4 Features and Regularization
Our first look at methods for using and controlling model complexity
Open the live notebook in Google Colab.
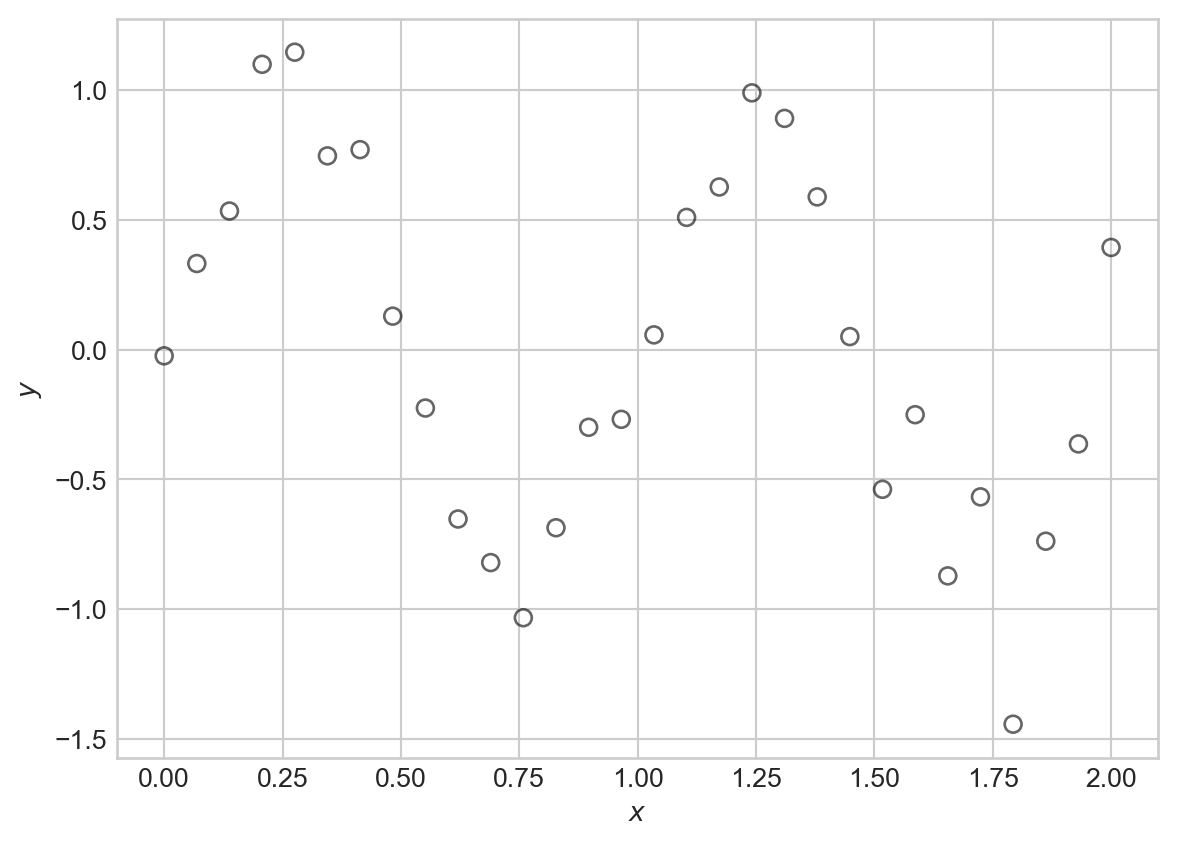
Suppose that we’d like to model a distinctly nonlinear relationship in our data:
Code
import torch
from matplotlib import pyplot as plt
scatterplot_kwargs = dict(color = "black", label = "data", facecolors = "none", s = 40, alpha = 0.6)
sig = 0.2
X = torch.linspace(0, 2, 30).reshape(-1, 1)
signal = torch.sin(2*torch.pi*X)
noise = sig*torch.randn(X.shape)
y = signal + noise
fig, ax = plt.subplots()
ax.scatter(X.numpy(), y.numpy(), **scatterplot_kwargs)
plt.xlabel(r"$x$")
t = plt.ylabel(r"$y$")One flexible candidate model for this kind of data is a nonlinear Gaussian model:
Definition 4.1 A nonlinear Gaussian model with mean function \(f\) and variance \(\sigma^2\) is a probabilistic model for data \((\mathbf{x}_i, y_i)_{i=1}^n\) such that
\[ \begin{aligned} y_i \sim \mathcal{N}(f(\mathbf{x}_i); \sigma^2)\;. \end{aligned} \]
That is, each target value \(y_i\) has Gaussian distribution with a mean (or signal) given by \(f(\mathbf{x}_i)\) and variance (or noise level) \(\sigma^2\).
Here’s a visualization of this model with \(f(x) = \sin(2\pi x)\) and \(\sigma^2 = 0.01\), which was the setting used to generate the synthetic data above:
Code
def draw_gaussian_at(support, sd=1.0, height=1.0,
xpos=0.0, ypos=0.0, ax=None, **kwargs):
if ax is None:
ax = plt.gca()
gaussian = torch.exp((-support ** 2.0) / (2 * sd ** 2.0))
gaussian /= gaussian.max()
gaussian *= height
return ax.plot(gaussian + xpos, support + ypos, **kwargs)
support = torch.linspace(-0.3, 0.3, 1000)
fig, ax = plt.subplots()
ax.plot(X.numpy(), torch.sin(2*torch.pi*X).numpy(), color = "black", linestyle = "--", label = r"Signal: $f(x_i) = \sin(2\pi x_i)$")
for each in X:
draw_gaussian_at(support, sd=sig, height=0.1, xpos=each, ypos=torch.sin(2*torch.pi*each), ax=ax, color='C0', alpha=0.4)
ax.scatter(X.numpy(), y.numpy(), **scatterplot_kwargs)
plt.xlabel(r"$x$")
plt.ylabel(r"$y$")
plt.title("Data generated from a nonlinear Gaussian model")
plt.legend()
plt.show()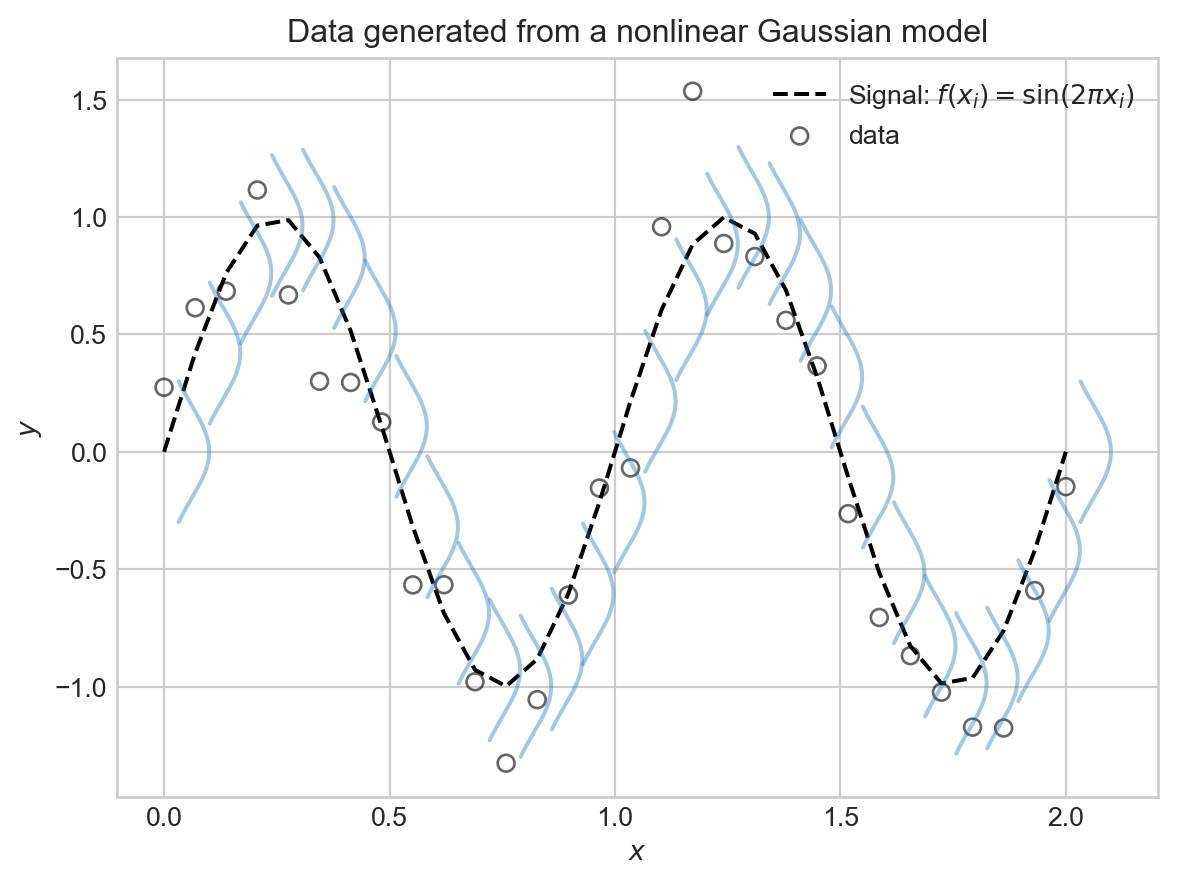
This is all well and good as a theoretical framework, but how in the world were we supposed to know that \(f(x) = \sin(2\pi x)\) was the right choice? In practice, of course, we never will.
Basis Function Expansion
Since we don’t know the right functional form for \(f\), one common approach is try to approximate
\[ \begin{aligned} f(\mathbf{x}) \approx w_0\phi_0(\mathbf{x}) + w_1 \phi_1(\mathbf{x}) + w_2 \phi_2(\mathbf{x}) + \cdots + w_p \phi_p(\mathbf{x}) = \sum_{j=0}^p w_j \phi_j(\mathbf{x})\;, \end{aligned} \] where \(\phi_j(\cdot)\) are a collection of basis functions that we choose ahead of time. This is called a basis function expansion.
Each \(\phi_j\) is often also called a feature map.
