From Global to Local Structure in Hypergraph Data Science
Vermont-KIAS Workshop | September 28th, 2023
Hi everyone!
I’m Phil Chodrow. I’m an applied mathematician by training. These days my interests include:
- Network models + algorithms
- Dynamics on networks
- Data science for social justice
- Undergraduate pedagogy
Hi everyone!
I’m a new(ish) assistant professor of computer science at Middlebury College in Middlebury, Vermont.

Middlebury is a small primarily-undergraduate institution (PUI) about 50 minutes south of here.
Hypergraphs
A hypergraph is a generalization of a graph in which edges may contain an arbitrary number of nodes.
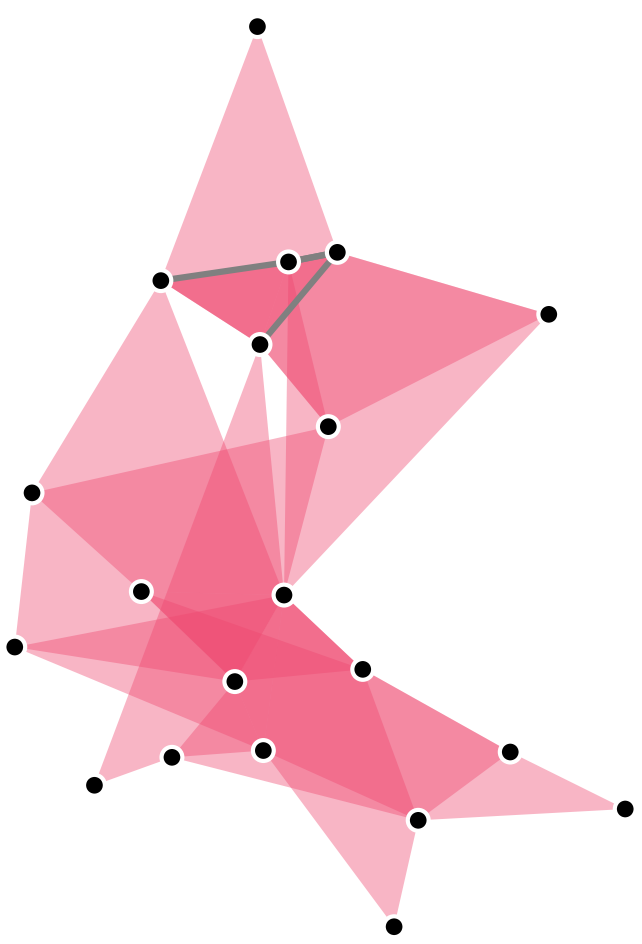
XGI let’s gooooo
Dynamics on Hypergraphs are Different
Nonlinear interactions on edges allow qualitatively distinct behavior when compared to the graph case.
Sorry I missed so many cool talks this week on this topic…
![]()
Schawe + Hernandez (2022). Higher order interactions destroy phase transitions in Deffuant opinion dynamics model. Nature Communications Physics
What about…just the structure?
What is special, distinctive, or unusual about the hypergraph itself?
What can we learn from the hypergraph that we couldn’t learn from a dyadic graph?
Very often, this question has been interpreted in terms of generalization: how can we usefully extend a familiar graph technique to the hypergraph setting?
XGI let’s gooooo
Graph Projections
We can work on graphs induced from the the hypergraph, such as the clique-projection or bipartite representation.
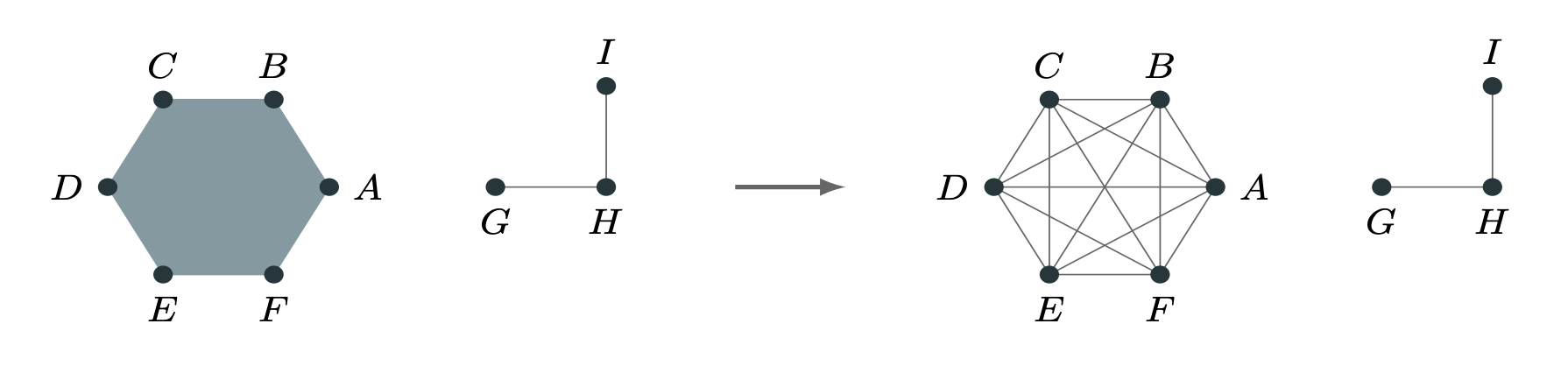
This is Mathematically Uninteresting™, but (unfortunately?) often hard to beat.
PSC (2020). Configuration models of random hypergraphs. Journal of Complex Networks, 8(3):cnaa018
“X but for hypergraphs”
Global analyses aim to say something about the macroscopic structure of the entire graph.
- Centrality
- Core-periphery
- Community detection/clustering
- Embedding
Many of the global questions we ask about hypergraphs are the same as the global questions we ask about graphs!
XGI let’s gooooo
“X but for hypergraphs”

