class LinearRegression:
def __init__(self, n_params):
self.w = torch.zeros(n_params, 1)
def forward(self, X):
return X @ self.w3 Higher Dimensions
Working with models and gradients with many features
Open the live notebook in Google Colab.
Recap
Last time, we developed an end-to-end example of maximum-likelihood estimation for the 1-dimensional linear-Gaussian model, which allowed us to fit a regression line to data displaying a linear trend. We saw that we could use the gradient of the log-likelihood function (or in this case, equivalently, the mean-squared error) to iteratively update a guess for the optimal parameters using gradient descent.
The model we learned to fit had two parameters, \(w_1\) and \(w_0\). However, modern models have vastly more parameters, with frontier LLMs having parameter counts nearing the trillions. In order to reason about these models, we need to build fluency in reasoning about high-dimensional spaces of parameters. We turn to this now, with a focus on multivariate linear regression.
Multivariate Linear-Gaussian Model
Recall that the 1-dimensional linear-Gaussian model assumed that the target variable \(y\) was generated from a linear function of a single feature \(x\) plus Gaussian noise. We can write this as:
\[ \begin{aligned} y_i \sim \mathcal{N}(w_1 x_i + w_0, \sigma^2) \end{aligned} \]
Suppose now that we have more than one predictive feature, which we would like to use in our model. Given \(p\) features \(x_1,\ldots,x_p\), we can extend the linear-Gaussian model to incorporate all of them:
\[ \begin{aligned} y_i \sim \mathcal{N}(w_1 x_{i1} + w_2 x_{i2} + \cdots + w_p x_{ip} + w_0, \sigma^2) = \mathcal{N}\left(\sum_{j=1}^p w_j x_{ij} + w_0, \sigma^2\right) \end{aligned} \tag{3.1}\]
Here’s a visualization of a regression model with two features, \(x_1\) and \(x_2\), alongside the plane defined by the linear function of these features.
Code
import torch
from matplotlib import pyplot as plt
# Generate synthetic data
torch.manual_seed(0)
n_samples = 100
X = torch.randn(n_samples, 2)
true_w = torch.tensor([1.0, 1.0])
true_b = 1.0
y = X @ true_w + true_b + 1 * torch.randn(n_samples)
# Plot the data
fig = plt.figure(figsize=(4, 3))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X[:, 0].numpy(), X[:, 1].numpy(), y.numpy(), c='b', marker='o')
ax.set_xlabel(r'$x_1$')
ax.set_ylabel(r'$x_2$')
ax.set_zlabel('Target y')
ax.set_title('3D Scatter Plot of Synthetic Data')
# plot the regression plane
xx1, xx2 = torch.meshgrid(torch.linspace(-3, 3, 10), torch.linspace(-3, 3, 10), indexing='ij')
zz = true_w[0] * xx1 + true_w[1] * xx2 + true_b
ax.plot_surface(xx1.numpy(), xx2.numpy(), zz.numpy(), alpha=0.2, color='b')
# plot the residuals
for i in range(n_samples):
ax.plot([X[i, 0].item(), X[i, 0].item()],
[X[i, 1].item(), X[i, 1].item()],
[y[i].item(), (true_w @ X[i] + true_b).item()],
c='black', alpha=0.5, linestyle='--')
plt.show()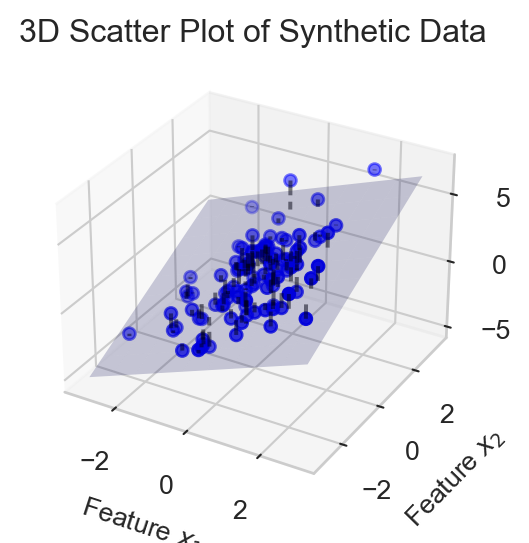
In order to write down Equation 3.1 more compactly, we need to introduce some notation. We’ll collect the features for data point \(i\) into a vector:
\[ \begin{aligned} \mathbf{x}_i = (x_{i0}, x_{i1},x_{i2},\ldots,x_{ip}) \end{aligned} \]
where we assume that \(x_{i0} = 1\) is a constant feature included to capture the intercept term \(w_0\). We also collect the parameters into a vector:
\[ \begin{aligned} \mathbf{w}= (w_0, w_1, w_2, \ldots, w_p) \end{aligned} \]
With this notation, we can rewrite the sum appearing in the mean of the Gaussian in Equation 3.1 as an inner product between the feature vector \(\mathbf{x}_i\) and the parameter vector \(\mathbf{w}\):
An inner product is also often called a dot product. Equation 3.2 can equivalently be written with the notation \( \mathbf{x}_i^T \mathbf{w} = \mathbf{x}_i \cdot \mathbf{w}= \langle \mathbf{x}_i,\mathbf{w} \rangle\).
