In this chapter, we continue our discussion of deep learning and consider some practical considerations for applied projects:
What should you do if your data is too large or otherwise inconvenient to hold in memory?
Can pre-trained models be used to speed up training and improve performance?
How can I match techniques to the kind of data that I have?
Code
import librosaimport pandas as pdimport numpy as npimport requestsfrom matplotlib import pyplot as pltimport os import torchfrom torch.utils.data import Dataset, DataLoaderimport warningsfrom tqdm import TqdmWarningwarnings.filterwarnings("ignore", category=TqdmWarning)!pip install torchinfofrom torchinfo import summary
zsh:1: /usr/local/bin/pip: bad interpreter: /usr/bin/python: no such file or directory
Requirement already satisfied: torchinfo in /Users/philchodrow/opt/anaconda3/envs/cs451/lib/python3.10/site-packages (1.8.0)
Audio Classification
We’ll explore a small audio classification task to illustrate some of these ideas. Our data set is a subset of the ESC-50 data prepared by Piczak (2015). This data set contains a total of 2000 audio files, each 5 seconds long, and labeled with one of 50 classes. Our task will be to predict the category of a sound based only on the audio.
Some of the categories not used in these lecture notes include “rain,” “crying baby,” “glass breaking,” “airplane,” and “crow.”
Figure 14.1: Example spectrograms from the ESC-50 data set. Animation credit: (Piczak 2015) at the associated GitHub repository.
First, we’ll download a dataframe containing the metadata for the audio files.
Importantly, we don’t yet have any audio files. This data frame contains information like the integer target label and the corresponding category name, and also includes train/test folds that the researchers constructed. Providing a metadata file like this one is helpful for large multimedia data. For example, it allows us to perform data subsetting and to organize our train/validation split before we download the data, which can be helpful for large data sets.
First, let’s pick a small number of categories to work with, and then we’ll download the corresponding audio files.
print(f"Number of training examples: {len(train_df)}")print(f"Number of validation examples: {len(val_df)}")
Number of training examples: 128
Number of validation examples: 32
Now it’s time to actually access the audio files. Because we operated on the metadata first, we don’t have to download all 2,000 audio files from the repository directory; instead, we can just grab the ones we need. To illustrate working with data on filesystems, we’ll download the audio files and save them to disk.
The function below will download a single audio file and save it to the specified subdirectory of directory wav_data/, which will be created if necessary.
base_url ="https://github.com/karolpiczak/ESC-50/raw/refs/heads/master/audio"def download_wav_data(wav_id, data_dir):# create a directory for each data set if it doesn't exist yetifnot os.path.exists(f"wav_data/{data_dir}"): os.makedirs(f"wav_data/{data_dir}")# if the file isn't already downloaded, download it and save it to the appropriate directory destination =f"wav_data/{data_dir}/{wav_id}"ifnot os.path.exists(destination): url =f"{base_url}/{wav_id}" response = requests.get(url)withopen(destination, "wb") asfile:file.write(response.content)
We can now download the audio data by looping over the rows of each of our training and validation data frames. A simple syntactic alternative is to use the apply method of the data frame, which applies a function to each row of a specified column.
Let’s check that we’ve downloaded the data correctly:
num_training_files =len(os.listdir("wav_data/train"))num_validation_files =len(os.listdir("wav_data/val"))print(f"Number of training files: {num_training_files}")print(f"Number of validation files: {num_validation_files}")example_training_file =f"wav_data/train/{os.listdir('wav_data/train')[0]}"print(f"Example training filename: {example_training_file}")
Number of training files: 128
Number of validation files: 32
Example training filename: wav_data/train/3-160993-A-3.wav
Looks good!
Waveforms and Spectrograms
I know very little about audio processing, so the discussion here is at a very low level of detail or expertise.
