenizer.decode(target)}")
I --> not
do --> not
like --> not
green --> not
do --> like
not --> like
green --> like
eggs --> like
not --> green
like --> green
eggs --> green
and --> green
like --> eggs
green --> eggs
and --> eggs
ham --> eggs
green --> and
eggs --> and
ham --> and
. --> and
A nice feature of this data set is that it contains many examples of the same target token appearing in different contexts, which allows the model to learn a more general embedding for that token. For example, the token “green” appears in the context of “like” and “eggs,” which should help the model learn an embedding for “green” that captures its relationship to those other tokens. This also helps guard against overfitting – the model can’t just memorize the embedding for “green” based on a single context, since it appears in multiple contexts.
The following dataset class implements this data generation process for the entire example text of Dr. Seuss.
This data set also includes logic for converting the token indices from the GPT tokenizer to a contiguous integer representation which includes only indices for the tokens which are present in the data set. This allows our model later to learn embeddings for ~1,500 tokens, rather than the full vocabulary of ~50,000.
from torch.utils.data import Dataset, DataLoaderclass CBOWDataset(Dataset):def__init__(self, tokens, context_length):self.tokens = tokens# dict to remap tokens to contiguous integersself.token_to_idx = {token: i for i, token inenumerate(set(tokens))}self.idx_to_token = {i: token for token, i inself.token_to_idx.items()}# context length is the number of tokens on either side of the target tokenself.context_length = context_lengthself.data = []for i inrange(context_length, len(tokens)-context_length):for j inrange(-context_length, context_length+1):if j !=0:self.data.append((self.token_to_idx[tokens[i+j]], self.token_to_idx[tokens[i]]))self.data.append((self.token_to_idx[tokens[i+j]], self.token_to_idx[tokens[i]]))def__len__(self):returnlen(self.data)def__getitem__(self, idx):return torch.tensor(self.data[idx][0]), torch.tensor(self.data[idx][1])
We’ll solve the CBOW prediction task using a minimal feedforward network containing an embedding layer and a linear layer. The role of the embedding layer is to accept a token index \(i\) and return an embedding vector \(\mathbf{v}_i \in \mathbb{R}^d\), which is learned as part of training. These embedding vectors are then used as features for the linear layer.
Our model is relatively modest: for production contexts, we would typically use a much larger embedding dimension (\(d \geq 200\) is common), a much larger vocabulary, and a more complex model architecture for solving the prediction task.
The Embedding Layer
The following code implements a visualizer for the embedding layer. Since we are using an 8-dimensional embedding, it’s not possible to directly visualize the embedding vectors in 2-dimensional space. Instead, we can use a dimensionality reduction technique called t-SNE to project the embedding vectors down to 2 dimensions while preserving their relative distances as much as possible.
def visualize_embeddings(model, tokenizer, data):# extract the embedding weights weights = model.embeddings.weight# use t-SNE to reduce the dimensionality of the embeddings to 2D tsne = TSNE(n_components=2, random_state=42) embeddings_2d = tsne.fit_transform(weights.detach().cpu().numpy())# make a dataframe for plotly embedding_df = pd.DataFrame(embeddings_2d, columns=["Dim1", "Dim2"]) embedding_df["Token"] = [tokenizer.decode(data.idx_to_token[i]) for i inrange(len(embeddings_2d))]# labeled scatter plot of the embeddings fig = px.scatter(embedding_df, x="Dim1", y="Dim2", text="Token", title="2D Visualization of Token Embeddings") fig.update_traces(textposition='top center') fig.update_layout(xaxis_title="Dimension 1", yaxis_title="Dimension 2") fig.show()
Let’s take a look.
visualize_embeddings(model, tokenizer, data)
Figure 15.3: Token embeddings in the CBOW model prior to training, reduced from 8 dimensions to 2 dimensions using t-SNE.
The embeddings appear random and uninteresting – natural, since we haven’t actually trained the model yet.