\[ \begin{aligned} \mathbf{x}_i^T \mathbf{w} = \sum_{j=0}^p w_j x_{ij} = 1\cdot w_0 + \sum_{j=1}^p w_j x_{ij} = 1\cdot w_0 + \sum_{j=1}^p w_j x_{ij}\;. \end{aligned} \tag{3.2}\]
The choice of \(x_{i0} = 1\) ensures that the intercept term \(w_0\) is included in the inner product. This is so convenient that we’ll assume it from now on.
This notation allows us to compactly rewrite the multivariate linear-Gaussian model as:
\[ \begin{aligned} y_i \sim \mathcal{N}( \mathbf{x}_i^T \mathbf{w}, \sigma^2) \end{aligned} \]
regardless of the number of features. We can make things even a bit simpler by defining a score \(s_i\) associated to each data point \(i\):
\[ \begin{aligned} s_i = \mathbf{x}_i^T \mathbf{w} \end{aligned} \tag{3.3}\]
after which we can write: \[ \begin{aligned} y_i \sim \mathcal{N}(s_i, \sigma^2) \end{aligned} \]
Log-Likelihood and Mean-Squared Error
The log-likelihood function of the multivariate linear-Gaussian model is given by
\[ \begin{aligned} \mathcal{L}(\mathbf{w}) &= \sum_{i=1}^n \log p_Y(y_i ; s_i, \sigma^2) \\ &= \sum_{i=1}^n \log \left( \frac{1}{\sqrt{2 \pi \sigma^2}} \exp\left(-\frac{(y_i - s_i)^2}{2 \sigma^2}\right) \right) \\ &= -\frac{n}{2} \log(2 \pi \sigma^2) - \frac{1}{2 \sigma^2} \sum_{i=1}^n (y_i - s_i)^2\;, \end{aligned} \]
which, like last time, means that our maximum-likelihood estimation problem is equivalent to minimizing the mean-squared error between the observed targets \(y_i\) and the scores \(s_i\):
\[ \begin{aligned} R(\mathbf{x}, \mathbf{y}; \mathbf{w}) = \frac{1}{n} \sum_{i=1}^n (y_i - s_i)^2 = \frac{1}{n} \sum_{i=1}^n (y_i - \mathbf{x}_i^T \mathbf{w})^2\;. \end{aligned} \]
In theory, we’re ready to start taking gradients and minimizing this function. However, it’s helpful to try to first simplify our notation even more, which we can do with the introduction of matrix and norm notation.
Matrices and Norms
Recall that the Euclidean norm of a vector \(\mathbf{v}\in \mathbb{R}^d\) is defined by the formula
More generally, the \(\ell_p\)-norm of vector \(\mathbf{v}\) is defined by the equation \[
\begin{aligned}
\lVert \mathbf{v} \rVert_p = \sqrt[p]{\sum_{j = 1}^d v_j^p}\;.