Benson (2019). Three hypergraph eigenvector centralities. SIAM Journal on Mathematics of Data Science
“X but for hypergraphs”

Tudisco + Higham (2023). Core-Periphery Detection in Hypergraphs. SIAM Journal on Mathematics of Data Science
“X but for hypergraphs”

Chodrow (2020). Configuration models of random hypergraphs. Journal of Complex Networks
“X but for hypergraphs”

Chodrow et al. (2021). Generative hypergraph clustering: from blockmodels to modularity. Science Advances
“X but for hypergraphs”

Chodrow et al. (2023). Nonbacktracking spectral clustering of nonuniform hypergraphs. SIAM Journal on Mathematics of Data Science
Case Study: Hypergraph Community Detection
Problem: assign a discrete label vector \(\mathbf{z} \in \mathcal{Z}^n\) to the nodes of a hypergraph in a way that reflects “meaningful” structure.
Also called “clustering” or “partitioning.”
We often do this with a stochastic blockmodel (SBM), which expresses a probability distribution over hypergraphs with cluster structure.
Review in
PSC, N. Veldt, and A. R. Benson (2021). Generative hypergraph clustering: From blockmodels to modularity. Science Advances, 7:eabh1303
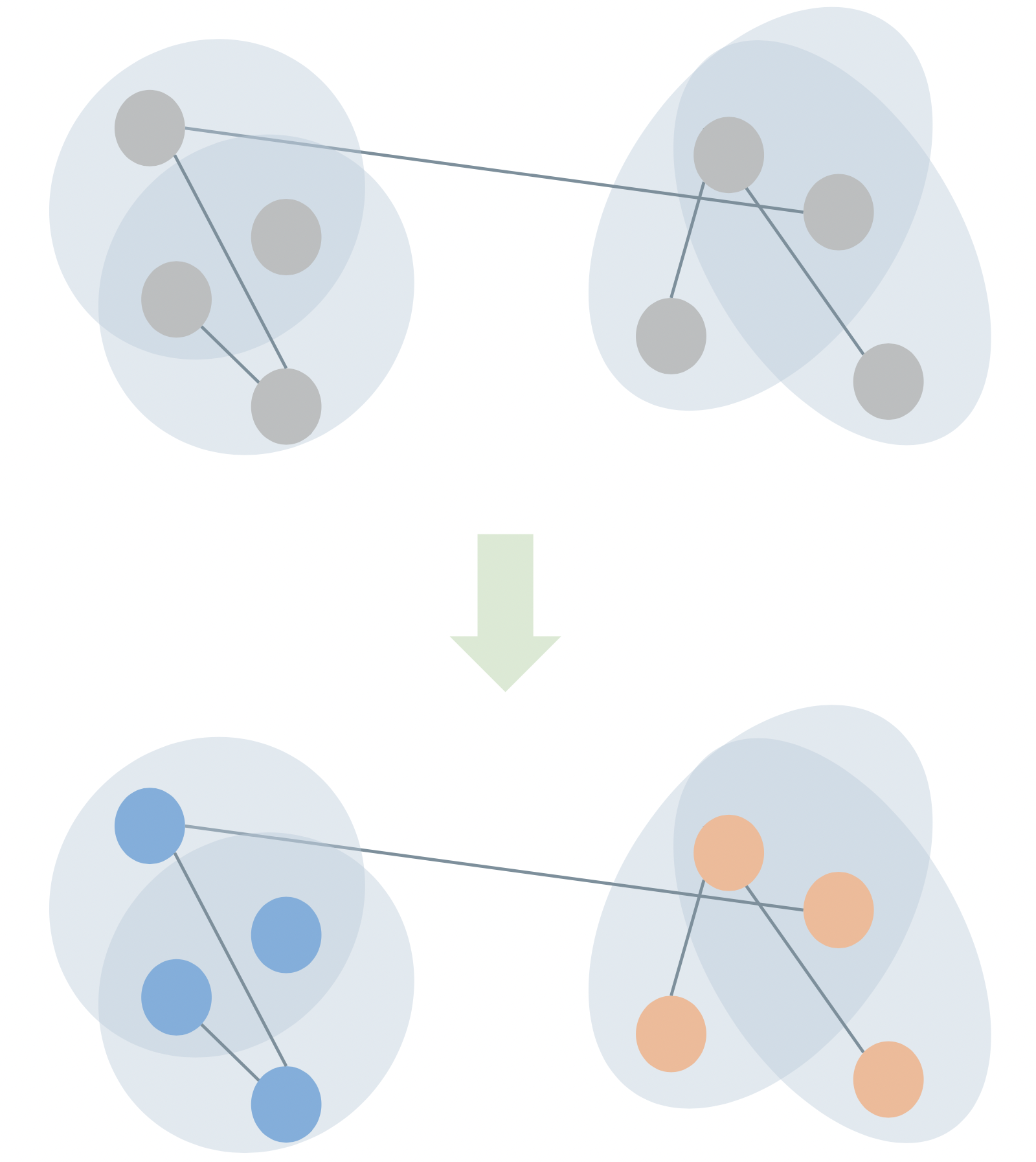
Case Study: Hypergraph Community Detection
Problem: assign a discrete label vector \(\mathbf{z} \in \mathcal{Z}^n\) to the nodes of a hypergraph in a way that reflects “meaningful” structure.
Also called “clustering” or “partitioning.”
We often do this with a stochastic blockmodel (SBM), which expresses a probability distribution over hypergraphs with cluster structure.
Review in
PSC, N. Veldt, and A. R. Benson (2021). Generative hypergraph clustering: From blockmodels to modularity. Science Advances, 7:eabh1303