When we natively read in a .wav file, the result is an array describing a waveform:
waveform, sr = librosa.load(example_training_file, sr=16000)print(type(waveform))print(f"Shape of audio array: {waveform.shape}")print(f"Sampling rate: {sr}")
<class 'numpy.ndarray'>
Shape of audio array: (80000,)
Sampling rate: 16000
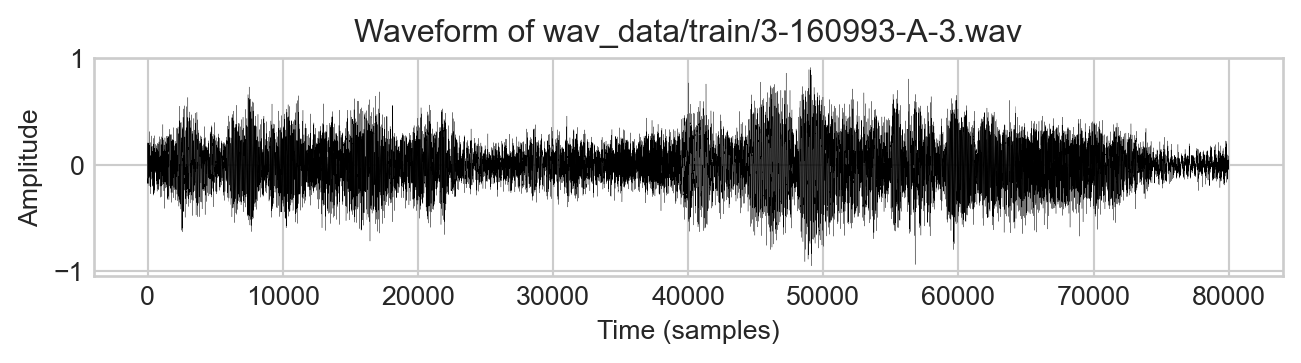
The sampling rate is 16,000 samples per second over 5 seconds, resulting in an array of 80,000 samples. The values in the array are floating point numbers between -1 and 1, which represent the amplitude of the sound wave at each sample:
fig, ax = plt.subplots(figsize=(7, 2))ax.plot(waveform, color ="black", linewidth =.1)ax.set_xlabel("Time (samples)")ax.set_ylabel("Amplitude")ax.set_title(f"Waveform of {example_training_file}")plt.tight_layout()
Figure 14.2: Example waveform from the ESC-50 data set.
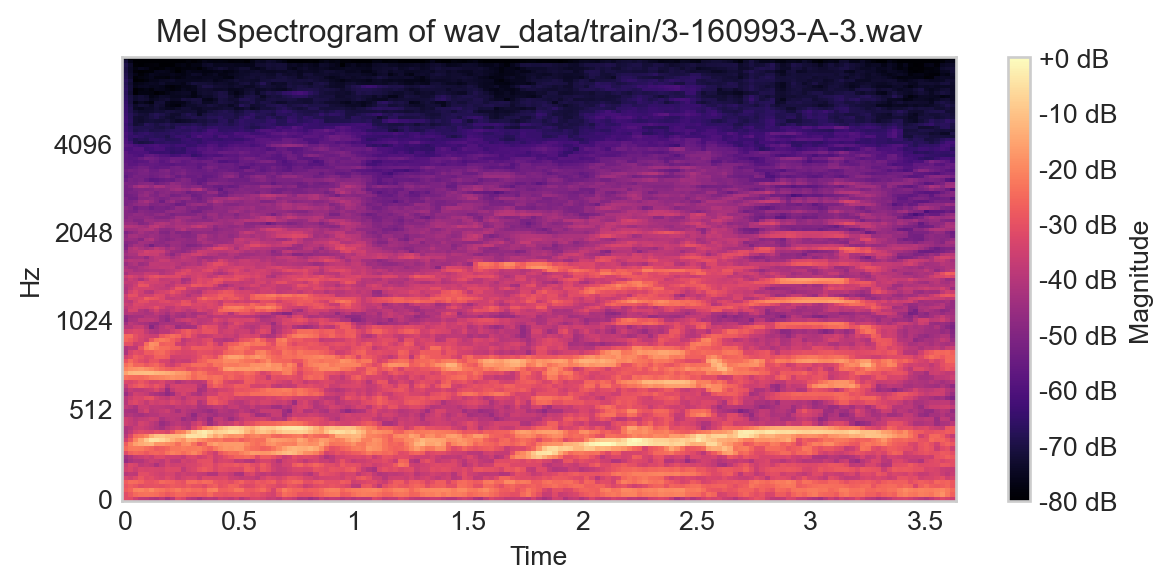
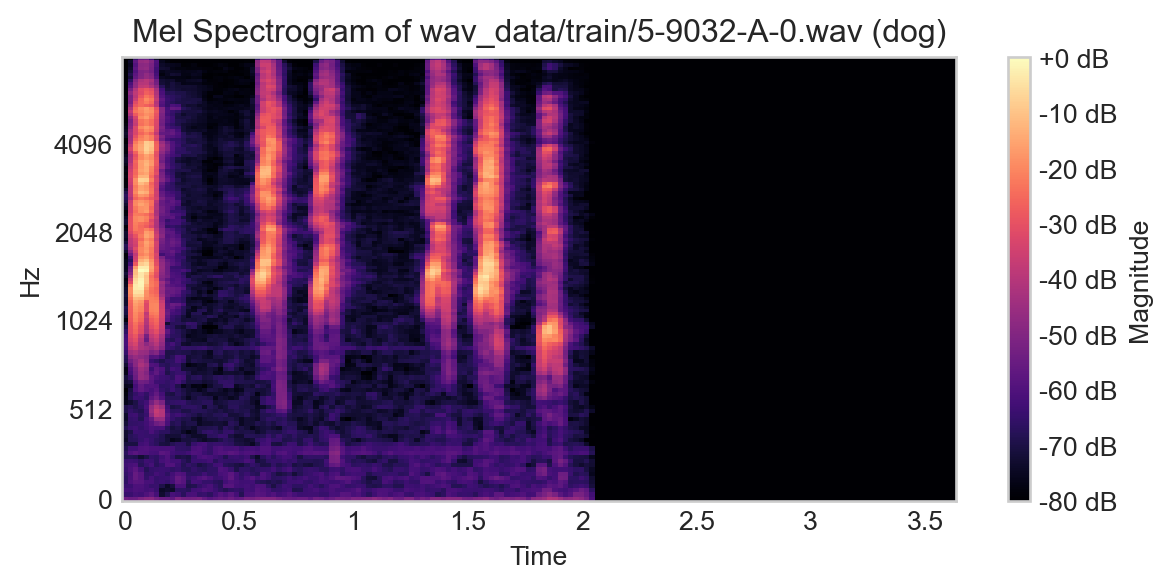
This waveform representation is, in principle, a perfectly valid input to a classification model, and contains 80,000 features. However, there are other representations of audio files which are also often useful. One of these is the spectrogram, which is a 2D representation of the audio file that captures how the frequency content of the sound changes over time. A common variant of the spectrogram is the Mel spectrogram, which uses a particular nonlinear transformation of the frequency axis to better capture human perception of sound.
Spectrograms are computed via Fourier transforms, in modern contexts usually the “fast Fourier transform (FFT).”
Figure 14.3: Example Mel spectrogram for a single training example.
Data From Filesystems
Now that we’ve seen two ways of representing the raw audio data, how are we going to feed this data into a model? Ideally, we’d like to do this in a way that (a) doesn’t require storing all the data in memory and (b) allows us to experiment with different data representations (e.g. waveform vs. spectrogram) and model architectures.