\end{aligned}
\] For simplicity, whenever we write \(\lVert \mathbf{v} \rVert\) without a subscript, we mean the \(\ell_2\)-norm, i.e. \(\lVert \mathbf{v} \rVert = \lVert \mathbf{v} \rVert_2\).
\[ \begin{aligned} \lVert \mathbf{v} \rVert^2 = \sum_{j=1}^d v_j^2\;. \end{aligned} \]
The norm notation allows us to eliminate the explicit summation in favor of vector operations:
\[ \begin{aligned} R(\mathbf{x}, \mathbf{y}; \mathbf{w}) = \frac{1}{n} \lVert \mathbf{y}- \mathbf{s} \rVert^2\;, \end{aligned} \]
where \(\mathbf{s}\) is the vector of scores for all data points, whose \(i\)th entry is given by Equation 3.3. Our last step is to give a compact formula for \(\mathbf{s}\). To do this, we collect all of the feature vectors \(\mathbf{x}_i\) into a matrix \(\mathbf{X}\in \mathbb{R}^{n \times (p+1)}\), whose \(i\)th row is given by \(\mathbf{x}_i^T\):
\[ \begin{aligned} \mathbf{X}= \left[\begin{matrix} - & \mathbf{x}_1^T & - \\ - & \mathbf{x}_2^T & - \\ & \vdots & \\ - & \mathbf{x}_n^T & - \end{matrix}\right]\;. \end{aligned} \]
Now, if we multiply the matrix \(\mathbf{X}\) by the parameter vector \(\mathbf{w}\), we obtain
\[ \begin{aligned} \mathbf{X}\mathbf{w}= \left[\begin{matrix} - & \mathbf{x}_1^T & - \\ - & \mathbf{x}_2^T & - \\ & \vdots & \\ - & \mathbf{x}_n^T & - \end{matrix}\right] \mathbf{w}= \left[\begin{matrix} \mathbf{x}_1^T \mathbf{w} \\ \mathbf{x}_2^T \mathbf{w} \\ \vdots \\ \mathbf{x}_n^T \mathbf{w} \end{matrix}\right] = \left[\begin{matrix} s_1 \\ s_2 \\ \vdots \\ s_n \end{matrix}\right] = \mathbf{s}\;, \end{aligned} \]
This gives us our compact formula for the MSE:
\[ \begin{aligned} R(\mathbf{x}, \mathbf{y}; \mathbf{w}) = \frac{1}{n}\lVert \mathbf{X}\mathbf{w}- \mathbf{y} \rVert^2\;. \end{aligned} \tag{3.4}\]
The maximum-likelihood problem for the multivariate linear-Gaussian model can therefore be written
Since the \(\frac{1}{n}\) is a positive constant, it does not affect the location of the minimum and can be ignored in the optimization problem.
\[ \begin{aligned} \hat{\mathbf{w}} = \mathop{\mathrm{arg\,min}}_\mathbf{w}\lVert \mathbf{X}\mathbf{w}- \mathbf{y} \rVert^2\;. \end{aligned} \tag{3.5}\]
Deriving and Checking Gradient Formulas
To solve the optimization problem in Equation 3.5, we will need the gradient of \(R\) with respect to \(\mathbf{w}\). To do so, we’ll highlight two approaches.
Entrywise Derivation
To compute the gradient of \(R\) entrywise, we start by explicitly rewriting \(R\) in summation notation, avoiding matrix and vector notation for the moment:
\[ \begin{aligned} R(\mathbf{x}, \mathbf{y}; \mathbf{w}) = \frac{1}{n} \sum_{i=1}^n (y_i - \mathbf{x}_i^T \mathbf{w})^2 = \frac{1}{n} \sum_{i=1}^n (y_i - \sum_{j=0}^p w_j x_{ij})^2\;. \end{aligned} \]
We now take the derivative with respect to a particular parameter \(w_k\):
\[ \begin{aligned} \frac{\partial R}{\partial w_k} &= \frac{\partial}{\partial w_k} \left( \frac{1}{n} \sum_{i=1}^n (y_i - \sum_{j=0}^p w_j x_{ij})^2 \right) \\ &= \frac{1}{n} \sum_{i=1}^n \frac{\partial}{\partial w_k} \left(y_i - \sum_{j=0}^p w_j x_{ij}\right)^2 \\ &= \frac{1}{n} \sum_{i=1}^n 2 \left(y_i - \sum_{j=0}^p w_j x_{ij}\right) \cdot \left(-x_{ik}\right) &\quad \text{(chain rule)}\\ &= -\frac{2}{n} \sum_{i=1}^n x_{ik} \left(y_i - \mathbf{x}_i^T \mathbf{w}\right) \\ &= \frac{2}{n} \sum_{i=1}^n x_{ik} \left( \mathbf{x}_i^T \mathbf{w} - y_i\right)\;. \end{aligned} \tag{3.6}\]
Vector Derivation
It’s more convenient and insightful to compute the gradient in vector form. This requires a few gradient identities, each of which can be derived and verified using entrywise methods like the one above. For our case, we need two identities
In both these identities, the gradient is taken with respect to \(\mathbf{v}\).
