import torchimport pandas as pdfrom matplotlib import pyplot as pltimport matplotlib.ticker as mtickimport torch.nn as nnfrom torch.nn import Conv2d, MaxPool2d, Parameterfrom torch.nn.functional import relufrom torchvision import modelsimport torch.optim as optimimport torch.nn as nnfrom torch.nn import ReLU!pip install torchinfofrom torchinfo import summaryplt.style.use('seaborn-v0_8-whitegrid')
zsh:1: /usr/local/bin/pip: bad interpreter: /usr/bin/python: no such file or directory
Requirement already satisfied: torchinfo in /Users/philchodrow/opt/anaconda3/envs/cs451/lib/python3.10/site-packages (1.8.0)
Our data for today is the Sign Language MNIST data set, which I retrieved from Kaggle. This data set poses a challenge: can we train a model to recognize a letter of American Sign Language from a hand gesture?
Natively, this data set comes to us as a data frame in which each column represents a pixel. Each image has 28x28 pixels, so there are 784 pixel columns, plus one column for the label (the letter being signed). Let’s take a look at the data frame:
df_train.head()
label
pixel1
pixel2
pixel3
pixel4
pixel5
pixel6
pixel7
pixel8
pixel9
...
pixel775
pixel776
pixel777
pixel778
pixel779
pixel780
pixel781
pixel782
pixel783
pixel784
0
3
107
118
127
134
139
143
146
150
153
...
207
207
207
207
206
206
206
204
203
202
1
6
155
157
156
156
156
157
156
158
158
...
69
149
128
87
94
163
175
103
135
149
2
2
187
188
188
187
187
186
187
188
187
...
202
201
200
199
198
199
198
195
194
195
3
2
211
211
212
212
211
210
211
210
210
...
235
234
233
231
230
226
225
222
229
163
4
13
164
167
170
172
176
179
180
184
185
...
92
105
105
108
133
163
157
163
164
179
5 rows × 785 columns
In principle, we’re already able to perform machine learning tasks on data in this format – treat each column as a feature and we’re ready to go. However, this format makes it very difficult to see relationships between these features. Importantly, a key feature of image data is that nearby pixels are often related to each other in important ways. There’s no hope to capture that idea from this data frame, because we can’t even tell which pixels are nearby each other. Let’s therefore reshape the data into something more like its native pixel format.
def prep_data(df): n, p = df.shape[0], df.shape[1] -1 y = torch.tensor(df["label"].values) X = df.drop(["label"], axis =1) X = torch.tensor(X.values) X = torch.reshape(X, (n, 1, 28, 28)) X = X /255return X, yX_train, y_train = prep_data(df_train)X_val, y_val = prep_data(df_val)
print("Training data shapes:")print(X_train.shape, y_train.shape)print("Validation data shapes:")print(X_val.shape, y_val.shape)
Training data shapes:
torch.Size([27455, 1, 28, 28]) torch.Size([27455])
Validation data shapes:
torch.Size([7172, 1, 28, 28]) torch.Size([7172])
We’ve shaped the data into a 4-dimensional tensor, with dimensions
The channel refers to the number of color channels in the image. Colors represented in Red, Green, and Blue color format (RGB) have 3 channels, one for each of R, G, and B. Greyscale images like the ones we’re working with today have only one channel.
So, to interpret X_train.shape, we have 27,455 images in the training data, each with 1 channel (grayscale), and each image is 28 pixels wide and 28 pixels high.
NoteBeyond data frames
So far in this class, we’ve almost exclusively considered data arranged in 2-dimensional structures like matrices or data frames with dimensions \(n\times d\), where \(n\) is the number of data observations and \(d\) is the number of features. As we move into deep learning, we’re going to see more examples of data sets like this one in which the 2-dimensional representation of data is inappropriate. We’ll therefore need to expand our thinking to more general tensors with more than two dimensions, like the one we have here.
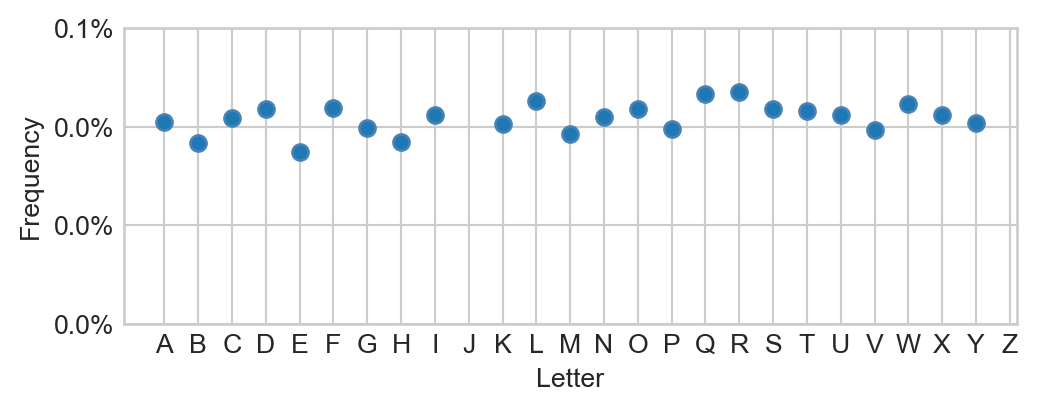
Figure 13.2: Distribution of class labels in the training data. There are no “J”s or “Z”s in this data because these characters require motion rather than a static gesture.