The key idea here is to implement an abstract DataSet with functionality for returning and optionally transforming data. The backend work is primarily to implement a __getitem__ method that supplies the user with a single data point at a time, including features, the target value, and any other desired metadata (such as the class names). This allows us to abstract away the handling of the filesystem from the user and makes it much easier to perform experiments.
We’ll also let the Dataset class handle determining the device on which the data should live, so first we need to discern the device:
device ="cuda"if torch.cuda.is_available() else"cpu"print(f"Running on {device}.")
Running on cpu.
Now we implement the Dataset class.
class WavDataset(Dataset):def__init__(self, metadata, path, transform=None):1self.metadata = metadata2self.transform = transform3self.path = pathdef__len__(self):4returnlen(self.metadata)def__getitem__(self, idx):# figure out which filename corresponds to the # specified index in self.metadata wav_id =self.metadata.iloc[idx]["filename"] wav_path =f"wav_data/{self.path}/{wav_id}"# corresponding target value5 label =self.metadata.iloc[idx]["category"]6 category = category_dict[label]# load in the audio audio, sr = librosa.load(wav_path, sr=16000)ifself.transform: audio =self.transform(audio) audio = torch.tensor(audio, dtype=torch.float32) category = torch.tensor(category, dtype=torch.long)return audio.to(device), category.to(device), label
1
Save the metadata dataframe for use in the __len__ and __getitem__ methods.
2
Save an optional transform function that can be applied to the raw audio data, for example a pipeline for computing the spectrogram.
3
Save the path to the data (e.g. “train” or “val”) for use in constructing the path to the audio files.
4
The length of the data set is just the number of rows in the metadata data frame.
5
The target label is the string in the category column of the metadata data frame.
6
The category is the integer value corresponding to the label, which we can get from the category_dict dictionary.
Since we are ultimately going to predict the category (target) from the audio, we need to move both of these to the device. The label is just for visualization purposes and won’t actually be used in a model.