Proposition 3.1 (Gradient of Norm Squared) For any \(\mathbf{v}_0 \in \mathbb{R}^d\), if \(h(\mathbf{v}) = \lVert \mathbf{v} \rVert^2\), then \[ \nabla h(\mathbf{v}_0) = 2 \mathbf{v}_0\;. \]
Proposition 3.2 (Compositions with Linear Maps) Let \(h: \mathbb{R}^m \to \mathbb{R}\) be a differentiable function, let \(\mathbf{A}\in \mathbb{R}^{m \times n}\) be a matrix, and let \(\mathbf{b}\in \mathbb{R}^m\) be a vector. Define \(g: \mathbb{R}^n \to \mathbb{R}\) by \(g(\mathbf{v}) = h(\mathbf{A}\mathbf{v}+ \mathbf{b})\). Then, for any \(\mathbf{v}_0 \in \mathbb{R}^n\),
\[ \nabla g(\mathbf{v}_0) = \mathbf{A}^T \nabla f(\mathbf{A}\mathbf{v}_0 + \mathbf{b})\;. \]
To apply these identities to Equation 3.4, define the function \(g:\mathbb{R}^n \rightarrow \mathbb{R}\) by
\[ \begin{aligned} g(\mathbf{w}) = \frac{1}{n} \lVert \mathbf{X}\mathbf{w}- \mathbf{y} \rVert^2 = \frac{1}{n} h(\mathbf{X}\mathbf{w}- \mathbf{y})\;. \end{aligned} \]
Then,
\[ \begin{aligned} \nabla g(\mathbf{w}_0) &= \frac{1}{n} \mathbf{X}^T \nabla h(\mathbf{X}\mathbf{w}_0 - \mathbf{y}) &\quad \text{(Prop 3.2)} \\ &= \frac{2}{n} \mathbf{X}^T (\mathbf{X}\mathbf{w}_0 - \mathbf{y}) &\quad \text{(Prop 3.1)} \end{aligned} \]
It’s possible to check that this vector formula for the gradient matches the entrywise formula from Equation 3.6 by verifying that the \(k\)th entry of the vector formula equals the entrywise formula for arbitrary \(k\).
Checking Vector Identities
How do we know that vector gradient identities like the ones we used above are correct? The most direct way is to verify them entrywise. To verify a vector identity entrywise, we just check that the \(k\)th entry of the left-hand side equals the \(k\)th entry of the right-hand side, for an arbitrary index \(k\). For example, let’s verify the first identity above, \(\nabla \lVert \mathbf{v} \rVert^2 = 2\mathbf{v}\). The \(k\)th entry of the left-hand side is given by the partial derivative with respect to entry \(w_k\):
\[ \begin{aligned} \left(\nabla \lVert \mathbf{v} \rVert^2\right)_k = \frac{\partial}{\partial v_k} \lVert \mathbf{v} \rVert^2 = \frac{\partial}{\partial v_k} \sum_{j=1}^d v_j^2 = \sum_{j=1}^d \frac{\partial}{\partial v_k} v_j^2 = \sum_{j=1}^d 2\delta_{jk} v_k = 2 v_k\;, \end{aligned} \]
where \(\delta_{jk}\) is the Kronecker delta, which equals 1 if \(j=k\) and 0 otherwise. The \(k\)th entry of the right-hand side is simply \(2 v_k\). Since these are equal for arbitrary \(k\), the identity holds.