The most frequent letter (“R”) in this data comprises no more than 5% of the entire data set. So, as a minimal aim, we would like a model that gets the right character at least 5% of the time.
Data Prep
Sidebar: GPU Acceleration in Torch
As we’ve seen from the last several lectures, deep learning models involve a lot of linear algebra in order to compute predictions and gradients. This means that deep models, even more than many other machine learning models, strongly benefit from hardware that is good at doing linear algebra fast. As it happens, graphics processing units (GPUs) are very, very good at fast linear algebra. So, it’s very helpful when running our models to have access to GPUs; using a GPU can often result in up to 10x speedups. While some folks can use GPUs on their personal laptops, another common option for learning purposes is to use a cloud-hosted GPU. My personal recommendation is Google Colab, and I’ll supply links that allow you to open lecture notes in Colab and use their GPU runtimes.
The reason that GPUs are so good at this is that they were originally optimized for rendering complex graphics in e.g. animation and video games, and this involves lots of linear algebra.
The following torch code checks whether there is a GPU available to PyTorch, and if so, sets a variable called device to log this fact. We’ll make sure that both our data and our models fully live on the same device when doing model training.
device ="cuda"if torch.cuda.is_available() else"cpu"print(f"Running on {device}.")
Running on cpu.
Now that we’ve configured the device, we are going to need to place both our data and our models on the device.
As we saw when studying modern approaches to optimization loops, it’s convenient to loop through our data in batches and perform an optimization step after each batch. The following code defines a function that creates a data loader for our training and validation data sets.
As a reminder, it’s possible to loop through elements of the data loader using syntax like:
for X_batch, y_batch in train_loader:# do something with X_batch # and y_batch
Logistic Regression Baseline
Let’s go ahead and train a logistic regression model on this data. This model will make no use of the spatial structure of the pixels. Relative to our previous logistic regression implementations, the main difference here is that we need to structure the model to accept input data whose single instance has dimensions (1, 28, 28) rather than (784,). We can achieve this by including a Flatten layer in our model, which will take the 1x28x28 pixel input and flatten it into a 784-dimensional vector before applying the linear transformation.
We can make our code a bit more concise by enclosing each of our layers inside an nn.Sequential container, which allows us to treat the entire sequence of layers as a single layer which we then call in the forward method.
Relative to previous implementations of logistic regression, you might notice that this implementation does not contain a call to the logistic sigmoid. The reason for this is that we are going to use torch’s built-in nn.CrossEntropyLoss() as our loss function for training. For reasons of numerical stability, this function is structured to apply the cross-entropy loss, so we don’t need to do it in the model itself.
The flatten layer transforms the (1,28,28) image into a (784,) pixel sequence.
2
Apply a linear map (matrix multiplication)
3
Call the entire pipeline with a single call.
4
Instantiate the model and move it to the device.
Model Inspection
When constructing nontrivial deep learning models, it can be helpful to inspect them in order to get a sense for their structure and complexity level (especially the number of parameters). There are multiple ways to approach this, including several utilities which visualize the computational graph. Here, we’ll use the torchinfo package, which provides a nice summary of the model’s layers and parameters and includes a parameter count. To call the summary function, we need to specify the expected dimension of a single piece of data (including the channel):
For example, could you read off from the above model definition how many parameters are included in the model?
Even though we are looking at a simple logistic regression model, our parameter count is already in the tens of thousands!
The code block below allows us to evaluate a model’s performance by computing its accuracy and a confusion matrix on a specified data loader. There’s also a helper function for plotting the confusion matrix.
Initialize a confusion matrix of zeros with dimensions 26x26 (one row and one column for each letter of the alphabet).
2
For each batch in the data loader:
3
Compute the model’s output scores for the batch.
4
Determine the predicted class by taking the index of the maximum score for each instance in the batch.
5
Update the confusion matrix by incrementing the count for the true label and predicted label for each instance in the batch.
6
Compute the overall accuracy by summing the diagonal of the confusion matrix (correct predictions) and dividing by the total number of predictions.