Before we look at some examples of basis functions, let’s take a look at the fundamental trick behind basis function expansions: when using a basis function expansion with a nonlinear Gaussian model, the model is linear in the parameters \(w_j\), and we can therefore use our previously-developed machinery for linear regression to fit the model. To see this, note that we can write
\[ \begin{aligned} \sum_{j=0}^p w_j \phi_j(\mathbf{x}) = \mathbf{w}^T \mathbf{\phi}(\mathbf{x})\;, \end{aligned} \]
where we’ve defined the vector of parameters \(\mathbf{w}= (w_0, w_1, \ldots, w_p)^T\) and the vector of basis functions \(\mathbf{\phi}(\mathbf{x}) = (\phi_0(\mathbf{x}), \phi_1(\mathbf{x}), \ldots, \phi_p(\mathbf{x}))^T\). Let’s give the shorthand \(\hat{y}_i = \mathbf{w}^T \mathbf{\phi}(\mathbf{x}_i)\) for the prediction of the model at input \(\mathbf{x}_i\). Then, taken together the nonlinear Gaussian model with basis function expansion says that
\[ \begin{aligned} y_i \sim \mathcal{N}(\hat{y}_i; \sigma^2) = \mathcal{N}(\mathbf{w}^T \mathbf{\phi}(\mathbf{x}_i); \sigma^2)\;. \end{aligned} \]
This is just like the linear-Gaussian model, but with the input data \(\mathbf{x}_i\) replaced by the transformed data \(\mathbf{\phi}(\mathbf{x}_i)\). Therefore, we can use our previous results for maximum likelihood estimation of the parameters \(\mathbf{w}\) in the linear-Gaussian model, simply by replacing each occurrence of \(\mathbf{x}_i\) with \(\mathbf{\phi}(\mathbf{x}_i)\). In particular, we can maximize the log-likelihood of the data by minimizing the mean squared error between the predictions \(\hat{y}_i\) and the observed targets \(y_i\):
\[ \begin{aligned} R(\mathbf{X}, \mathbf{y}; \mathbf{w}) = \frac{1}{n} \sum_{i=1}^n (y_i - \mathbf{w}^T \mathbf{\phi}(\mathbf{x}_i))^2\;. \end{aligned} \]
If we define
\[ \begin{aligned} \mathbf{\Phi}= \left[\begin{matrix} - &\mathbf{\phi}(\mathbf{x}_1)^T & -\\ - &\mathbf{\phi}(\mathbf{x}_2)^T & -\\ \vdots \\ - &\mathbf{\phi}(\mathbf{x}_n)^T & - \end{matrix}\right]\;, \end{aligned} \]
we can similarly write the mean squared error in matrix form as
\[ \begin{aligned} R(\mathbf{\Phi}, \mathbf{y}; \mathbf{w}) = \frac{1}{n} \lVert \mathbf{\Phi}\mathbf{w}- \mathbf{y} \rVert^2\;. \end{aligned} \]
So, to learn a model with basis function expansion, all we need to do is construct the feature matrix \(\mathbf{\Phi}\) by applying the basis functions to each data point, and then run linear regression as before.
Let’s try basis function expansion on our synthetic data. For this, we’ll first bring in the linear regression model that we developed previously:
class LinearRegression:
def __init__(self, n_params):
self.w = torch.zeros(n_params, 1, requires_grad=True)
def forward(self, X):
return X @ self.wWe’ll also write a simple training loop, this time using some of PyTorch’s built-in optimization functionality: rather than implement our own GradientDescentOptimizer class today, we’ll instead use the torch.optim.Adam optimizer. This enables faster training, which will help us for the experiments in these notes.
def mse(y_pred, y):
return torch.mean((y_pred - y) ** 2)
def train_model(model, X_train, y_train, lr=1e-2, n_epochs=1000, tol=1e-4, regularization = None, verbose = False):
opt = torch.optim.Adam(params=[model.w], lr=lr)
for epoch in range(n_epochs):
y_pred = model.forward(X_train)
1 loss = mse(y_pred, y_train) + (regularization(model.w) if regularization is not None else 0.0)
opt.zero_grad()
loss.backward() #<2> automated computation of gradients for Adam optimization
opt.step() #<3> perform an optimization step
if model.w.grad is not None:
if model.w.grad.norm().item() < tol:
if verbose:
print(f"Converged at epoch {epoch}, Loss: {loss.item()}")
break
if verbose and epoch % 100 == 0:
print(f"Epoch {epoch}, Loss: {loss.item()}")- 1
- This function adds a regularization term (introduced below) to the loss if provided.
It’s helpful to think about the minimal linear regression model, in which we simply add a constant column to the data, as an example of a basis function expansion. We’ll call this the linear basis function.
def linear_basis_function(X):
"""
just adds the constant feature
"""
n_samples = X.shape[0]
Phi = torch.ones(n_samples, 2) # intercept + linear term
Phi[:, 1] = X.flatten()
return PhiIf we try fitting this model to the sinusoidal data directly, we’ll be disappointed.
PHI = linear_basis_function(X)
LR = LinearRegression(n_params=2) # intercept + slope
train_model(LR, PHI, y, lr=1e-2, n_epochs=1000)Code
# utility function for model visualization
def viz_model_predictions(model, X, y, basis_fun, ax, **basis_fun_kwargs):
x_new = torch.linspace(X.min(), X.max(), 1000).reshape(-1, 1)
PHI_new = basis_fun(x_new, **basis_fun_kwargs)
y_pred = model.forward(PHI_new)
ax.scatter(X.numpy(), y.numpy(), **scatterplot_kwargs)
ax.plot(x_new.numpy(), y_pred.detach().numpy(), color='red', label='Prediction')
ax.set_xlabel(r"$x$")
ax.set_ylabel(r"$y$")How did we do?
fig, ax = plt.subplots()
viz_model_predictions(LR, X, y, basis_fun = linear_basis_function, ax=ax)
plt.title("Linear Regression Fit to Nonlinear Data")
plt.legend()
plt.show()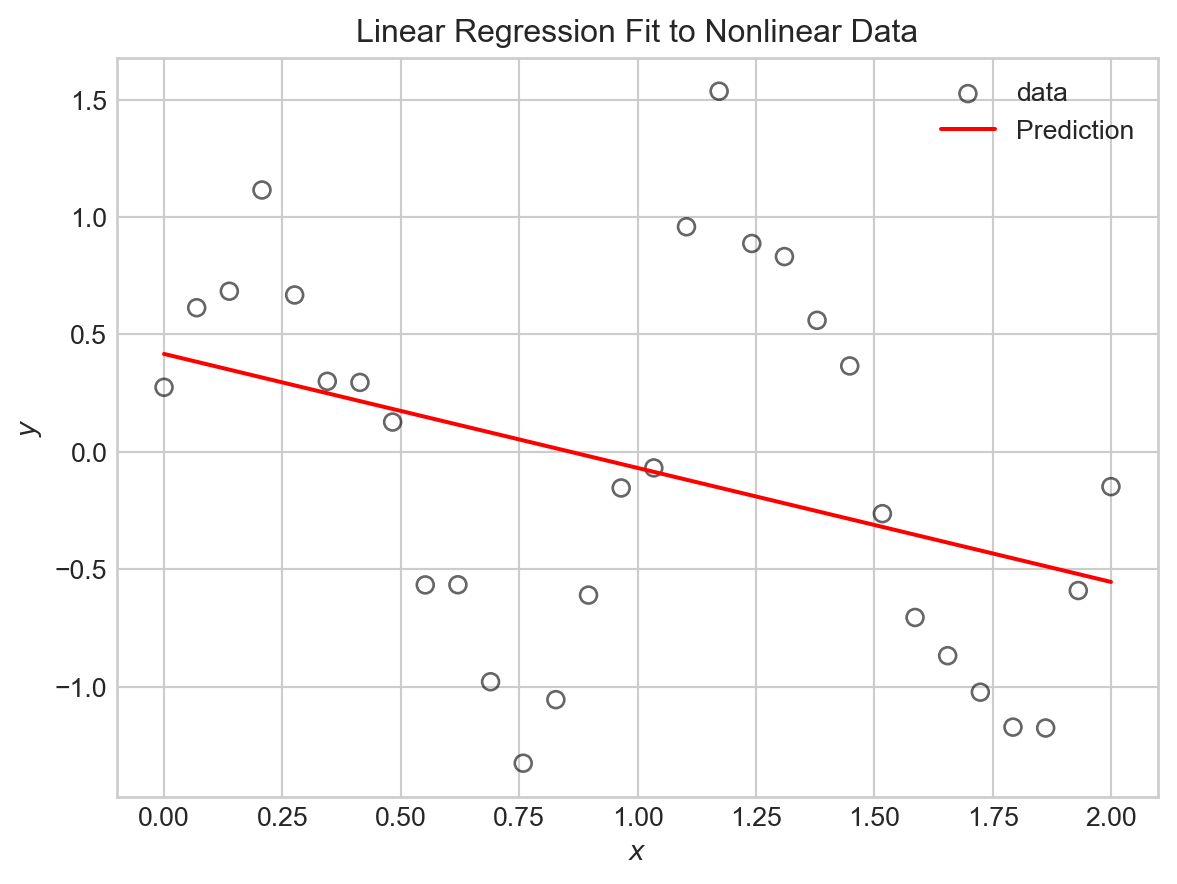
Now let’s try some nontrivial basis function expansions. If we had reason to believe that our data was periodic, we might try using sine and cosine basis functions. For example, let’s try:
\[ \begin{aligned} \phi_0(x) &= 1\;,\\ \phi_1(x) &= \sin(\pi x)\;,\\ \phi_2(x) &= \sin(2 \pi x)\;,\\ \phi_3(x) &= \sin(3 \pi x)\;,\\ \vdots \end{aligned} \]
The following function constructs the feature matrix \(\mathbf{\Phi}\) for this basis function expansion:
def sinusoidal_features(X, max_freq=4):
n_samples = X.shape[0]
Phi = torch.ones(n_samples, max_freq + 1)
for i in range(1, max_freq + 1):
Phi[:, i] = torch.sin(i * torch.pi * X).flatten()
return PhiTo train models and make predictions, all we need to do is call this function to get the feature matrix, and then run linear regression as before.