Implementing Multivariate Regression
Our implementation for multivariate linear regression is very similar to our implementation for univariate regression from last time, and can actually be more compact in code thanks to our use of matrix operations. torch supplies the syntax X@w for matrix-vector and matrix-matrix multiplication, which we can use to compute the predictions for all data points at once.
Object-Oriented API for Machine Learning Models
We are going to implement most of our machine learning models using an object-oriented approach which will generalize nicely once we move on to complex deep learning models.
Model Class
Under torch’s standard structure, a model is an instance of a class which holds parameters and implements a forward method which computes predictions given input data. Here’s a minimal implementation for linear regression:
Loss Function
Alongside the model class, we need a loss function. While there are many possibilities, we’ll use our familiar mean-squared error. The loss function should accept predicted and true target values, and return a scalar loss value.
def mse(s, y):
return torch.mean((s - y)**2)Optimizer
The last thing we need is an algorithm for optimizing the parameters of the model. Gradient descent is one such algorithm. Here, we’ll implement a simple version of gradient descent as a separate class:
class GradientDescentOptimizer:
def __init__(self, model, lr=1e-2):
self.model = model
self.lr = lr
# once we begin to rely on automatic differentiation
# we won't need to implement this ourselves
def grad_func(self, X, y):
s = self.model.forward(X)
n = y.shape[0]
gradient = (2/n) * X.T @ (s - y)
return gradient
def step(self, X, y):
self.model.w -= self.lr * self.grad_func(X, y)Now we’re ready to run multivariate linear regression. Let’s generate some random synthetic data for testing.
# Generate synthetic data
torch.manual_seed(0)
n_samples = 100
n_features = 5
X = torch.randn(n_samples, n_features)
X = torch.cat([torch.ones(n_samples, 1), X], dim=1) # shape (n_samples, n_features + 1)
true_w = torch.randn(n_features + 1, 1)
signal = X @ true_w
noise = 0.5 * torch.randn(n_samples, 1)
y = signal + noiseWith this data, we can check that our vector gradient formula matches the entrywise formula we derived earlier, which we can do via torch’s automatic differentiation:
model = LinearRegression(n_params=n_features + 1)
opt = GradientDescentOptimizer(model=model, lr=1e-2)
1grad_manual = opt.grad_func(X, y)
model.w.requires_grad_() # enable automatic differentiation for the parameters
s = model.forward(X)
2loss = mse(s, y)
3loss.backward()
print(torch.allclose(grad_manual, model.w.grad)) # Should print True
model.w.requires_grad_(False) # disable automatic differentiation for the parameters- 1
- Compute the gradient manually using the optimizer’s function.
- 2
-
Compute the loss using the
msefunction. - 3
- Use PyTorch’s automatic differentiation to compute the gradient.
Truetensor([[0.],
[0.],
[0.],
[0.],
[0.],
[0.]])Looks fine! Now that we have gradient descent implemented, we can consider the gradient descent algorithm itself. This time, we’ll implement gradient descent as two functions: one which performs a single step of gradient descent, and one which handles the main loop, including storing values of the loss and checking for convergence.
There are many ways to check for convergence. Here, we’re just testing whether \(\lVert \mathbf{w}_\mathrm{new} - \mathbf{w}_\mathrm{old} \rVert\) is small, which is one way to quantifying the idea that \(\mathbf{w}\) “hasn’t changed much” in a single iteration.
# training loop
loss_history = []
for _ in range(10000):
s = model.forward(X)
loss = mse(s, y)
loss_history.append(loss.item())
opt.step(X, y) # perform a single gradient descent step
# convergence check
if len(loss_history) > 1:
if abs(loss_history[-1] - loss_history[-2]) < 1e-6:
print("Converged")
breakConverged- Initialize a list to store the loss history.
- Compute and store the current loss.
- Perform a single gradient descent step.
- Check for convergence by seeing if the change in parameters is small.
Now we’re ready to run gradient descent.