Code
def plot_confusion_mat(conf_mat, ax, title ="Confusion Matrix"): im = ax.imshow(conf_mat.cpu(), cmap ="Blues", origin ="upper")# Show all ticks and label them with the respective list entries ax.set_xticks(torch.arange(len(ALPHABET))) ax.set_yticks(torch.arange(len(ALPHABET))) ax.set_xticklabels(list(ALPHABET)) ax.set_yticklabels(list(ALPHABET)) ax.set_xlabel("Predicted Label") ax.set_ylabel("True Label")# Rotate the tick labels and set their alignment. plt.setp(ax.get_xticklabels(), rotation=45, ha="right", rotation_mode="anchor")# Loop over data dimensions and create text annotations.for i inrange(conf_mat.shape[0]):for j inrange(conf_mat.shape[1]): text = ax.text(j, i, conf_mat[i, j].item(), ha="center", va="center", color="black", size =6) ax.set_title(title) ax.grid(False)
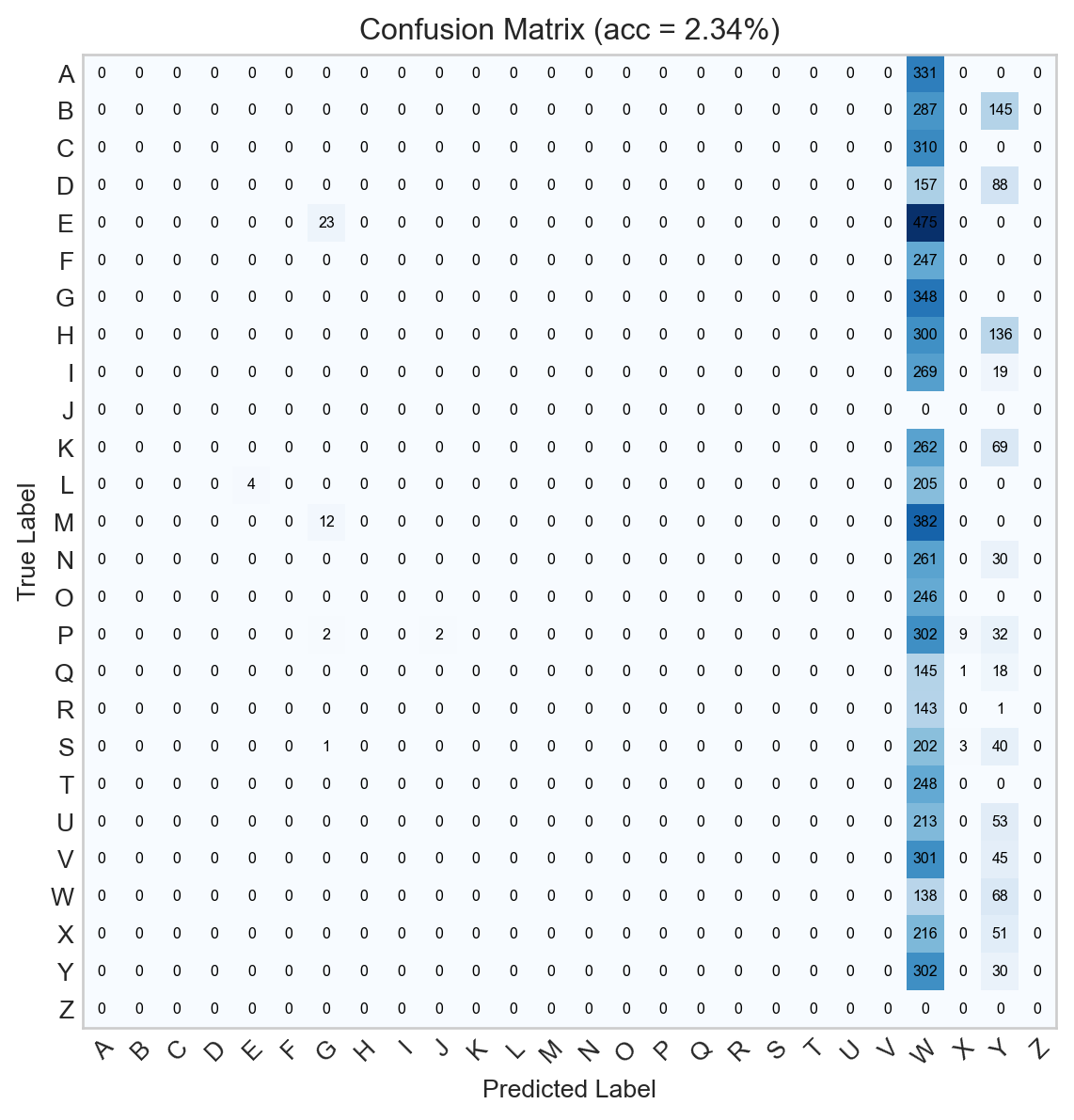
Figure 13.3: Confusion matrix for the untrained logistic regression model.
Obviously this model does not classify the data very impressively at all, since it hasn’t been trained yet. Let’s implement a training loop. This loop will perform model updates and track the model’s accuracy over time.