Let’s try creating our training and validation data sets:
Because we implemented __len__ and __getitem__, we can do things like this:
audio, category, label = train_dataset[0]print(f"Shape of audio (features): {audio.shape}")print(f"Category integer: {category}")print(f"Category label: {label}")print(f"Total number of training examples: {len(train_dataset)}")
Shape of audio (features): torch.Size([80000])
Category integer: 1
Category label: cow
Total number of training examples: 128
Datasets are also effortlessly compatible with DataLoaders, which means we can set ourselves up for a stochastic training loop with minimal additional effort:
The flexibility of the dataset interface allows us to do the work once of defining a dataset, after which we can work with with code as simple as we would write for a data set held in memory. The interface even allows us greater flexibility. For example, we could even have had __getitem__ download the corresponding .wav file each time, so that we never actually have to store anything on disk. To be clear, that is probably a bad idea since web-based data transfer is so much slower than transfer from disk, but our ability to execute this bad idea does highlight how much flexibility we have.
Modeling with Multiple Perspectives on the Data
Recurrent Neural Networks for Time Series
Now let’s try a first model. Recurrent neural networks are a class of neural network designed for working with sequential and timeseries data, making them a natural choice for waveform data. The particular architecture we’ll use is the long short-term memory (LSTM) network, which is a variant of the recurrent neural network that is designed to better capture long-range dependencies in sequences. Our simple recurrent network below uses an LSTM layer followed by two fully connected layers, with nonlinearities interspersed.