Code
# Plot loss history
import matplotlib.pyplot as plt
plt.plot(loss_history)
plt.xlabel('Iteration')
plt.ylabel('Mean Squared Error')
plt.title('Gradient Descent Loss History')
plt.show()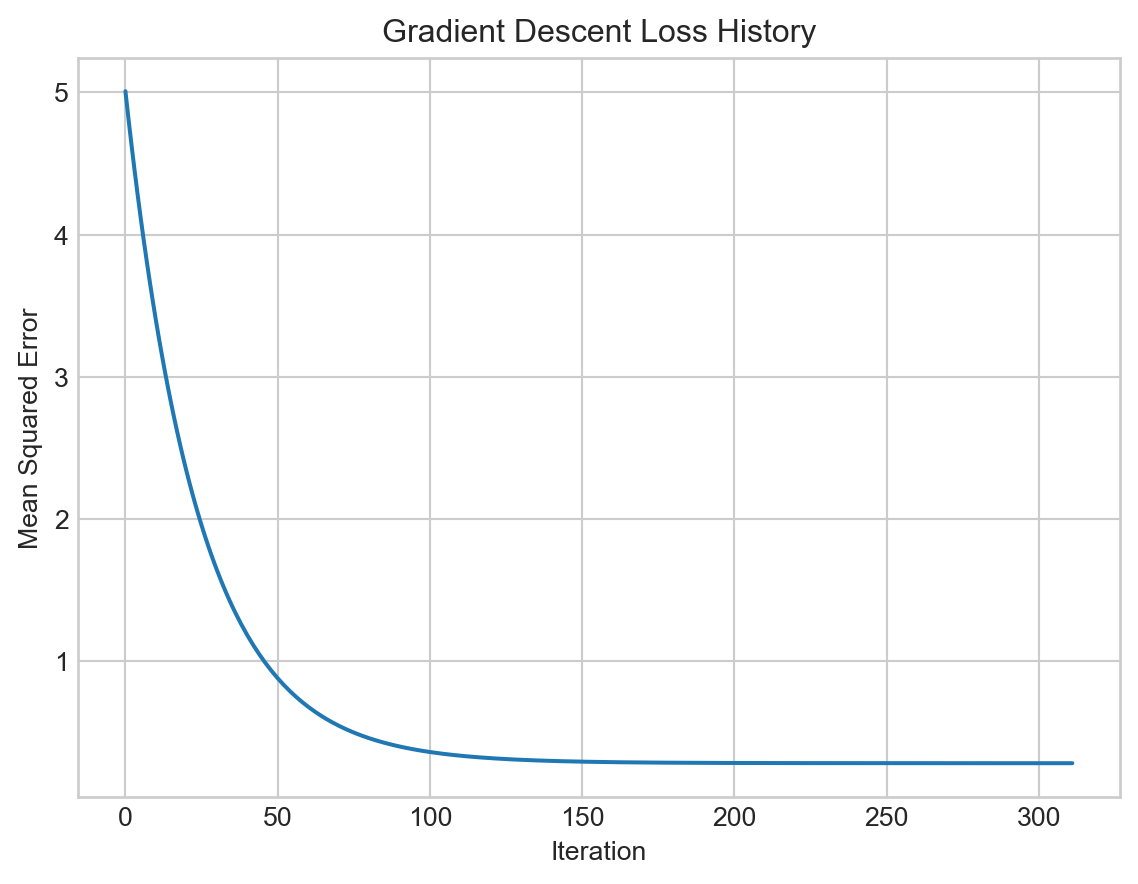
This time, because we implemented a convergence check, our main loop terminated automatically.
We can compare the learned parameters to the true parameters:
print("Learned parameters:\n", model.w.flatten())
print("True parameters:\n", true_w.flatten())Learned parameters:
tensor([ 0.8640, 0.3088, 0.2475, 1.0593, -0.9756, -1.2738])
True parameters:
tensor([ 0.8393, 0.2479, 0.2067, 0.9928, -0.8986, -1.2028])The learned parameters are relatively close to the true parameters we planted in the synthetic data.
© Phil Chodrow, 2025