It’s hard to beat global graph methods
Incorporating higher-order structure doesn’t always help!
Hypergraph methods outperform graph methods when edges of different sizes carry different signal about the structure you care about.
Every optimization-based graph/hypergraph algorithm is equally bad when averaged over possible data inputs.
Peel, Larremore, and Clauset (2017). The ground truth about metadata and community detection in networks. Science Advances

Motifs in Graphs
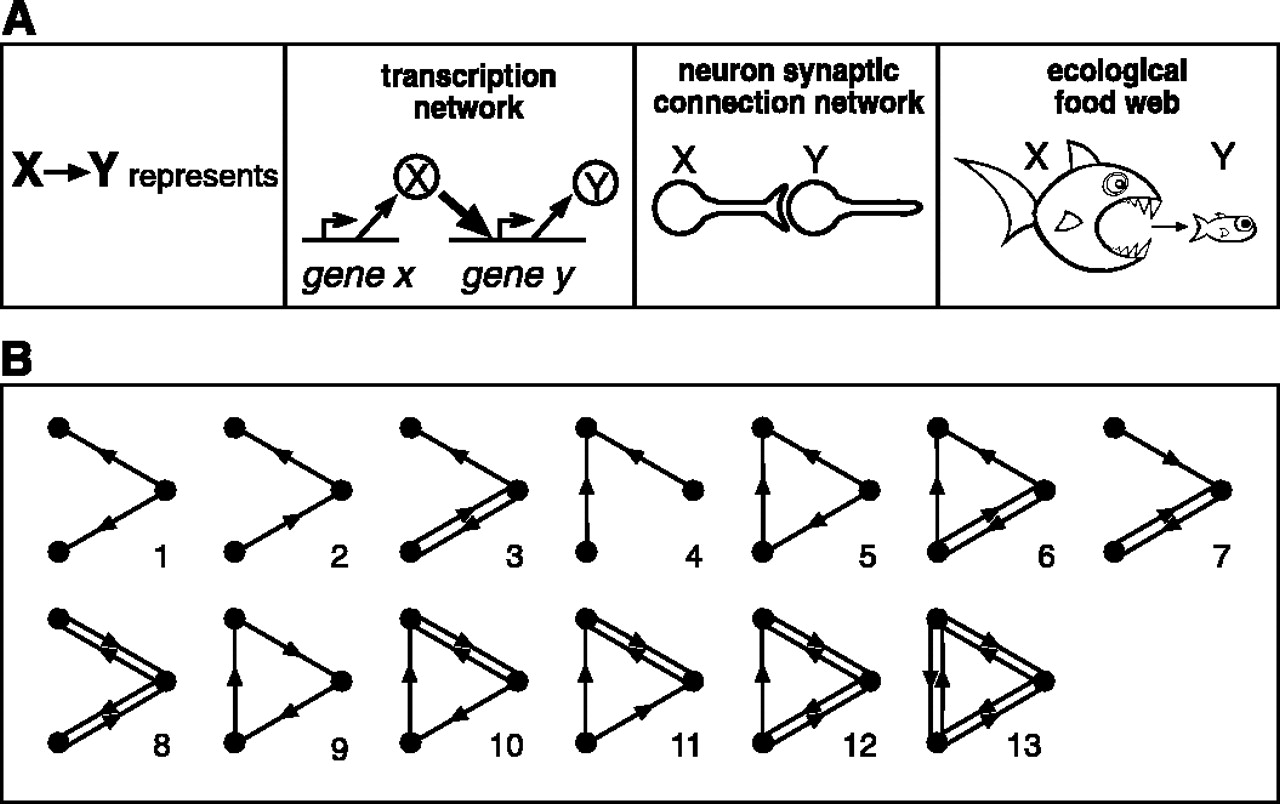