# engineer features
max_freq = 15
PHI = sinusoidal_features(X, max_freq=max_freq)
# train the model as usual
LR = LinearRegression(n_params=PHI.shape[1])
train_model(LR, PHI, y, lr=1e-2, n_epochs=2000)Code
# visualize
fig, ax = plt.subplots()
viz_model_predictions(LR, X, y, basis_fun = sinusoidal_features, ax=ax, max_freq=max_freq)
plt.title(f"Sinusoidal Basis Functions with max_freq={max_freq}")
plt.legend()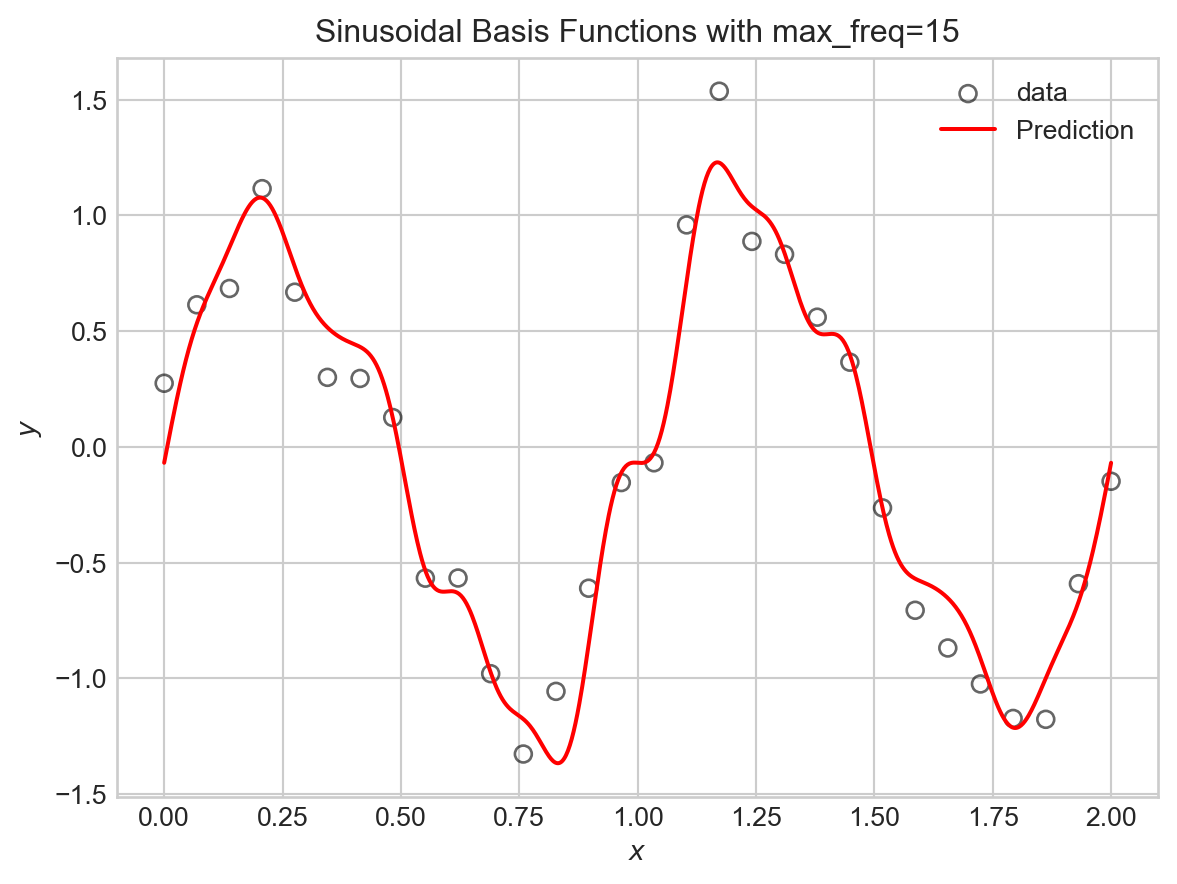
Let’s try this for a variety of maximum frequencies.
Code
fig, axarr = plt.subplots(2, 3, figsize=(8,5))
max_freqs = [0, 1, 2, 5, 10, 20]
for i, ax in enumerate(axarr.flatten()):
PHI = sinusoidal_features(X, max_freq=max_freqs[i])
LR = LinearRegression(n_params=PHI.shape[1])
train_model(LR, PHI, y, lr=1e-2, n_epochs=2000)
viz_model_predictions(LR, X, y, basis_fun = sinusoidal_features, ax=ax, max_freq=max_freqs[i])
mse_val = mse(LR.forward(PHI), y).item()
ax.set_title(f"max_freq={max_freqs[i], } | MSE={mse_val:.3f}")
if i == 0:
ax.legend()
plt.tight_layout()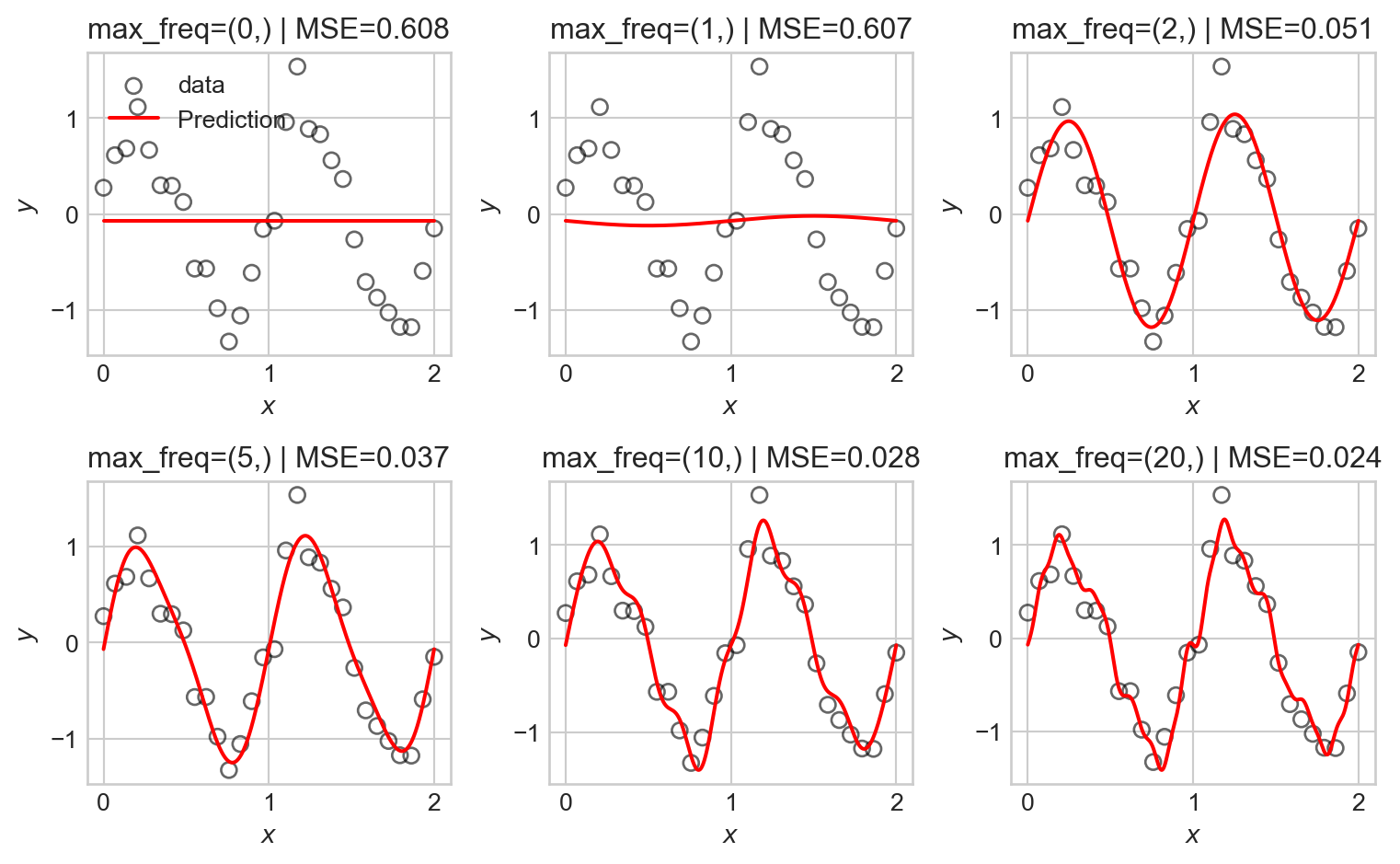
As the number of basis functions increases, the model becomes more flexible and is able to better fit the training data. However, with too many basis functions, the model begins to overfit the data, capturing noise rather than the underlying signal as reflected in the seemingly random high-frequency oscillations in the predictions.
Kernel Basis Functions
Another common choice of basis functions are kernel basis functions. A kernel is simply a measure of similarity between two inputs. A common choice is the Gaussian radial-basis kernel, which is defined in one dimension by
\[ k(x, c) = \exp\left(-(x - c)^2\right)\;, \]
The Guassian kernel measures similarity between \(x\) and a center point \(c\), with values close to 1 when \(x\) is near \(c\) and values close to 0 when \(x\) is far from \(c\).