It would also be reasonable to track the average loss per batch over time. This would require an extra call to model.forward on the validation set, which we’re not going to do here because it increases the training time substantially.
def train(model, k_epochs =1, print_every =2000, **opt_kwargs):# loss function is cross-entropy (multiclass logistic) loss_fn = nn.CrossEntropyLoss()# optimizer is SGD with momentum optimizer = optim.SGD(model.parameters(), **opt_kwargs)# initialize list of accuracies to train_accuracy = [] val_accuracy = [] train_loss = [] val_loss = []for epoch inrange(k_epochs):for i, data inenumerate(train_loader): X, y = data optimizer.zero_grad() y_pred = model(X) loss = loss_fn(y_pred, y) loss.backward() optimizer.step() train_acc, train_l, train_cm = evaluate(model, data_loader = train_loader) val_acc, val_l, val_cm = evaluate(model, data_loader = val_loader) train_accuracy += [train_acc] val_accuracy += [val_acc] train_loss += [train_l] val_loss += [val_l]return train_accuracy, train_loss, val_accuracy, val_loss
Now let’s train the model and visualize its performance over time:
train_accuracy, train_loss, val_accuracy, val_loss = train(model, k_epochs =30, lr =0.001)
Code
fig, axarr = plt.subplots(1, 2, figsize = (8, 3.5))ax = axarr[0]ax.plot(train_loss, color ="black", label ="Training")ax.plot(val_loss, color ="firebrick", label ="Validation")ax.set_title("Cross-Entropy Loss")ax.set_xlabel("Epoch")ax.set_ylabel("Loss")ax = axarr[1]ax.plot(train_accuracy, color ="black", label ="Training")ax.plot(val_accuracy, color ="firebrick", label ="Validation")ax.set_xlabel("Epoch")ax.set_ylabel("Accuracy")ax.set_title("Classification Accuracy")ax.set(ylim = (0, 1))plt.tight_layout()l = ax.legend()
Figure 13.4: Training curves for the logistic regression model. The left panel shows the training and validation loss over time, and the right panel shows the training and validation accuracy over time.
This model is not yet done training, and additional epochs might improve the performance. For the purposes of these notes we won’t push it further than that.
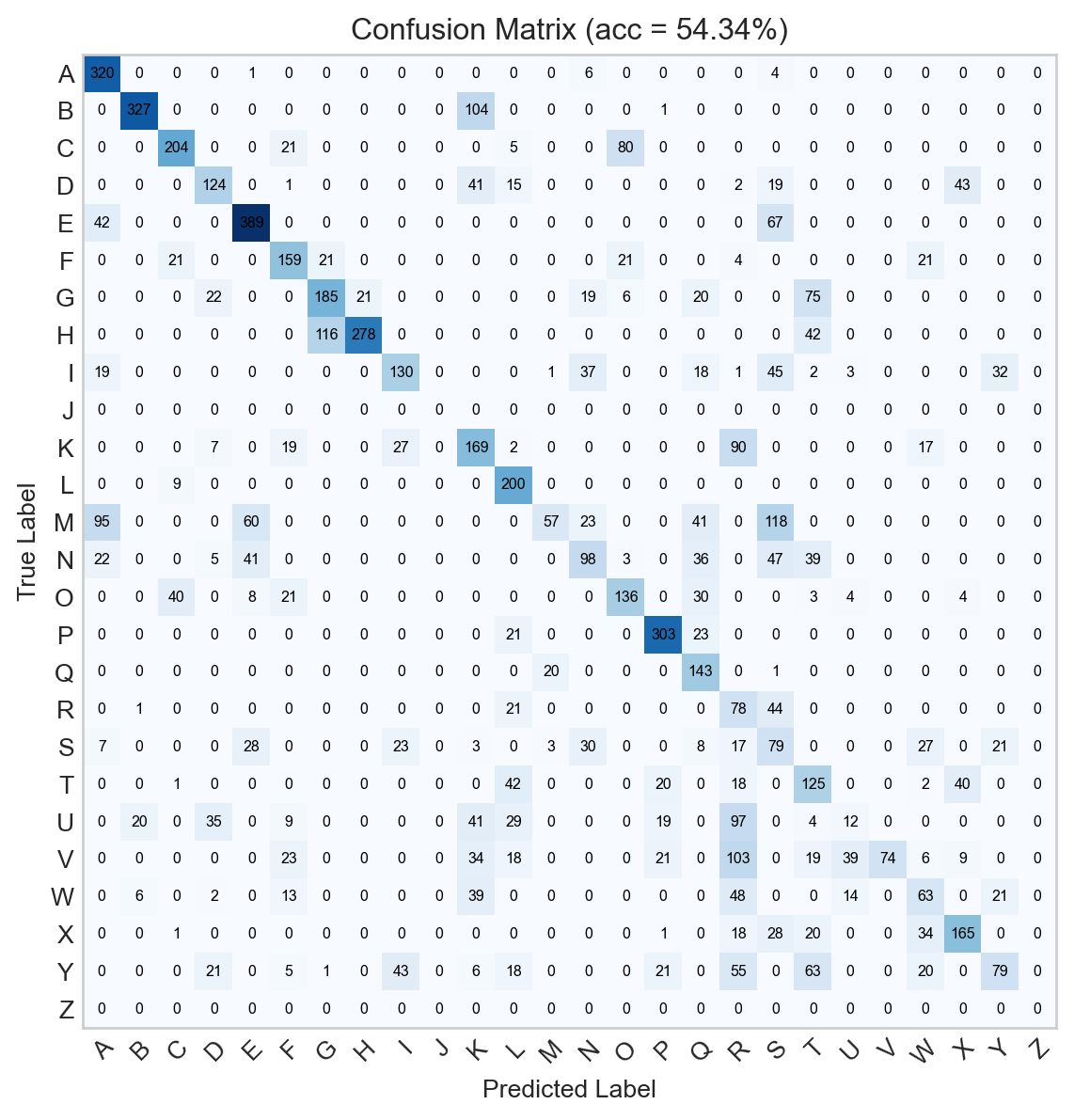
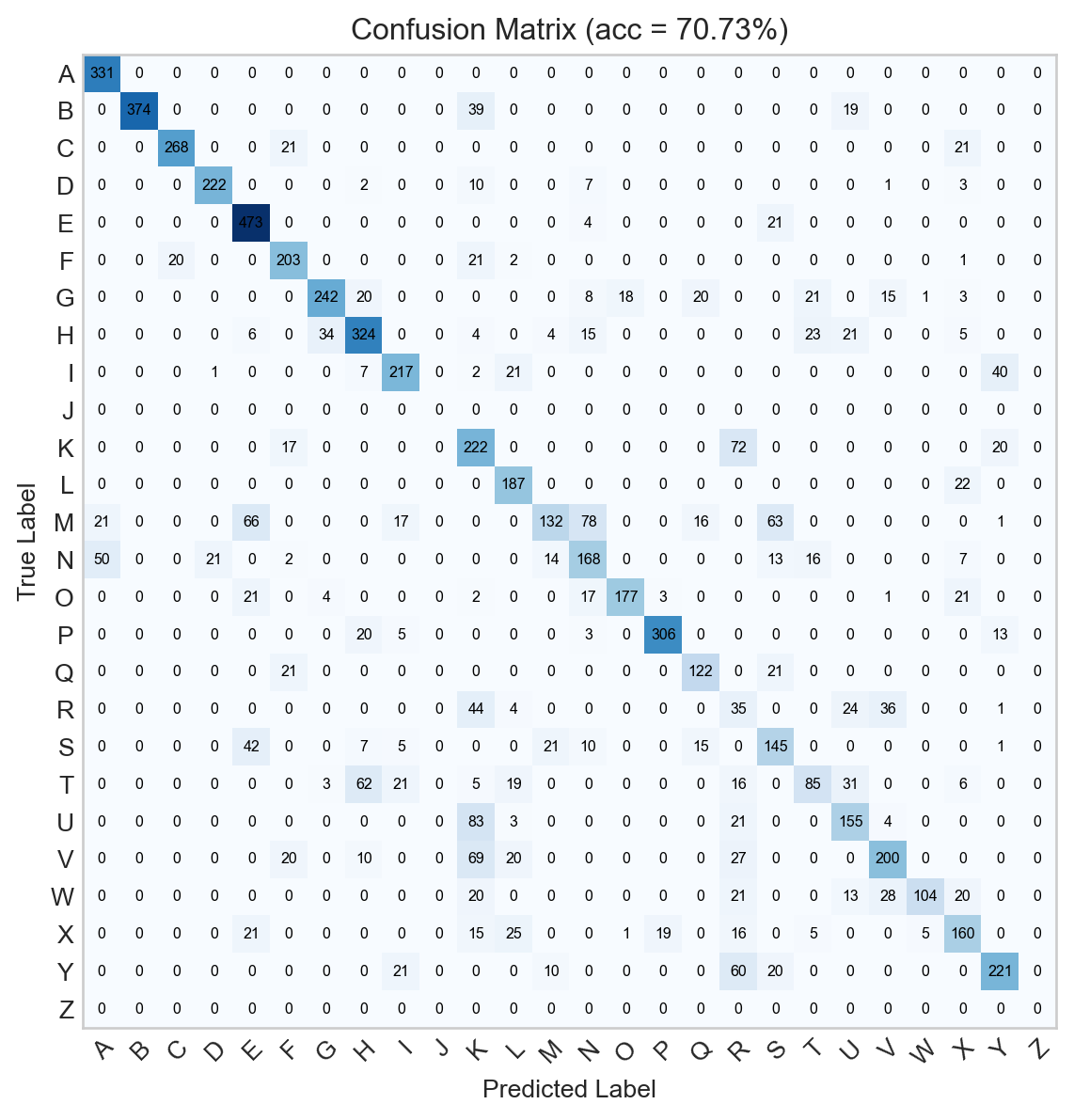
Already, the confusion matrix for the trained model looks much better:
Figure 13.5: Confusion matrix for the logistic regression model.
Although we can see that the model is often successful, 54% accuracy leaves a lot of room for improvement. Can we do better?
Convolutional Neural Networks
A common approach to feature extraction in images is to apply a convolutional kernel. A convolutional kernel is a component of a vectorization pipeline which is specifically suited to the structure of images. In particular, images are fundamentally spatial. We might want to construct data features which reflect not just the value of an individual pixel, but also the values of pixels nearby that one.
Convolutional kernels are not related in any way to positive-definite kernels used in kernel classifiers, another important ML topic.