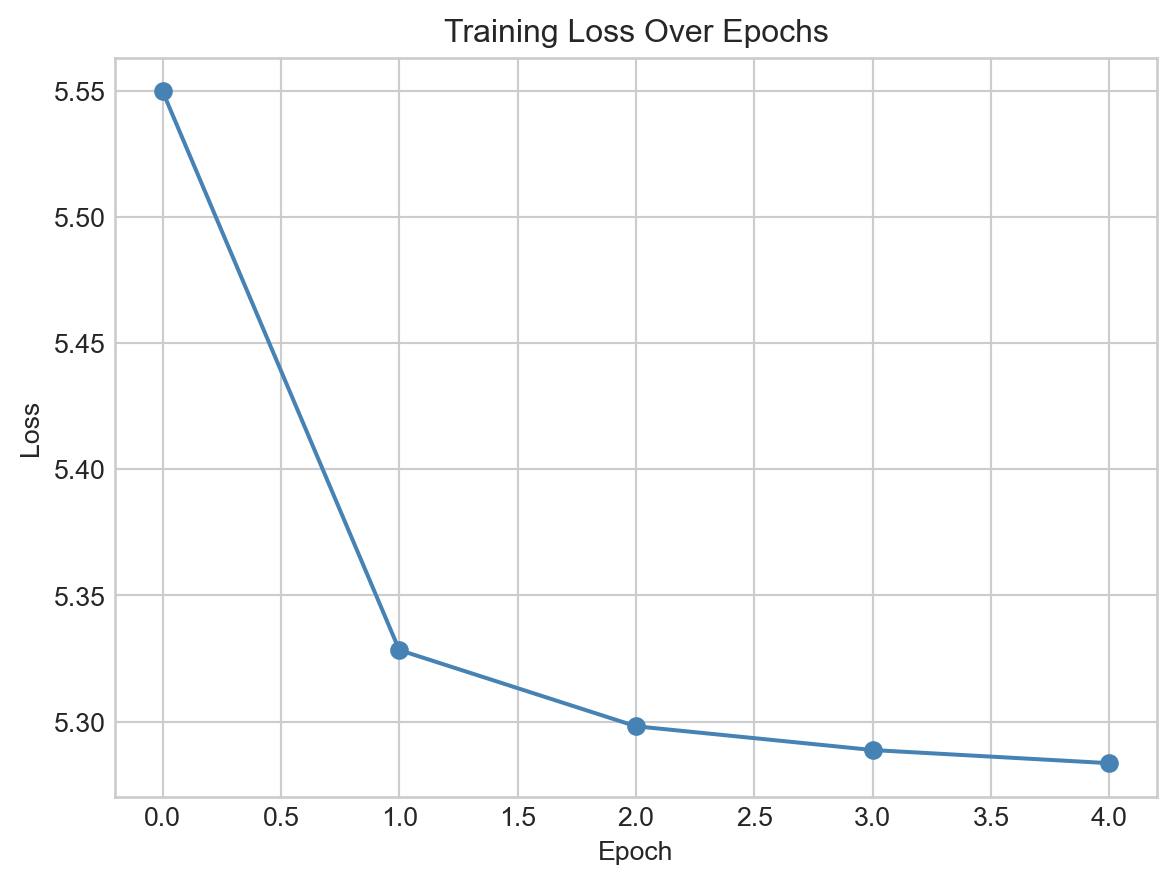
Now let’s go ahead and train our model, which we can do using a typical optimization loop. Since this is again a classification problem, we’ll use cross-entropy loss.
for epoch inrange(5): total_loss =0for X_batch, y_batch in dataloader: X_batch, y_batch = X_batch.to(device), y_batch.to(device) opt.zero_grad() output = model(X_batch) loss = loss_fn(output, y_batch) loss.backward() opt.step() total_loss += loss.item() loss_history.append(total_loss /len(dataloader))
Because each token appears in multiple contexts, we it’s not possible to learn a single good prediction for any individual token. An implication of this is that we shouldn’t expect to drive the loss anywhere close to 0 – the best we can do is to learn an embedding that captures something like the average context for each token.
Code
fig, ax = plt.subplots()ax.plot(loss_history, marker='o', color ="steelblue")ax.set_title("Training Loss Over Epochs")ax.set_xlabel("Epoch")ax.set_ylabel("Loss")plt.show()
Figure 15.4: Cross-entropy loss on the training set for the CBOW model.
It’s often sufficient to train these models for only a few epochs in order to learn interesting embeddings.
visualize_embeddings(model, tokenizer, data)
Figure 15.5: 2-dimensional visualization of the token embeddings after training. Note: This figure is interactive – playing around is encouraged. Several clusters within the embedding space reflect words which rhyme or which have other similarities, such as “beetle,” “bottle,” and “battle” from Fox in Socks.
Studying Embeddings
Recall that we can use the cosine similarity to study relationships between tokens. Let’s compare cosine similarities between Fox (from Fox in Socks) and several other tokens:
base_token ="Fox"comparison_tokens = [" socks", # from Fox in Socks" box", # from Fox in Socks" broom", # from Fox in Socks" ham", # from Green Eggs and Ham" Christmas", # from How the Grinch Stole Christmas" hat"# from The Cat in the Hat ]for token in comparison_tokens: idx = data.token_to_idx[tokenizer.encode(token)[0]] embedding = model.embeddings.weight[idx]print(f"Cosine similarity between '{base_token}' and '{token}': {cosine_similarity(model.embeddings.weight[data.token_to_idx[tokenizer.encode(base_token)[0]]], embedding):.4f}")
Cosine similarity between 'Fox' and ' socks': 0.9744
Cosine similarity between 'Fox' and ' box': 0.9499
Cosine similarity between 'Fox' and ' broom': 0.6726
Cosine similarity between 'Fox' and ' ham': 0.5024
Cosine similarity between 'Fox' and ' Christmas': -0.5595
Cosine similarity between 'Fox' and ' hat': -0.2585
We observe that the similarity between Fox and the tokens which appear in the same story (i.e. nearby) is larger that between Fox and common tokens from the other Dr. Seuss texts on which we trained. This grouping may be helpful in downstream learning tasks; for example, a model which aims to predict which Dr. Seuss book a given sentence came from could make use of the fact that socks and box are similarly predictive of Fox in Socks; this similarity could allow us to reduce the parameter count and guard against overfitting.
References
Mikolov, Tomas, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. “Distributed Representations of Words and Phrases and Their Compositionality.”Advances In Neural Information Processing Systems 26.
Pennington, Jeffrey, Richard Socher, and Christopher D. Manning. 2014. “GloVe: Global Vectors for Word Representation.” In Empirical Methods in Natural Language Processing (EMNLP), 1532–43.