Here’s an implementation in one dimension, where we evenly space choices of \(c\) out across the range of the data:
def kernel_features(X, num_kernels):
n_samples = X.shape[0]
Phi = torch.ones(n_samples, num_kernels + 1)
centers = torch.linspace(X.min(), X.max(), num_kernels)
bandwidth = (X.max() - X.min()) / num_kernels
for j in range(num_kernels):
Phi[:, j + 1] = torch.exp(-0.5 * ((X.flatten() - centers[j]) / bandwidth) ** 2)
return PhiWe can now run the same experiment as before:
Code
fig, axarr = plt.subplots(2, 3, figsize=(8,5))
num_kernels = [0, 3, 5, 10, 20, 30]
for i, ax in enumerate(axarr.flatten()):
PHI = kernel_features(X, num_kernels=num_kernels[i])
LR = LinearRegression(n_params=PHI.shape[1])
train_model(LR, PHI, y, lr=1e-2, n_epochs=200000, tol = 1e-4)
viz_model_predictions(LR, X, y, basis_fun = kernel_features, ax=ax, num_kernels=num_kernels[i])
mse_val = mse(LR.forward(PHI), y).item()
ax.set_title(f"num_kernels={num_kernels[i]} | MSE={mse_val:.3f}")
if i == 0:
ax.legend()
plt.tight_layout()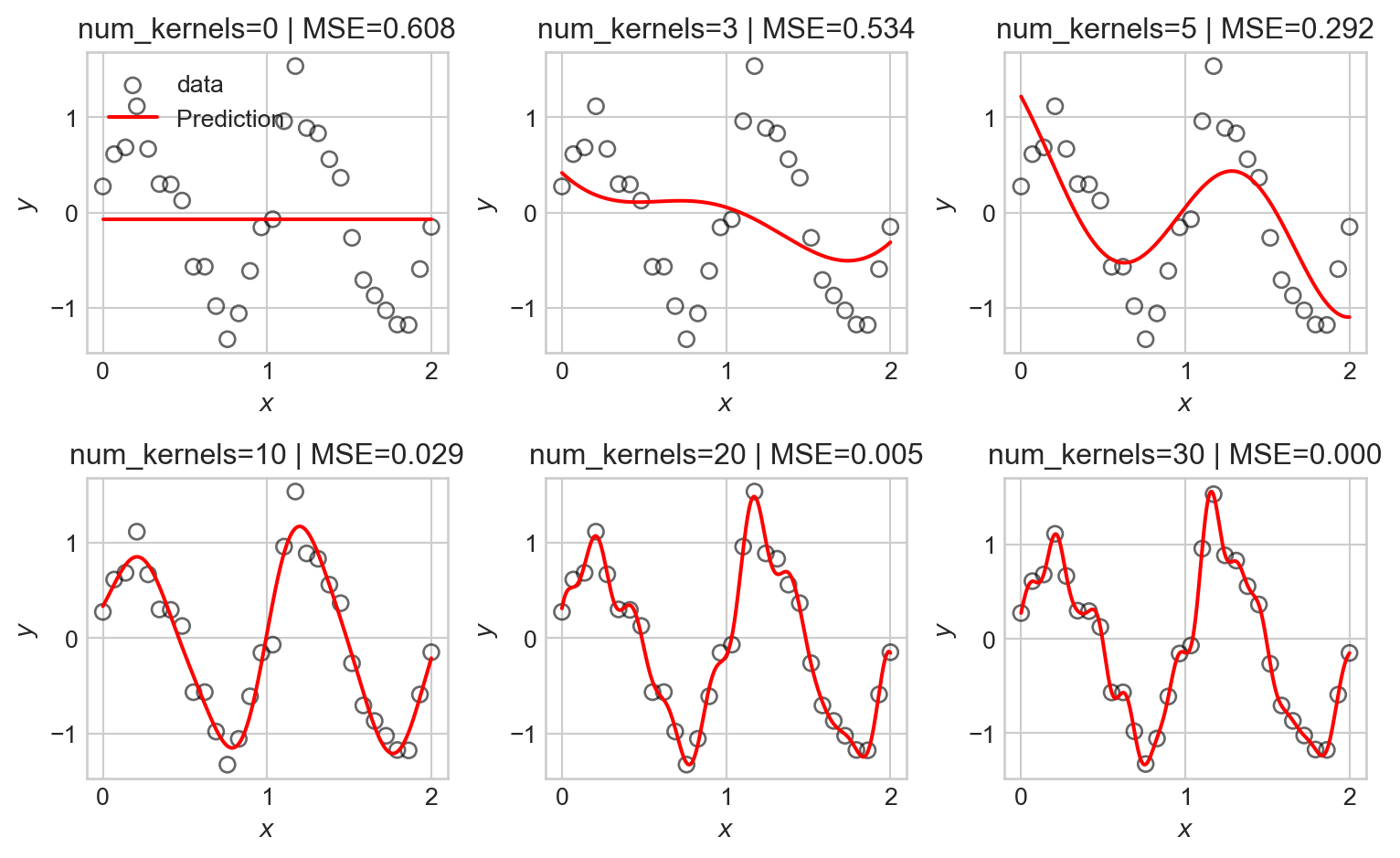
As before, we observe that as the number of basis functions increases, the model becomes more flexible and is able to better fit the training data, but eventually begins to overfit.
Regularization
We now find ourselves in a bit of a dilemma – we’d like to use flexible models with many basis functions to capture nonlinear patterns in data, but introducing flexibility raises the risk of overfitting. One approach is to simply restrict which basis functions we’ll use, but this is unsatisfying: how will we know ahead of time which basis functions are best?
An alternative approach is to use regularization. Regularization works by encouraging our models to maintain small entries in the parameter vector \(\mathbf{w}\). This effectively allows us to use many basis functions, but penalizes the model for emphasizing any one of them too heavily.
Typical regularization schemes work by adding a penalty term to the loss function (e.g. the MSE). For example, in ridge regression, we add a penalty proportional to the squared \(\ell_2\) norm of the parameter vector:
\[ \begin{aligned} \hat{\mathbf{w}} = \mathop{\mathrm{arg\,min}}_\mathbf{w}\left\{ \frac{1}{n} \lVert \mathbf{\Phi}\mathbf{w}- \mathbf{y} \rVert^2 + \lambda \lVert \mathbf{w} \rVert^2 \right\}\;, \end{aligned} \]
where \(\lambda\) is a hyperparameter that controls the strength of the regularization. Larger values of \(\lambda\) encourage smaller parameter values, while smaller values allow the model to fit the data more closely.
We can implement ridge regression by adding an \(\ell_2\) regularization term to our training loop. We’ll first just implement that term itself:
def ell_2_regularization(w):
return torch.mean(w[1:]**2)The reason for excluding the first entry of \(w\) from the regularization term is that this entry corresponds to the intercept term, which we typically don’t want to penalize. We then pass this function in to the regularization argument of train_model, where flagged line <1> adds the regularization term to the loss. We train again and visualize the results as we vary the regularization strength, this time keeping the maximum frequency of the sinusoidal basis functions fixed at 20:
Code
fig, axarr = plt.subplots(2, 3, figsize=(8,5))
reg_strengths = torch.logspace(0, 1.5, 6)
for i, ax in enumerate(axarr.flatten()):
PHI = sinusoidal_features(X, max_freq=20)
LR = LinearRegression(n_params=PHI.shape[1])
train_model(LR, PHI, y, lr=1e-2, n_epochs=200000, tol = 1e-4, regularization = lambda w: reg_strengths[i]*ell_2_regularization(w))
viz_model_predictions(LR, X, y, basis_fun = sinusoidal_features, ax=ax, max_freq=20)
ax.set_title(f"reg_strength={reg_strengths[i]:.2f}")
if i == 0:
ax.legend()
plt.tight_layout()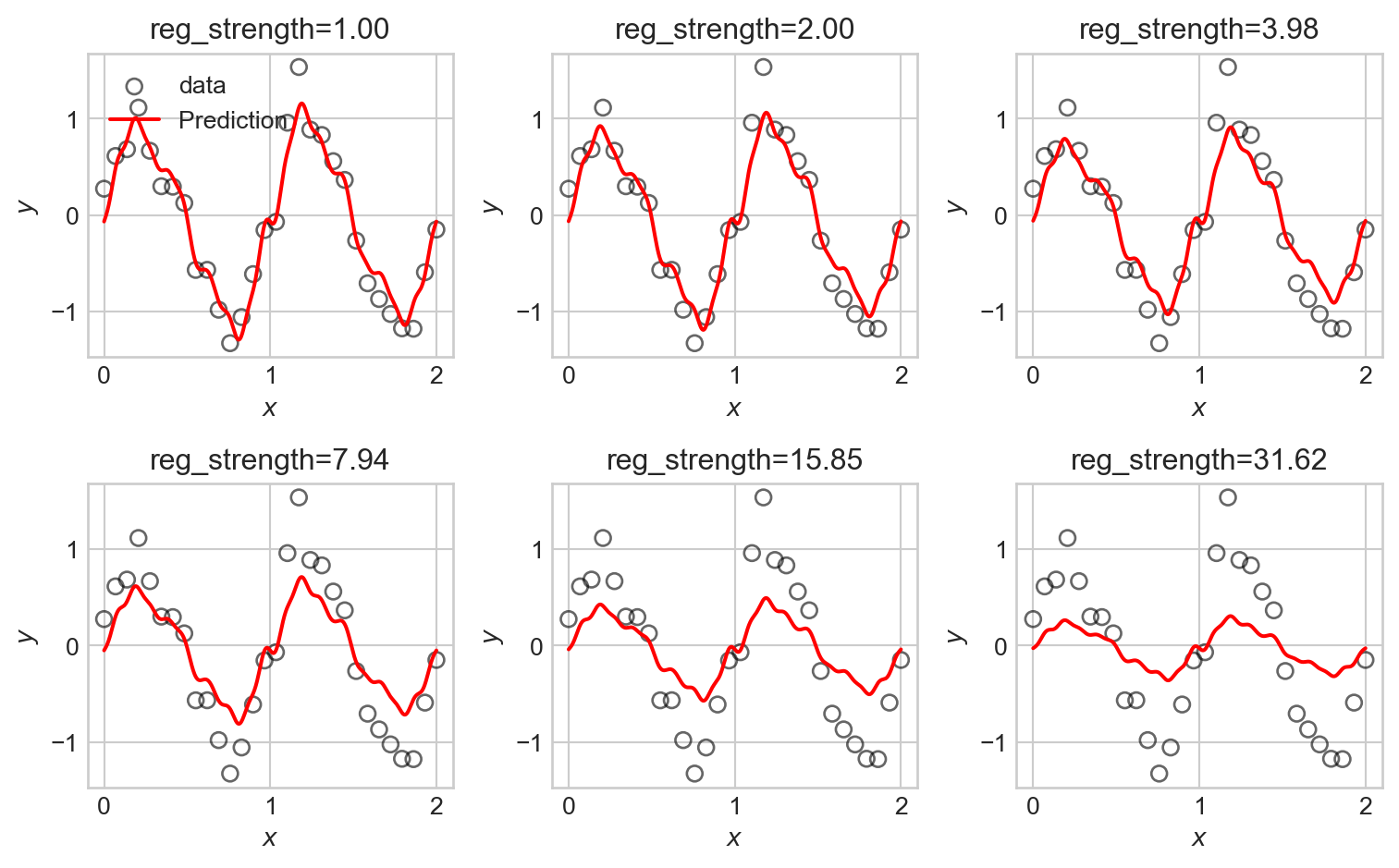
We observe that the tendency of \(\ell_2\) regularization in this setting is to “shrink” the coefficients of the basis functions toward zero. This makes the predictions somewhat smoother, but also just makes them smaller, eventually leaving them systematically smaller than the data in magnitude.