Recurrent neural networks have been largely superseded in contemporary largescale applications by transformers, which are also designed for sequence data.
class RNN(torch.nn.Module):def__init__(self, input_size, hidden_size, num_classes):super().__init__()self.rnn = torch.nn.LSTM(input_size, hidden_size, batch_first=True)self.fc1 = torch.nn.Linear(hidden_size, hidden_size//2)self.fc2 = torch.nn.Linear(hidden_size//2, num_classes)def forward(self, x): out, _ =self.rnn(x) out =self.fc1(out) out = torch.relu(out) out =self.fc2(out)return out
Let’s try instantiating this model and training it. The input size is 80,000, corresponding to the number of samples in the audio file.
model = RNN(input_size=80000, hidden_size=16, num_classes=len(CATEGORIES)).to(device)
This model has a lot of parameters:
num_params =sum(param.numel() for param in model.parameters())print(f"Number of parameters in the model: {num_params}")
Number of parameters in the model: 5121324
We can get a more detailed view of the model architecture and the shapes of the intermediate outputs using the summary function from the torchinfo package.
X, y =next(iter(train_loader))[:2]summary(model, input_size=X.shape, device = device)
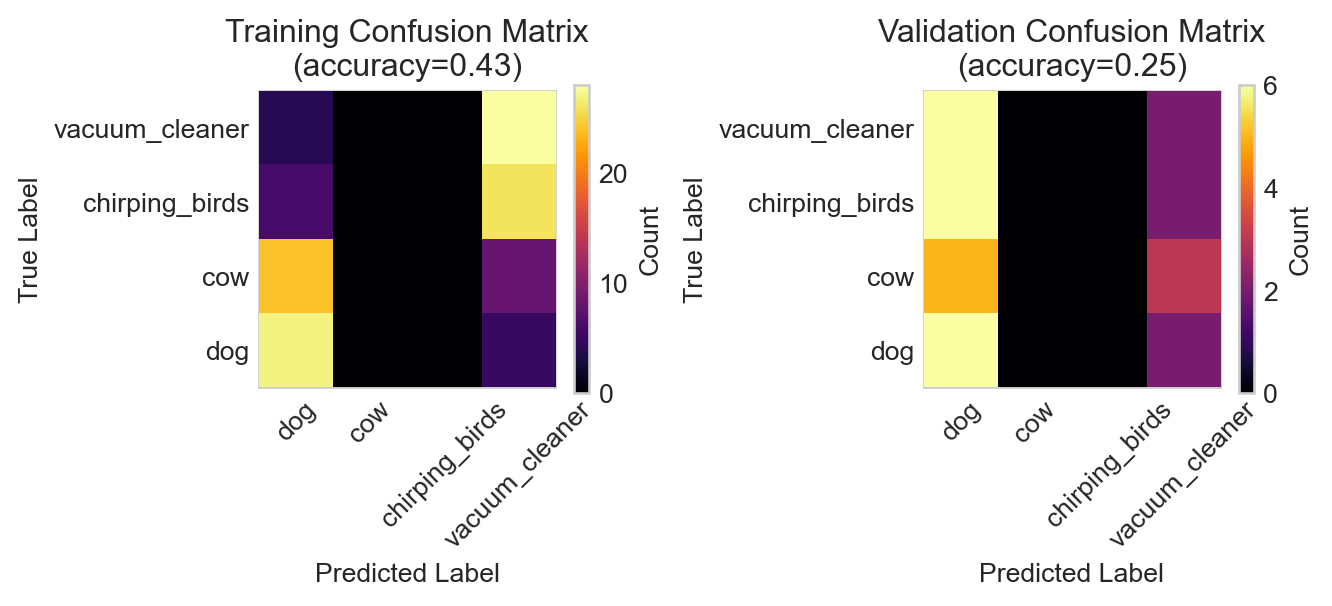
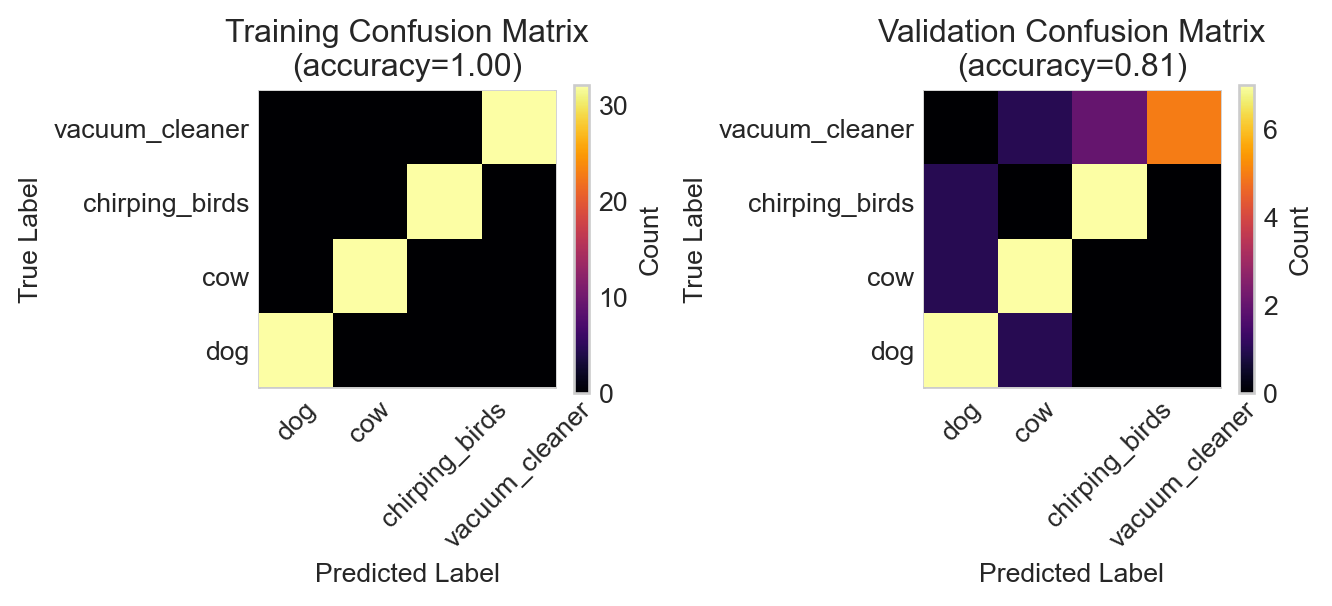
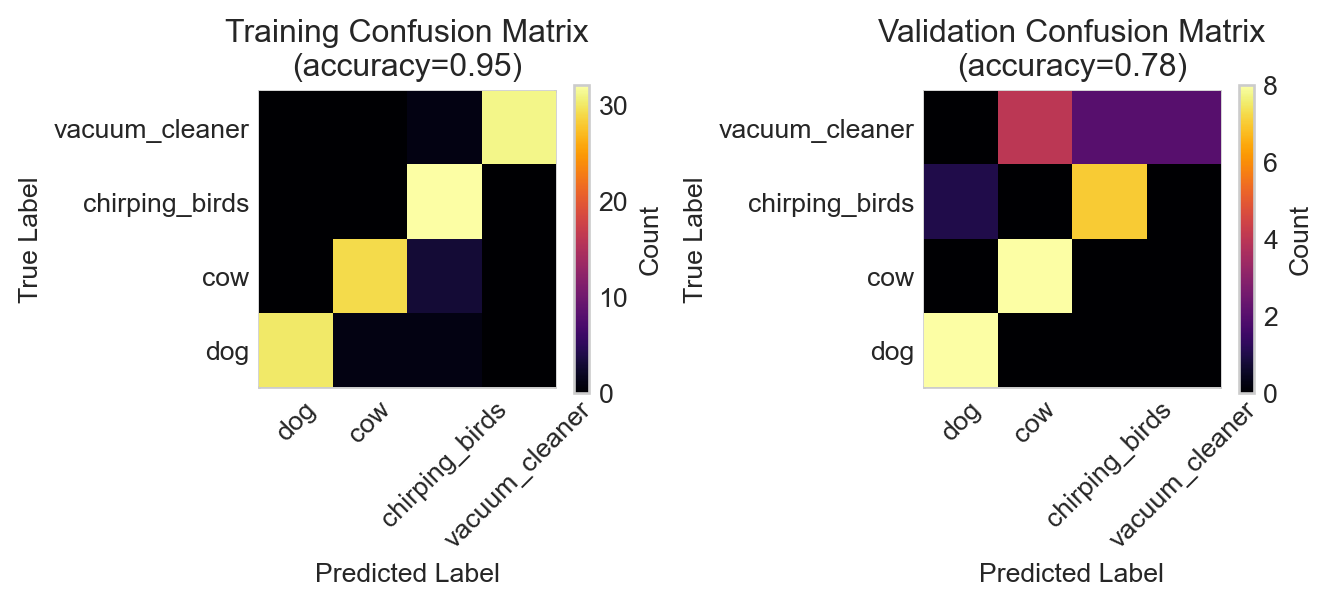
Figure 14.4: Confusion matrices for the RNN model on the training and validation data.