The idea of an image convolution is pretty simple. We define a square kernel matrix containing some numbers, and we “slide it over” the input data. At each location, we multiply the data values by the kernel matrix values, and add them together. Here’s an illustrative diagram:
In this example, the value of 19 is computed as \(0\times 0 + 1\times 1 + 3\times 2 + 4\times 3 = 19\).
Manual Kernel Convolutions for Feature Extraction
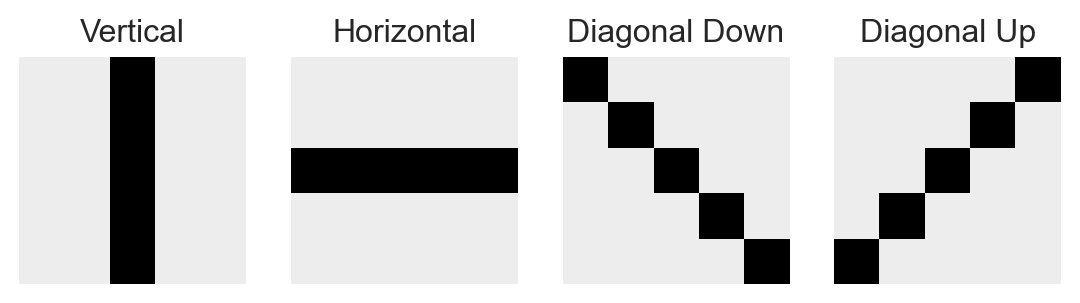
For a long time, a common approach to image classification and related computer vision tasks was to hand-engineer a set of convolutional kernels designed to extract certain specific features of interest from the image. For example, here are some kernels designed to extract vertical, horizontal, and diagonal features from an image:
When we apply these convolutional kernels to an image, we obtain a new image in which the value of each pixel corresponds to the “alignment” of the image with the kernel at that point. Here are some examples:
Code
def apply_convolutions(X): # this is actually a neural network layer -- we'll learn how to use these# in that context soon conv1 = Conv2d(1, 4, 5).to(device) # 1 input channel, 4 output channels, 5x5 kernels# need to disable gradients for this layerfor p in conv1.parameters(): p.requires_grad =False# replace kernels in layer with our custom ones conv1.weight[0, 0] = Parameter(vertical) conv1.weight[1, 0] = Parameter(horizontal) conv1.weight[2, 0] = Parameter(diag1) conv1.weight[3, 0] = Parameter(diag2)# apply to input data and disable gradientsreturn conv1(X).detach()def kernel_viz(pipeline): fig, ax = plt.subplots(5, 5, figsize = (8, 8)) X_convd = pipeline(X_train).cpu()for i inrange(5): for j inrange(5):if i ==0: ax[i,j].imshow(X_train[j, 0].cpu())else: ax[i, j].imshow(X_convd[j,i-1]) ax[i,j].tick_params( axis='both', which='both', bottom=False, left=False, right=False, labelbottom=False, labelleft=False) ax[i,j].grid(False) ax[i, 0].set(ylabel = ["Original", "Vertical", "Horizontal", "Diag Down", "Diag Up"][i])kernel_viz(apply_convolutions)
Figure 13.7: Example of four kernel convolutions applied to five sample input images.
In principle, these convolutions could be used to define “scores” for each image: for example, summing up the “horizontal” values could give an image a score reflecting the prevalence of horizontal lines in the image.
A limitation of this approach is that we have to engineer all our kernels in advance. Wouldn’t it be simpler if we could simply initialize the kernels randomly and let the data tell us what the useful kernels might be?
Learnable Kernels
Fortunately, neural networks give us a framework for doing exactly that. The key insight is that the kernel convolution operation is, fundamentally, just a sequence of pairwise multiplications followed by an addition. This means that the convolution is a linear operation. This means:
Kernel Convolution is a Matrix Multiplication
Actually writing down the matrix multiplication formula for kernel convolution is complex and involves “doubly-index matrices,” so we won’t do that here. The key point is that, since the convolution operation is a matrix multiplication, we can treat it with the same framework as we have been using for other linear models – we just need to throw it in as a layer in a neural network.
A Minimal Convolutional Model
Just inserting a convolutional layer on its own won’t lead to substantial gains because, as we saw, composing linear layers doesn’t actually add that much. Instead, we can compose the convolutional layer with a nonlinearity (e.g. ReLU) and a final linear layer to get a minimal convolutional model. Since our output layer is a Linear layer, we still need to Flatten the output of the convolutional layer before feeding it into the linear layer.
Specify that our images have only one input channel (greyscale), 4 output channels (we’ll try learning 4 kernels), and the kernels have shape 5x5 pixels.
2
Apply nonlinearity.
3
Flatten the output of the convolutional layer to feed into the linear layer.
4
Apply the linear layer. The input dimension reflects the presence of 4 channels whose outputs have shape 24x24 pixels, and 26 output classes.