An alternative regularization is \(\ell_1\) regularization, in which we penalize the absolute values of the parameters rather than their squares. This gives us a version of regression commonly called lasso regression:
\[ \begin{aligned} \hat{\mathbf{w}} = \mathop{\mathrm{arg\,min}}_\mathbf{w}\left\{ \frac{1}{n} \lVert \mathbf{\Phi}\mathbf{w}- \mathbf{y} \rVert^2 + \lambda \sum_{j=1}^p |w_j| \right\}\;. \end{aligned} \]
We can implement \(\ell_1\) regularization similarly to before:
def ell_1_regularization(w):
return torch.mean(torch.abs(w[1:])) # exclude intercept from regularizationNow we can run the same experiment:
Code
fig, axarr = plt.subplots(2, 3, figsize=(8,5))
reg_strengths = torch.logspace(0, 1.5, 6)
for i, ax in enumerate(axarr.flatten()):
PHI = sinusoidal_features(X, max_freq=20)
LR = LinearRegression(n_params=PHI.shape[1])
train_model(LR, PHI, y, lr=1e-2, n_epochs=20000, tol = 1e-4, regularization = lambda w: reg_strengths[i]*ell_1_regularization(w))
viz_model_predictions(LR, X, y, basis_fun = sinusoidal_features, ax=ax, max_freq=20)
ax.set_title(f"reg_strength={reg_strengths[i]:.2f}")
if i == 0:
ax.legend()
plt.tight_layout()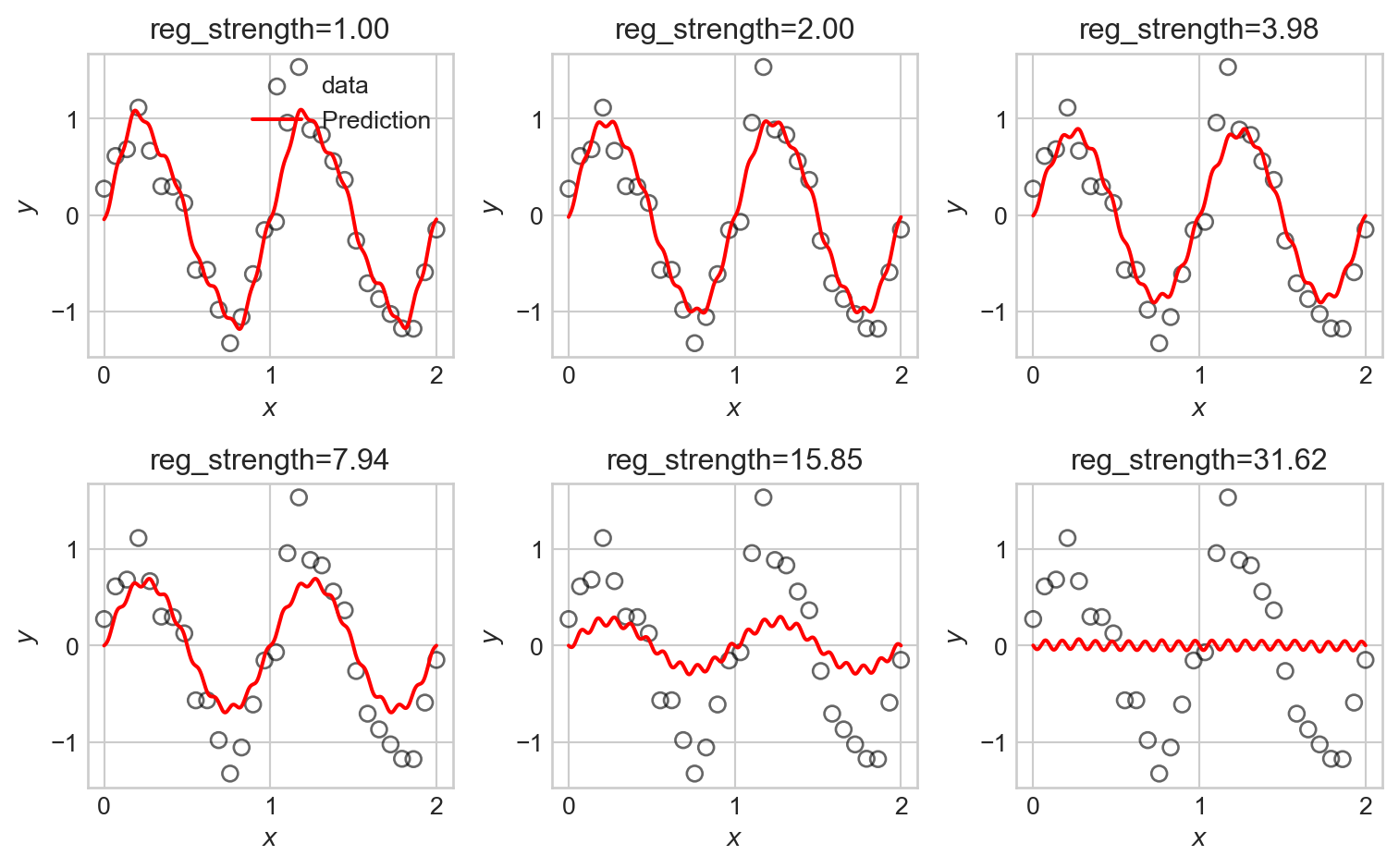
LASSO is somewhat more difficult to fit in computational terms, resulting in longer computation times. We observe that some of the LASSO fits manage to highlight the underlying trend in the data relatively well, with somewhat less systematic underfitting when compared to the ridge regression fits.
An important and useful property of LASSO is that it tends to set many of the coefficients exactly to zero, effectively performing feature selection. This can be useful when we have a large number of basis functions, as it allows us to identify which ones are most important for modeling the data. Let’s take a look at the coefficients learned by a LASSO model with moderate regularization strength:
Features with coefficients of 0 are effectively thrown away from the model.
Code
LR = LinearRegression(n_params=PHI.shape[1])
train_model(LR, PHI, y, lr=1e-4, n_epochs=50000, tol = 1e-4, regularization = lambda w: 1.0*ell_1_regularization(w))
freqs = range(PHI.shape[1]-1)
zeros = torch.abs(LR.w) <= 1e-2
fig, ax = plt.subplots()
ax.scatter(freqs, LR.w.detach().numpy()[:-1], c = zeros.numpy()[:-1], cmap='Greys_r', edgecolors='black')
ax.set_xlabel("Sinusoidal frequency")
ax.set_ylabel("Coefficient value")
t = plt.title("Lasso Regression Coefficients (white = zeroed out)")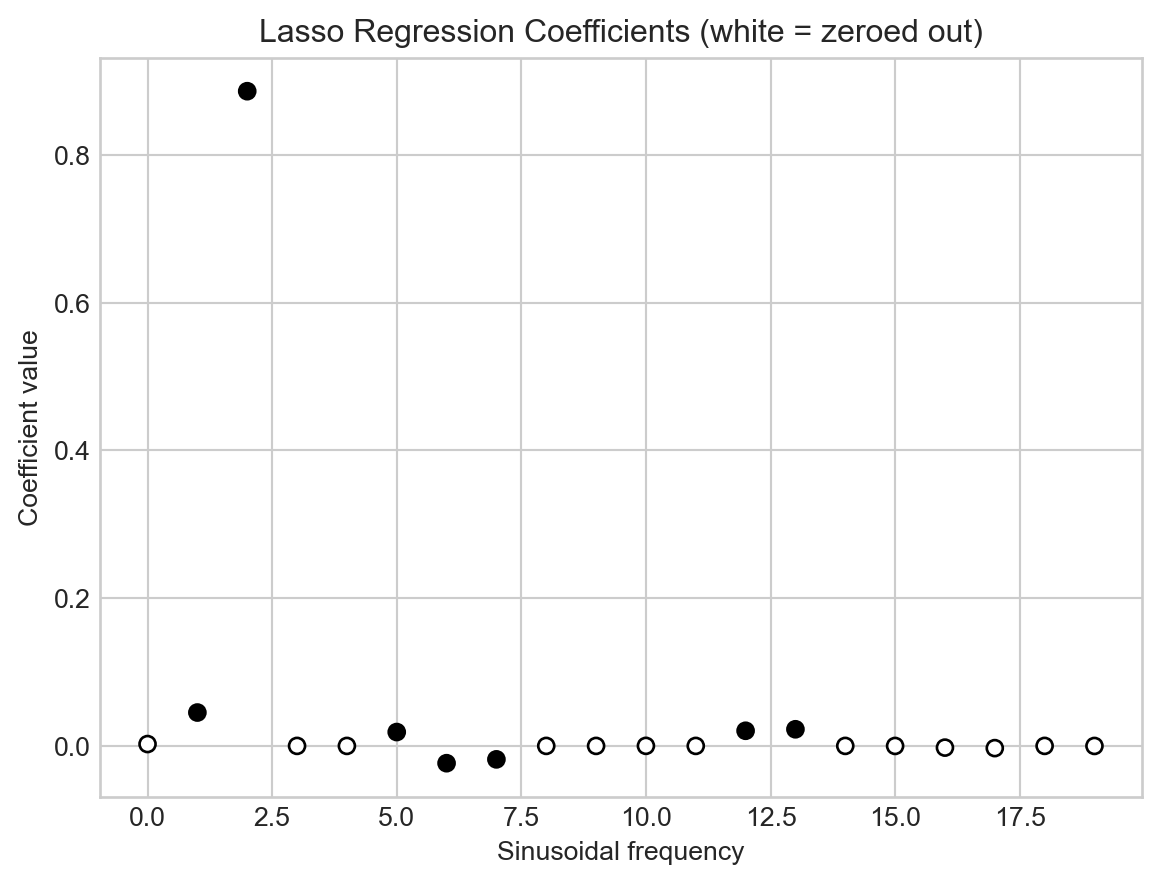
Why does LASSO regularization tend to set weights exactly to 0? The intuition here lies with the geometry of the regularization penalty. The \(\ell_2\) penalty has circular contours, while the \(\ell_1\) penalty has diamond-shaped contours. There is therefore a possibility for the contours of the loss function to intersect with the corners of the \(\ell_1\) penalty, which correspond to points where one or more coefficients are exactly zero. \(\ell_2\) regularization, on the other hand, has no corners, so the contours of the loss function will almost never intersect with points where coefficients are exactly zero. Figure 4.10 illustrates this intuition.