The RNN has badly overfit the training data, achieving high accuracy on the training set but essentially random guessing on the validation data. Although it may be possible to salvage the RNN, let’s instead try a different model architecture and data representation.
Convolutional Neural Networks for Spectrograms
Since we are already familiar with methods for image data sets, what if we leveraged the image-like structure of spectrograms as a stage in our feature pipeline? We could then use convolutional architectures in the hopes of better performance.
Since we added a transform argument to our WavDataset class, this is as easy as implementing a short function which computes the spectrogram from the input waveform:
model = ConvNet(num_classes=len(CATEGORIES)).to(device)
Perhaps importantly, this model has many fewer parameters than the RNN.
num_params =sum(param.numel() for param in model.parameters())print(f"Number of parameters in the model: {num_params}")
Number of parameters in the model: 134020
We can get a more detailed view of the model architecture and the shapes of the intermediate outputs using the summary function from the torchinfo package.
X, y =next(iter(spectrogram_train_loader))[:2]summary(model, input_size=X.shape, device = device)
Figure 14.6: Training and validation confusion matrices for the convolutional neural network.
While some evidence of overfitting is present, the convolutional architecture has achieved a much better accuracy on the classification problem than the recurrent architecture.
Data Augmentation
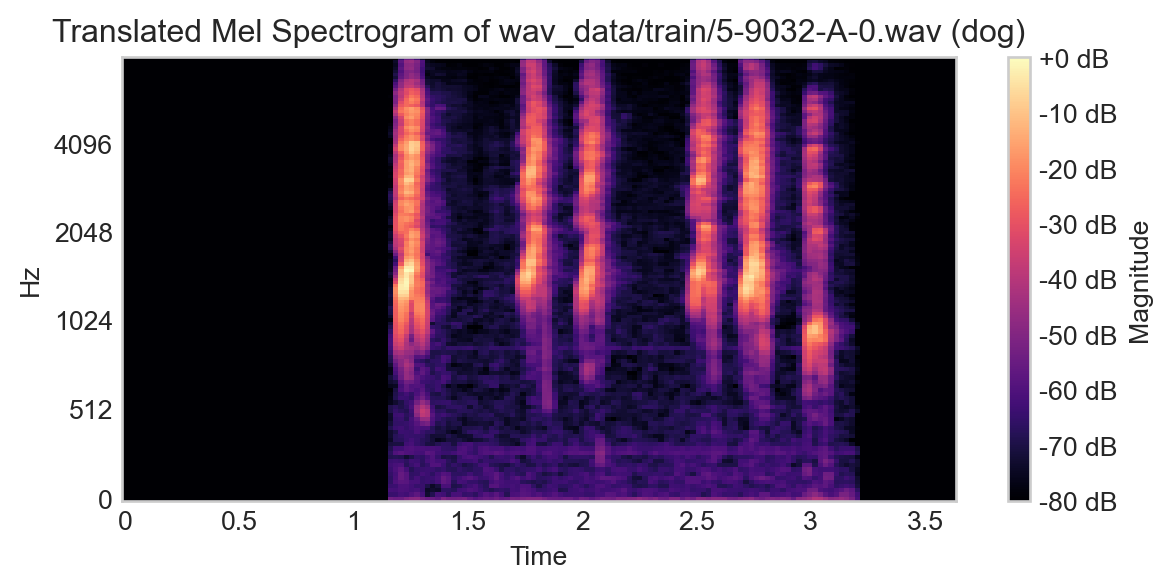
Consider the following example from our training set:
If we were to translate this signal by simply sliding it to the left or right, the appropriate label wouldn’t change, since we’re effectively just adding a time-delay to the recording.