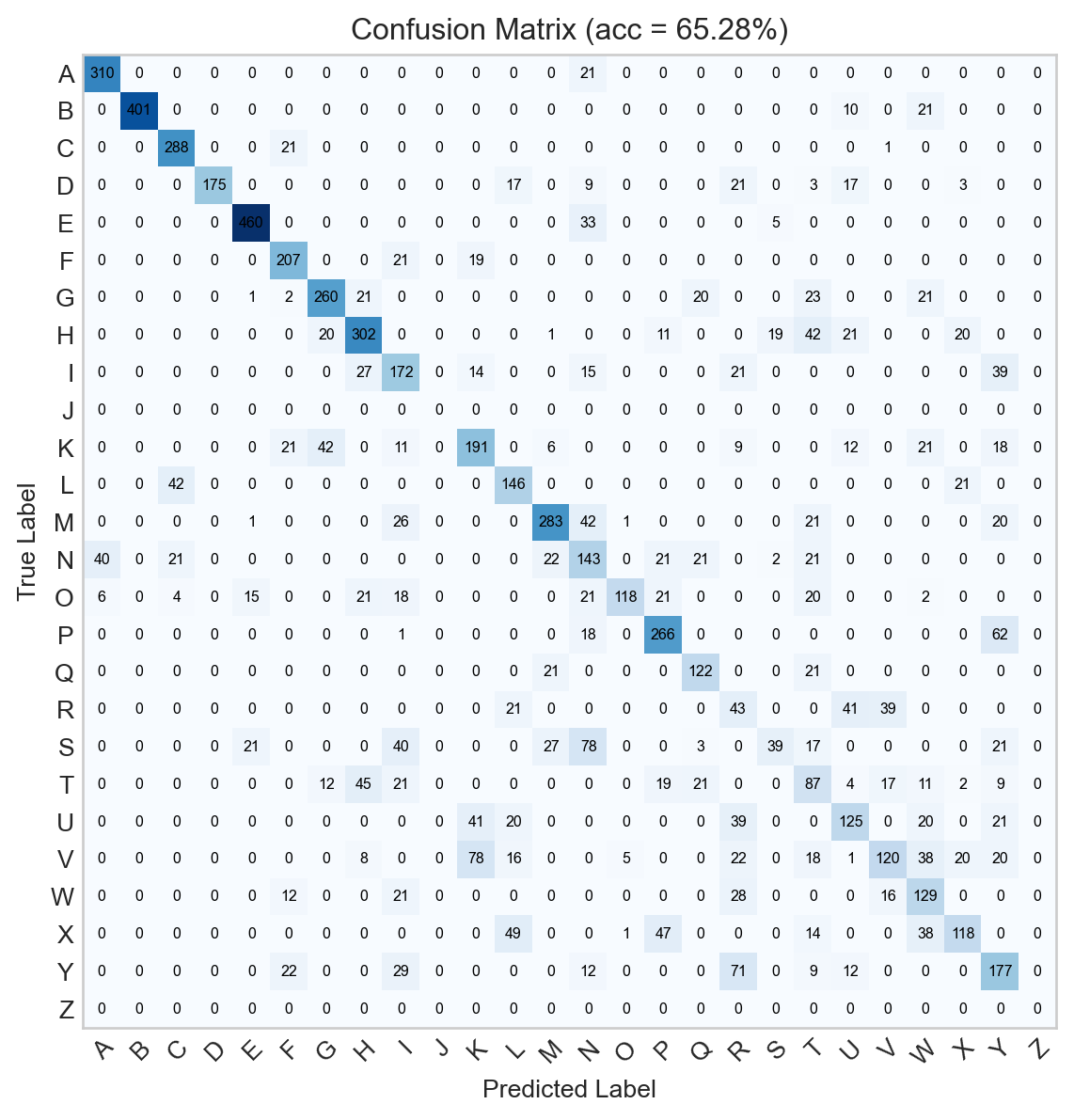
Figure 13.9: Confusion matrix for the minimal convolutional neural network. .
The minimal model is already able to somewhat exceed the performance of the logistic regression model, even after fewer epochs of training.
More Complex Convolutional Models
A common approach to building more complex convolutional models is to stack multiple convolutional layers on top of each other, with nonlinearities in between. This allows the model to learn more complex features at different levels of abstraction. For example, the first convolutional layer might learn to detect edges, while the second convolutional layer might learn to detect combinations of edges that form shapes, and the third convolutional layer might learn to detect combinations of shapes that form objects.
Pooling
An issue with the stacking approach, however, is that the data remains very large throughout the pipeline, with each convolution reducing the data just by a few pixels in each dimension. This also prevents convolutional kernels at later layers from combining data from far away regions in the image. To address this, let’s reduce the data in a nonlinear way. We’ll do this with max pooling. You can think of it as a kind of “summarization” step in which we intentionally make the current output somewhat “blockier.” Technically, it involves sliding a window over the current batch of data and picking only the largest element within that window. Here’s an example of how this looks:
Figure 13.10: Illustration of max-pooling. Image credit: Computer Science Wiki
A useful effect of pooling is that it reduces the number of features in our data. In the image above, we reduce the number of features by a factor of \(2\times 2 = 4\).
Let’s now construct a complex model that layers convolutional layers, nonlinearities, and pooling layers.