Code
W0 = torch.linspace(-1, 2, 301)
W1 = torch.linspace(-1, 2, 301)
W0, W1 = torch.meshgrid(W0, W1)
x = torch.tensor([[8.0, 2.0], [2.0, 1.0], [5.0, 3.0]])
y = torch.tensor([[5.0], [1.0], [3.0]])
def compute_loss(w0, w1, x, y):
w = torch.stack([w0, w1])
predictions = x @ w.T
mse_loss = torch.mean((predictions - y) ** 2)
return mse_loss
def compute_regularization(w0, w1):
return torch.abs(w1) + torch.abs(w0)
reg_strength = 3.0
loss_values = torch.zeros_like(W0)
ell_1_values = torch.zeros_like(W0)
ell_2_values = torch.zeros_like(W0)
for i in range(W0.shape[0]):
for j in range(W0.shape[1]):
loss_values[i, j] = compute_loss(W0[i, j], W1[i, j], x, y)
ell_1_values[i, j] = torch.abs(W0[i, j]) + torch.abs(W1[i, j])
ell_2_values[i, j] = W0[i, j]**2 + W1[i, j]**2
fig, axarr = plt.subplots(1, 2, figsize = (8, 4))
# l2 regularization
loss = loss_values + reg_strength*ell_2_values
minimizer = torch.argmin(loss)
min_w0 = W0.flatten()[minimizer]
min_w1 = W1.flatten()[minimizer]
best_loss = loss_values.flatten()[minimizer]
best_reg = ell_2_values.flatten()[minimizer]
loss_min = torch.min(loss_values)
ax = axarr[0]
# ax.imshow(loss_values.numpy() + reg_strength*ell_2_values.numpy(), extent=(-1, 1, -1, 1), origin='lower', cmap='viridis_r')
ax.grid(False)
ax.set_xlabel(r"$w_1$")
ax.set_title(r"Loss Landscape with $\ell_2$ Regularization")
levels = [loss_min + (i)*0.5*(best_loss - loss_min) for i in range(5)]
ax.contour(W1.numpy(), W0.numpy(), loss_values.numpy(), levels=levels, origin='lower', cmap = "Reds")
ax.contour(W1.numpy(), W0.numpy(), ell_2_values.numpy(), levels=[i/3*best_reg for i in range(4)], linestyles='dashed', origin='lower')
ax.scatter(min_w1, min_w0, color='black', label='Minimizer', zorder=5)
# ax.legend()
ax.plot([-1, 2], [0, 0], color='grey', label='w0=0', zorder = -100)
ax.plot([0, 0], [-1, 2], color='grey', label='w1=0', zorder = -100)
ax.set_ylabel(r"$w_0$")
# l1 regularization
loss = loss_values + reg_strength*ell_1_values
minimizer = torch.argmin(loss)
min_w0 = W0.flatten()[minimizer]
min_w1 = W1.flatten()[minimizer]
best_loss = loss_values.flatten()[minimizer]
best_reg = ell_1_values.flatten()[minimizer]
ax = axarr[1]
# ax.imshow(loss_values.numpy() + reg_strength*ell_1_values.numpy(), extent=(-1, 1, -1, 1), origin='lower', cmap='viridis_r')
ax.grid(False)
levels = [loss_min + (i)*0.5*(best_loss - loss_min) for i in range(5)]
c_loss = ax.contour(W1.numpy(), W0.numpy(), loss_values.numpy(), levels=levels, origin='lower', cmap = "Reds")
c_reg = ax.contour(W1.numpy(), W0.numpy(), ell_1_values.numpy(), levels=[i/3*best_reg for i in range(4)], linestyles='dashed', origin='lower')
# ax.contour(W1.numpy(), W0.numpy(), loss_values.numpy() + reg_strength*reg_values.numpy(), levels=20, colors='white', origin='lower')
ax.scatter(min_w1, min_w0, color='black', label='Minimizer', zorder=5)
ax.set_xlabel(r"$w_1$")
ax.set_title(r"Loss Landscape with $\ell_1$ Regularization")
# ax.legend()
ax.plot([-1, 2], [0, 0], color='grey', label='w0=0', zorder = -100)
ax.plot([0, 0], [-1, 2], color='grey', label='w1=0', zorder = -100)
plt.tight_layout()/Users/philchodrow/opt/anaconda3/envs/cs451/lib/python3.10/site-packages/torch/functional.py:505: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at /Users/runner/work/pytorch/pytorch/pytorch/aten/src/ATen/native/TensorShape.cpp:4383.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
/var/folders/xn/wvbwvw0d6dx46h9_2bkrknnw0000gn/T/ipykernel_56824/54210499.py:10: UserWarning: The use of `x.T` on tensors of dimension other than 2 to reverse their shape is deprecated and it will throw an error in a future release. Consider `x.mT` to transpose batches of matrices or `x.permute(*torch.arange(x.ndim - 1, -1, -1))` to reverse the dimensions of a tensor. (Triggered internally at /Users/runner/work/pytorch/pytorch/pytorch/aten/src/ATen/native/TensorShape.cpp:4483.)
predictions = x @ w.T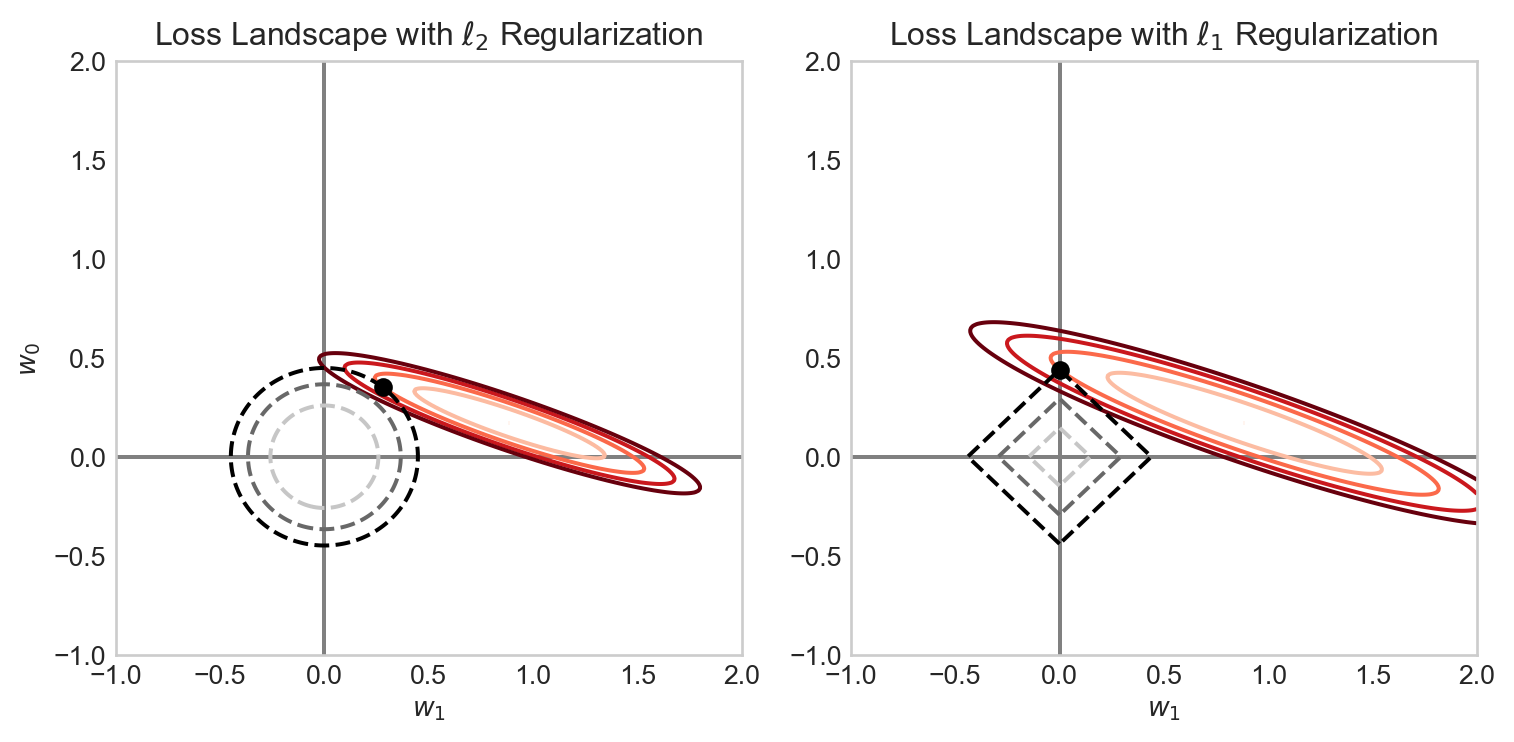
Model Selection
In one way, we’ve just kicked the can down the road – in an environment in which we can’t visually inspect the data or model predictions, how are we supposed to know what features or what regularization strength to use?
This is an instance of a problem called model selection, which asks us to make choices between models containing different features or hyperparameters. A very common approach to model selection is to use a validation set. The idea is to split our data into three parts: a training set which we’ll use for actually training our models, a validation set which we’ll use for model selection, and a test set which we’ll use for final evaluation of our chosen model. So, to make choices about the regularization strength, for example, we’ll train separate models with different regularization strengths on the training set, and then evaluate their performance on the validation set. The model with the best validation performance is then selected as the final model.