Code
# translate the spectrogram by 10 time stepstranslated_spec = np.roll(spec, shift=50, axis=1)fig, ax = plt.subplots(figsize=(7, 3))im = librosa.display.specshow(translated_spec, y_axis='mel', fmax=8000, x_axis='time', ax = ax)ax.set_title(f"Translated Mel Spectrogram of {path} ({label})")t = plt.colorbar(im, label="Magnitude", format='%+2.0f dB')
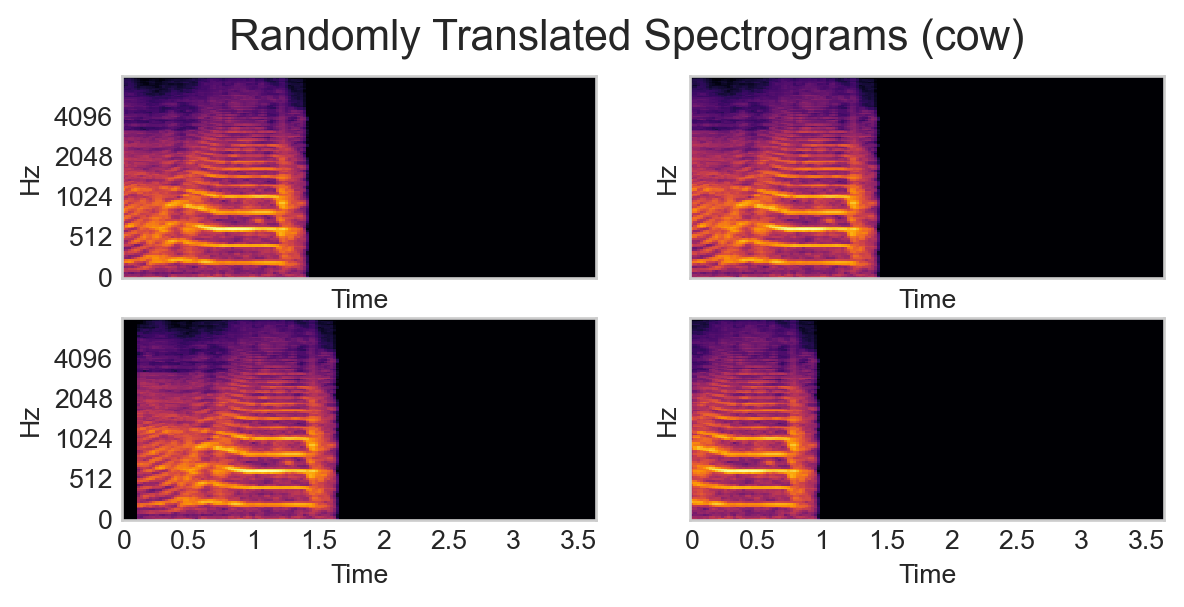
This insight implies that we can effectively create new data from our current data simply by applying transformations that preserve the data structure, in this case time-domain translation. Here’s a pipeline which implements this:
def transform_pipeline(y):# previous transform to obtain spectrogram spec = spectrogram_transform(y)# randomly translate the spectrogram by up to 20% of its width in either direction and pad with -80 dB (the minimum value in the spectrogram) on the side that gets rolled over max_translation_frac =0.2 translation_frac = np.random.uniform(0, max_translation_frac) pixels_to_translate =int(translation_frac * spec.shape[1]) pixels_to_translate = np.random.choice([-pixels_to_translate, pixels_to_translate]) translated_spec = np.roll(spec, shift=pixels_to_translate, axis=1)if pixels_to_translate >0: translated_spec[:, :pixels_to_translate] =-80else: translated_spec[:, pixels_to_translate:] =-80return translated_spec
We can now define a new data set and data loader that use this pipeline:
The use of data augmentation is often a way to reduce overfitting – showing a model multiple randomly perturbed versions of the same data point can allow the model to learn to ignore the random perturbations.
Other Data Augmentation
In our example, random horizontal translation was an appropriate way to augment our data, since this corresponded simply to adjusting the timing of the recording. In other contexts, other kinds of data augmentation may be appropriate. For example, in the context of image classification, random flips and rotations might also be appropriate. For example, all of the following transformed images depict a cat:
Figure 14.8: Some other kinds of data augmentation for image classification. Image credit: isahit.
Transfer Learning
Training machine learning models is fun and all, but wouldn’t it be easier if we could have someone else do the hard work for us?
Definition 14.1 (Transfer Learning)Transfer learning is the practice of accessing a model trained on a different-but-related task and retraining it for the desired task.