There’s nothing special about the engineering of this model: I just stacked a few convolution and pooling layers together and then added a few more linear outputs.
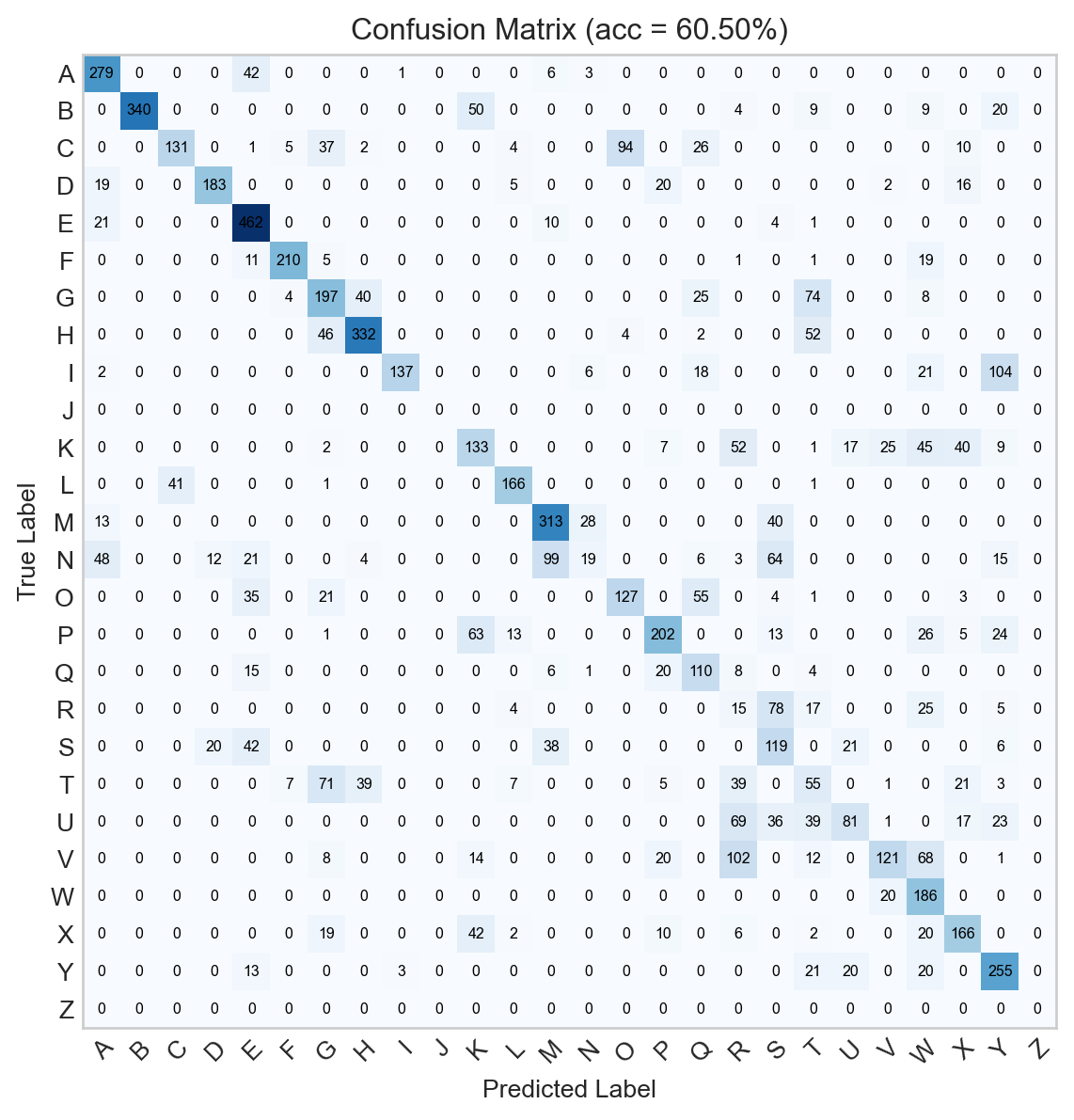
Figure 13.12: Confusion matrix for the convolutional neural network.
The additional complexity of this model enables it to achieve much higher accuracy than the previous models we’ve discussed, although more thorough training runs would be necessary for a full assessment.
Inspecting Learned Features
Like we saw last time, it’s possible to inspect the features learned by a neural network at different levels of abstraction. Let’s see some of the features learned by the model for a single image:
Figure 13.13: Example image used as base for the experiment in Figure 13.14.
In the code block below, we show the outputs of different layers of the model when applied to this original image. Each layer’s output can be thought of as a different “representation” of the original image, with different features extracted at each layer.
Figure 13.14: Sample learned features at varying levels of abstraction from the convolutional model, using Figure 13.13 as a base. Note that the features in each row are not necessarily directly related to each other.
Interpreting these learned features can be tricky and is not generally recommended without context and many additional experiments.
Onward
In the next lecture, we’ll consider some additional practical considerations that arise when working with spatially-structured data and convolutional neural networks.