Features In the Wild
Although in the previous examples we engineered our features by hand using basis-function expansions, features are also natural parts of data sets! Often the data set we want to predict already has all the features we need (or more!), and we need to make all the same choices about which features to use and how to regularize. In the case study below, we’ll face some of these same questions without needing to engineer any new features by hand.
Bike Share Case Study
import pandas as pd
from sklearn.model_selection import train_test_split
import torch
from matplotlib import pyplot as plt
df = pd.read_csv('https://raw.githubusercontent.com/PhilChodrow/ml-notes-update/refs/heads/main/data/bikeshare/hour.csv')We’ve downloaded a data set containing hourly bike rental counts in Washington, D.C., along with a variety of features that might be predictive of bike rental demand. The data contains a variety of features including weather conditions, the year, month, week, and weekday; the hour of the day. It also includes columns for the number of casual and registered users, as well as the total count of bike rentals (cnt). We’ll try to predict the total count of bike rentals using the other features. Let’s take a look:
This data set was collected by Fanaee-T and Gama (2013).
df.head()| instant | dteday | season | yr | mnth | hr | holiday | weekday | workingday | weathersit | temp | atemp | hum | windspeed | casual | registered | cnt | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2011-01-01 | 1 | 0 | 1 | 0 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.81 | 0.0 | 3 | 13 | 16 |
| 1 | 2 | 2011-01-01 | 1 | 0 | 1 | 1 | 0 | 6 | 0 | 1 | 0.22 | 0.2727 | 0.80 | 0.0 | 8 | 32 | 40 |
| 2 | 3 | 2011-01-01 | 1 | 0 | 1 | 2 | 0 | 6 | 0 | 1 | 0.22 | 0.2727 | 0.80 | 0.0 | 5 | 27 | 32 |
| 3 | 4 | 2011-01-01 | 1 | 0 | 1 | 3 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.75 | 0.0 | 3 | 10 | 13 |
| 4 | 5 | 2011-01-01 | 1 | 0 | 1 | 4 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.75 | 0.0 | 0 | 1 | 1 |
Our aim is to predict the cnt column using the other features. Let’s visualize the total number of bike rentals over time:
Code
fig, ax = plt.subplots(figsize = (6, 4))
ridership_by_day = df.groupby("dteday")["cnt"].sum().reset_index()
ridership_by_day["dteday"] = pd.to_datetime(ridership_by_day["dteday"])
ax.plot(ridership_by_day["dteday"], ridership_by_day["cnt"], color='steelblue')
plt.xlabel("Date")
t = plt.ylabel("Total Daily Bike Rentals")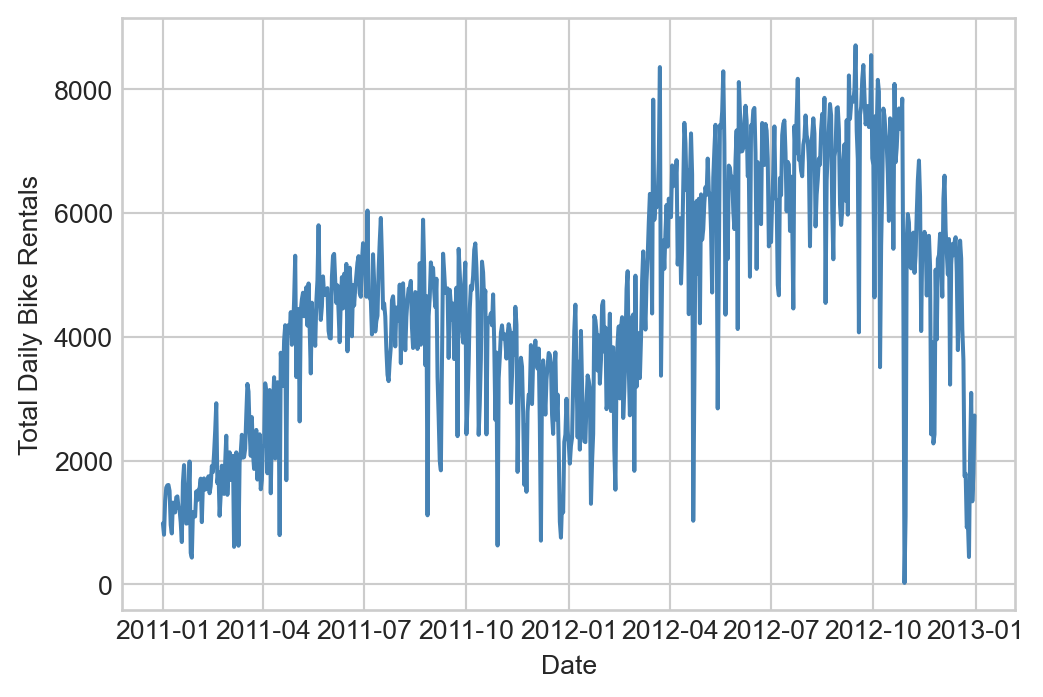
Predicting the number of bike rentals on a given day is a very helpful task for bikeshare operators, as this can help them know the urgency of rebalancing (moving bikes between stations) and scheduling maintenance.
Let’s prepare our data for modeling by dropping some columns and transforming qualitative columns into one-hot encoded features:
df.drop(columns=['instant', 'dteday', "workingday"], inplace=True)
df = 1.0*pd.get_dummies(df, columns=['season', 'weathersit', 'mnth', 'hr', 'weekday'], drop_first=False)
# ensure that the constant feature is the first column
df["intercept"] = 1
cols = list(df.columns)
cols.insert(0, cols.pop(cols.index('intercept')))
df = df.loc[:,cols]
df.columnsIndex(['intercept', 'yr', 'holiday', 'temp', 'atemp', 'hum', 'windspeed',
'casual', 'registered', 'cnt', 'season_1', 'season_2', 'season_3',
'season_4', 'weathersit_1', 'weathersit_2', 'weathersit_3',
'weathersit_4', 'mnth_1', 'mnth_2', 'mnth_3', 'mnth_4', 'mnth_5',
'mnth_6', 'mnth_7', 'mnth_8', 'mnth_9', 'mnth_10', 'mnth_11', 'mnth_12',
'hr_0', 'hr_1', 'hr_2', 'hr_3', 'hr_4', 'hr_5', 'hr_6', 'hr_7', 'hr_8',
'hr_9', 'hr_10', 'hr_11', 'hr_12', 'hr_13', 'hr_14', 'hr_15', 'hr_16',
'hr_17', 'hr_18', 'hr_19', 'hr_20', 'hr_21', 'hr_22', 'hr_23',
'weekday_0', 'weekday_1', 'weekday_2', 'weekday_3', 'weekday_4',
'weekday_5', 'weekday_6'],
dtype='object')We’ll now split the data into features and targets, and then into training, validation, and test sets.
X = 1.0*df.drop(columns=['cnt', 'casual', 'registered'])
y = df['cnt']
test_proportion = 0.94
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_proportion, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=1/2, random_state=42)
X_train = torch.tensor(X_train.values, dtype=torch.float32)
y_train = torch.tensor(y_train.values.reshape(-1, 1), dtype=torch.float32)
X_val = torch.tensor(X_val.values, dtype=torch.float32)
y_val = torch.tensor(y_val.values.reshape(-1, 1), dtype=torch.float32)
X_test = torch.tensor(X_test.values, dtype=torch.float32)
y_test = torch.tensor(y_test.values.reshape(-1, 1), dtype=torch.float32)We’ve split the data into three pieces: a small training set (3% of the data), a validation set (3% of the data), and a test set (94% of the data). Given the size of the data set, this split is reasonable – we have enough data to train models effectively, while still leaving a large amount of data for final evaluation.
print(f"Training set size: {X_train.shape[0]} samples")
print(f"Validation set size: {X_val.shape[0]} samples")
print(f"Test set size: {X_test.shape[0]} samples")Training set size: 521 samples
Validation set size: 521 samples
Test set size: 16337 samplesTo contextualize model performance on real data, it’s helpful to compute a base rate.
Definition 4.2 (Base Rate) A base rate is a measure of performance for a model which uses no features in the data. We typically say that a model has demonstrated success in learning from features if it outperforms the base rate on unseen data.
Let’s check the base rate for the bikeshare data and assess on validation data:
y_mean = y_train.mean()
base_rate_mse = mse(y_val, y_mean)
print(f"Base rate MSE on validation data: {base_rate_mse.item():.4f}")Base rate MSE on validation data: 33617.3125So, we are looking for any reasonable candidate model to achieve validation MSE less than the above.
In principle, we can already go ahead and fit a model:
LR = LinearRegression(n_params=X_train.shape[1])
train_model(LR, X_train, y_train, lr=1e-2, n_epochs=50000, tol=1e-4)
y_pred = LR.forward(X_val)
val_mse = mse(y_pred, y_val)
print(f"Validation MSE without regularization: {val_mse.item():.4f}")
print(f"Fraction of base rate: {val_mse.item()/base_rate_mse.item():.4f}")Validation MSE without regularization: 12257.3740
Fraction of base rate: 0.3646This simple linear regression model with no regularization already performs considerably better on validation data than the base rate. Can we do better with regularization? To find out, we’ll do a systematic search in which we vary the regularization strength and evaluate performance on validation data, for each of ridge regression and LASSO.