For example, in our case there are likely no models that are specifically specialized for the four-way classification problem we’ve considered here. However, there are lots of models trained on spectrograms more generally. So, if we accessed a spectrogram model, we could modify and retrain it for our application.
For example, let’s grab a generic trained image classification model. We’ll then “freeze” most of its parameters and train only the final linear layer:
from torchvision import modelsmodel = models.resnet18(weights='IMAGENET1K_V1')model = model.to(device)for param in model.parameters(): param.requires_grad =Falsemodel.fc = torch.nn.Linear(512, len(CATEGORIES)).to(device)
This model requires us to pass an image with 3 channels, for which we’ll just duplicate the spectrogram three times:
/var/folders/xn/wvbwvw0d6dx46h9_2bkrknnw0000gn/T/ipykernel_73610/947742019.py:25: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.detach().clone() or sourceTensor.detach().clone().requires_grad_(True), rather than torch.tensor(sourceTensor).
audio = torch.tensor(audio, dtype=torch.float32)
/var/folders/xn/wvbwvw0d6dx46h9_2bkrknnw0000gn/T/ipykernel_73610/947742019.py:25: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.detach().clone() or sourceTensor.detach().clone().requires_grad_(True), rather than torch.tensor(sourceTensor).
audio = torch.tensor(audio, dtype=torch.float32)
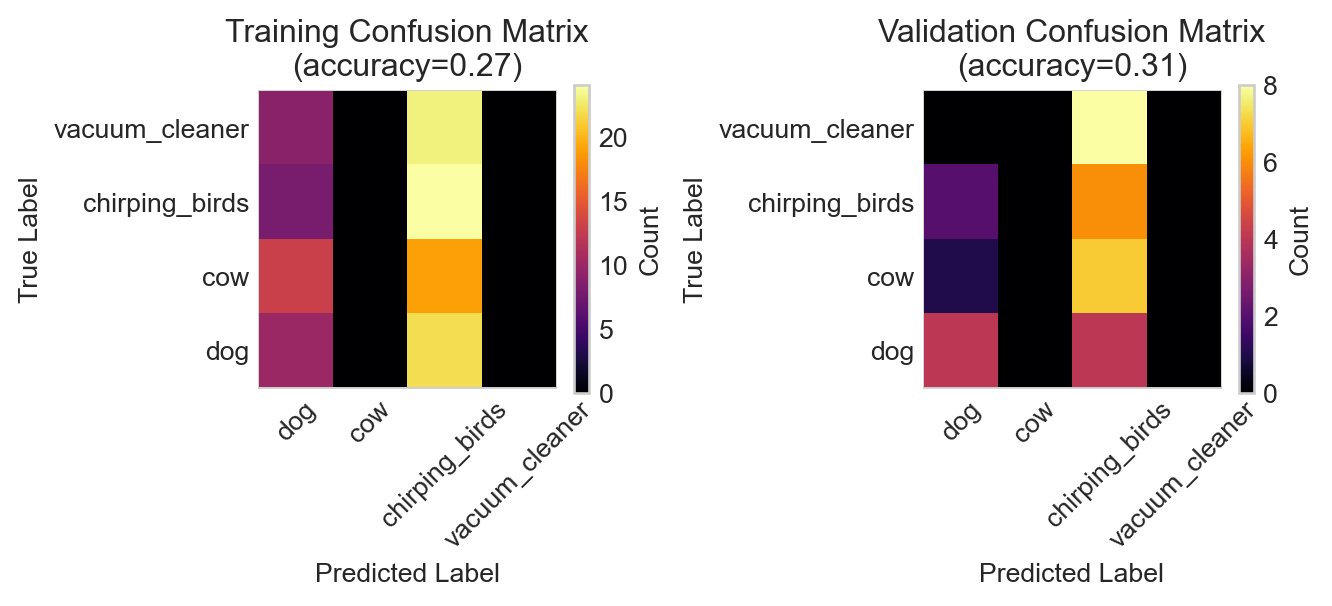
Figure 14.9: Performance of the lightly-retrained ResNet18 model on the audio classification task.
In this particular instance transfer learning has not been more effective than our simple convolutional network. This makes sense because the complexity of the pretrained network is so much higher than the complexity of the data set and task we have given it. It’s also important to note that most images don’t look like spectrograms, so a model trained on generic images may not be as effective here. For a more detailed look at transfer learning for image classificatino tasks, see this tutorial.
References
Piczak, Karol J. 2015. “ESC: Dataset for Environmental Sound Classification.” In Proceedings of the 23rd Annual ACM Conference on Multimedia, 1015–18. Brisbane, Australia: ACM Press. https://doi.org/10.1145/2733373.2806390.