Code
reg_strengths = torch.logspace(-5, 0, 21)
train_mses = []
val_mses = []
W = torch.empty(X_train.shape[1], 0)
for reg in reg_strengths:
LR = LinearRegression(n_params=X_train.shape[1])
train_model(LR, X_train, y_train, lr=1e-1, n_epochs=20000, tol = 1e-2, regularization = lambda w: reg*ell_2_regularization(w))
y_pred_train = LR.forward(X_train)
train_mse = mse(y_pred_train, y_train)
y_pred_val = LR.forward(X_val)
val_mse = mse(y_pred_val, y_val)
train_mses.append(train_mse.item())
val_mses.append(val_mse.item())
W = torch.cat((W, LR.w), dim=1)
best_reg = reg_strengths[val_mses.index(min(val_mses))]
fig, ax = plt.subplots(1, 2, figsize = (8,3))
ax[0].plot(reg_strengths, train_mses, label='Train MSE')
ax[0].plot(reg_strengths, val_mses, label='Validation MSE')
ax[0].axvline(best_reg, color='black', linestyle='--', label=fr'Best $\lambda=${best_reg:.2f}, val MSE {min(val_mses):.1f}')
ax[0].set_xlabel("Regularization Strength")
ax[0].set_ylabel("MSE")
ax[0].set_xscale("log")
plt.title("Ridge Regression: Train and Validation MSE vs Regularization Strength")
ax[0].legend()
ax[1].plot(reg_strengths, W.detach().numpy().T)
ax[1].axvline(best_reg, color='black', linestyle='--', label=f'Best reg={best_reg:.4f}')
ax[1].set_xlabel("Regularization Strength")
ax[1].set_ylabel("Weights")
ax[1].set_xscale("log")
plt.title("Ridge Regression: Weights vs Regularization Strength")
plt.tight_layout()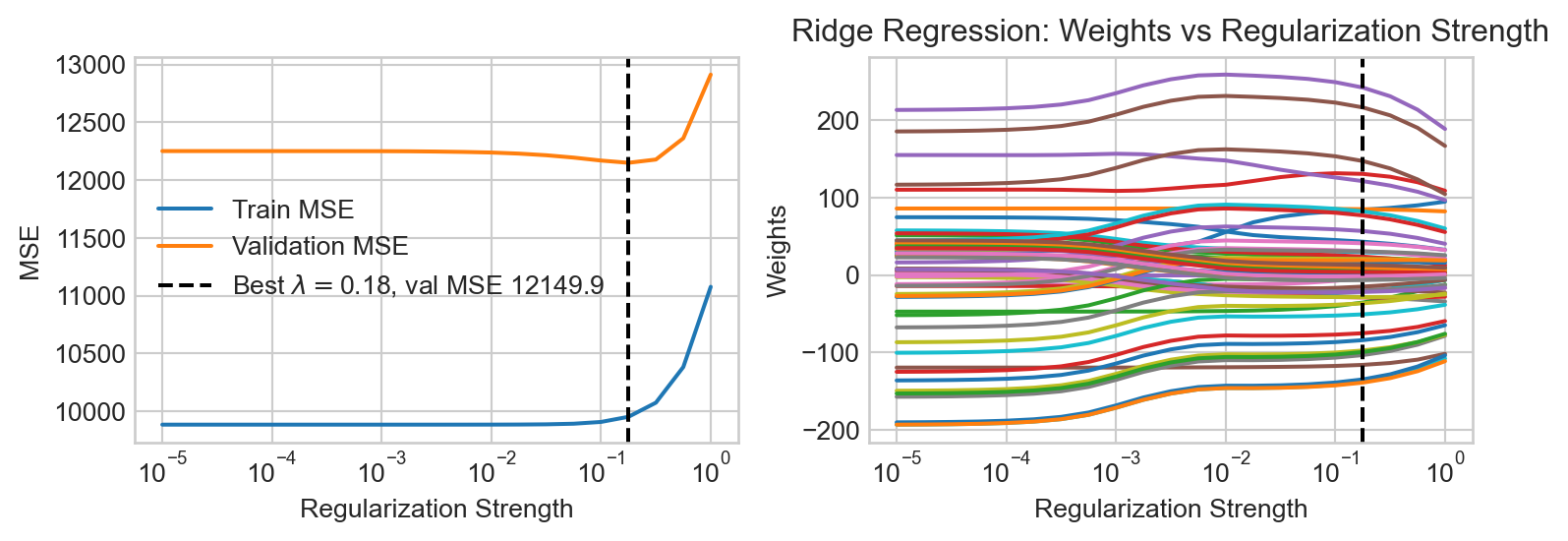
Now let’s try the same experiment for LASSO.
Code
reg_strengths = torch.logspace(0, 2, 21)
train_mses = []
val_mses = []
W = torch.empty(X_train.shape[1], 0)
for reg in reg_strengths:
LR = LinearRegression(n_params=X_train.shape[1])
train_model(LR, X_train, y_train, lr=1e-2, n_epochs=50000, tol = 1e-2, regularization = lambda w: reg*ell_1_regularization(w))
y_pred_train = LR.forward(X_train)
train_mse = mse(y_pred_train, y_train)
y_pred_val = LR.forward(X_val)
val_mse = mse(y_pred_val, y_val)
train_mses.append(train_mse.item())
val_mses.append(val_mse.item())
W = torch.cat((W, LR.w), dim=1)
best_reg = reg_strengths[val_mses.index(min(val_mses))]
fig, ax = plt.subplots(1, 2, figsize = (8,3))
ax[0].plot(reg_strengths, train_mses, label='Train MSE')
ax[0].plot(reg_strengths, val_mses, label='Validation MSE')
ax[0].axvline(best_reg, color='black', linestyle='--', label=fr'Best $\lambda=${best_reg:.2f}, val MSE {min(val_mses):.1f}')
ax[0].set_xlabel("Regularization Strength")
ax[0].set_ylabel("MSE")
ax[0].set_xscale("log")
plt.title("LASSO Regression: Train and Validation MSE vs Regularization Strength")
ax[0].legend()
ax[1].plot(reg_strengths, W.detach().numpy().T)
ax[1].axvline(best_reg, color='black', linestyle='--', label=f'Best reg={best_reg:.4f}')
ax[1].set_xlabel("Regularization Strength")
ax[1].set_ylabel("Weights")
ax[1].set_xscale("log")
plt.title("LASSO Regression: Weights vs Regularization Strength")
plt.tight_layout()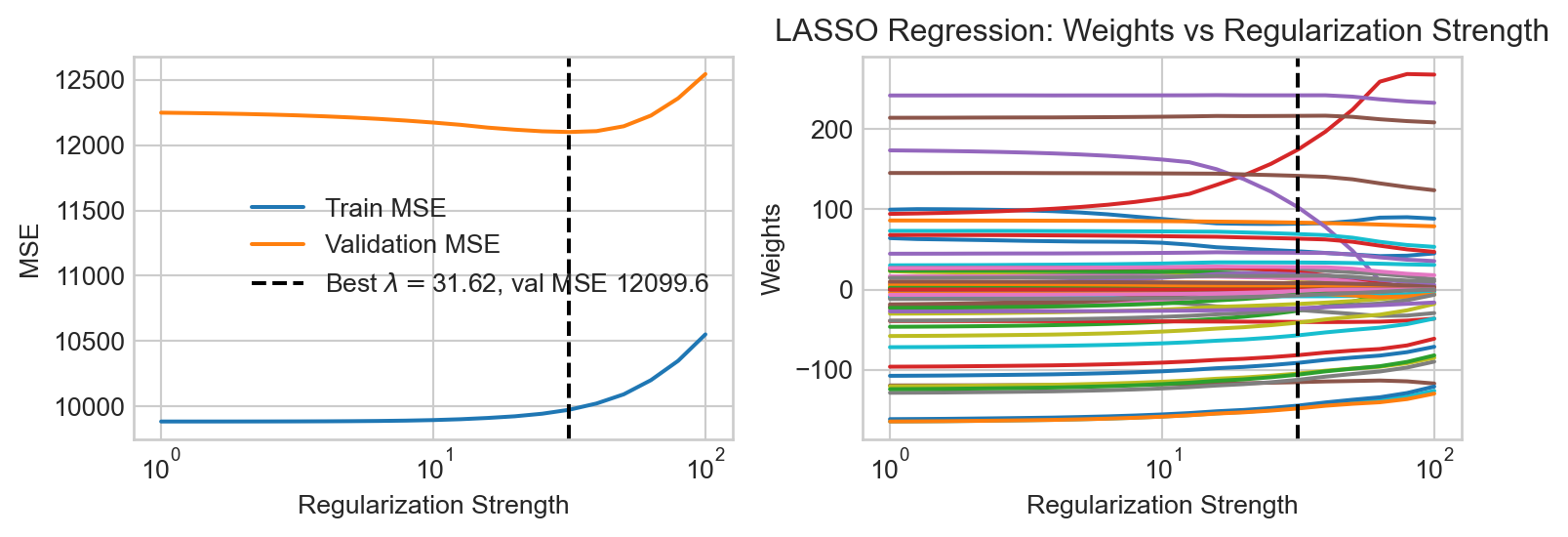
We find that LASSO regression achieves a slightly lower MSE on validation data than ridge regression.
Let’s train the LASSO model one last time with the best regularization strength and take a look at the learned coefficients:
reg_strength = reg_strengths[val_mses.index(min(val_mses))]
LR = LinearRegression(n_params=X_train.shape[1])
train_model(LR, X_train, y_train, lr=1e-1, n_epochs=20000, tol = 1e-4, regularization = lambda w: reg_strength*ell_1_regularization(w))We can inspect the coefficients to see which features the model found most important:
coefs = pd.DataFrame({
'Feature': X.columns,
'Coefficient': LR.w.detach().numpy().flatten()
}).sort_values(by='Coefficient', key=abs, ascending=False)
coefs.head()| Feature | Coefficient | |
|---|---|---|
| 44 | hr_17 | 245.015442 |
| 35 | hr_8 | 219.449371 |
| 3 | temp | 174.334061 |
| 45 | hr_18 | 144.749573 |
| 31 | hr_4 | -144.738724 |
We see that rush hours and high temperatures are identified by the model as highly predictive of bike rental demand.
Finally, let’s evaluate our chosen model on the test set to get a final estimate of performance:
y_pred_test = LR.forward(X_test)
test_mse = mse(y_pred_test, y_test)
print(f"Test MSE: {test_mse.item():.4f}")
print(f"Fraction of base rate: {test_mse.item()/base_rate_mse.item():.4f}")Test MSE: 11489.1650
Fraction of base rate: 0.3418Our final model achieves a test MSE considerably lower than the base rate, suggesting that it has successfully learned to predict bike rental demand using the available features.
References
Fanaee-T, Hadi, and Joao Gama. 2013. “Event Labeling Combining Ensemble Detectors and Background Knowledge.” Progress in Artificial Intelligence, 1–15. https://doi.org/10.1007/s13748-013-0040-3.
© Phil Chodrow, 2025