Milo et al. (2002). Network Motifs: Simple Building Blocks of Complex Networks. Science
Motifs in Graphs
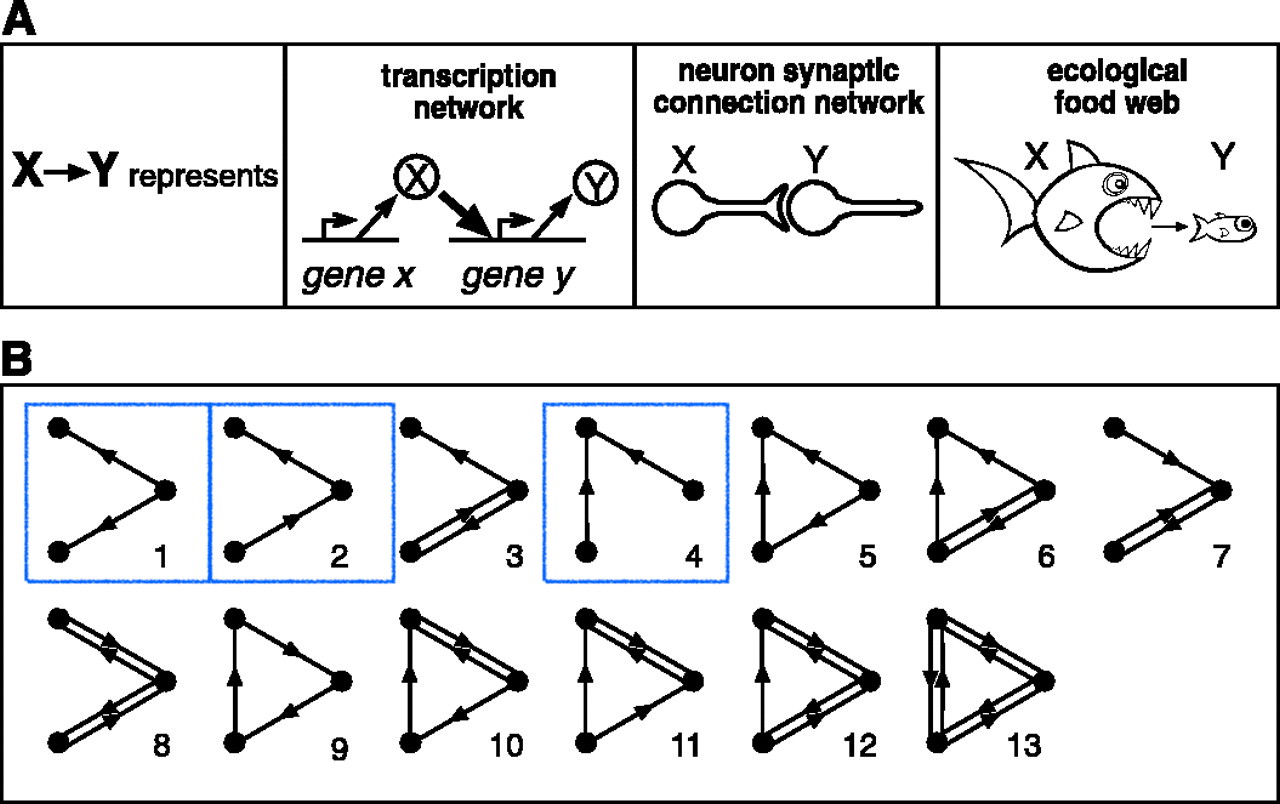
Milo et al. (2002). Network Motifs: Simple Building Blocks of Complex Networks. Science
2-edge motifs in undirected graphs

Hypergraph Motifs
Claim: What’s special about hypergraphs is that they have diverse, undirected, two-edge motifs: intersections.

Furthermore…
Large intersections are much more common in empirical data than would be expected by chance.
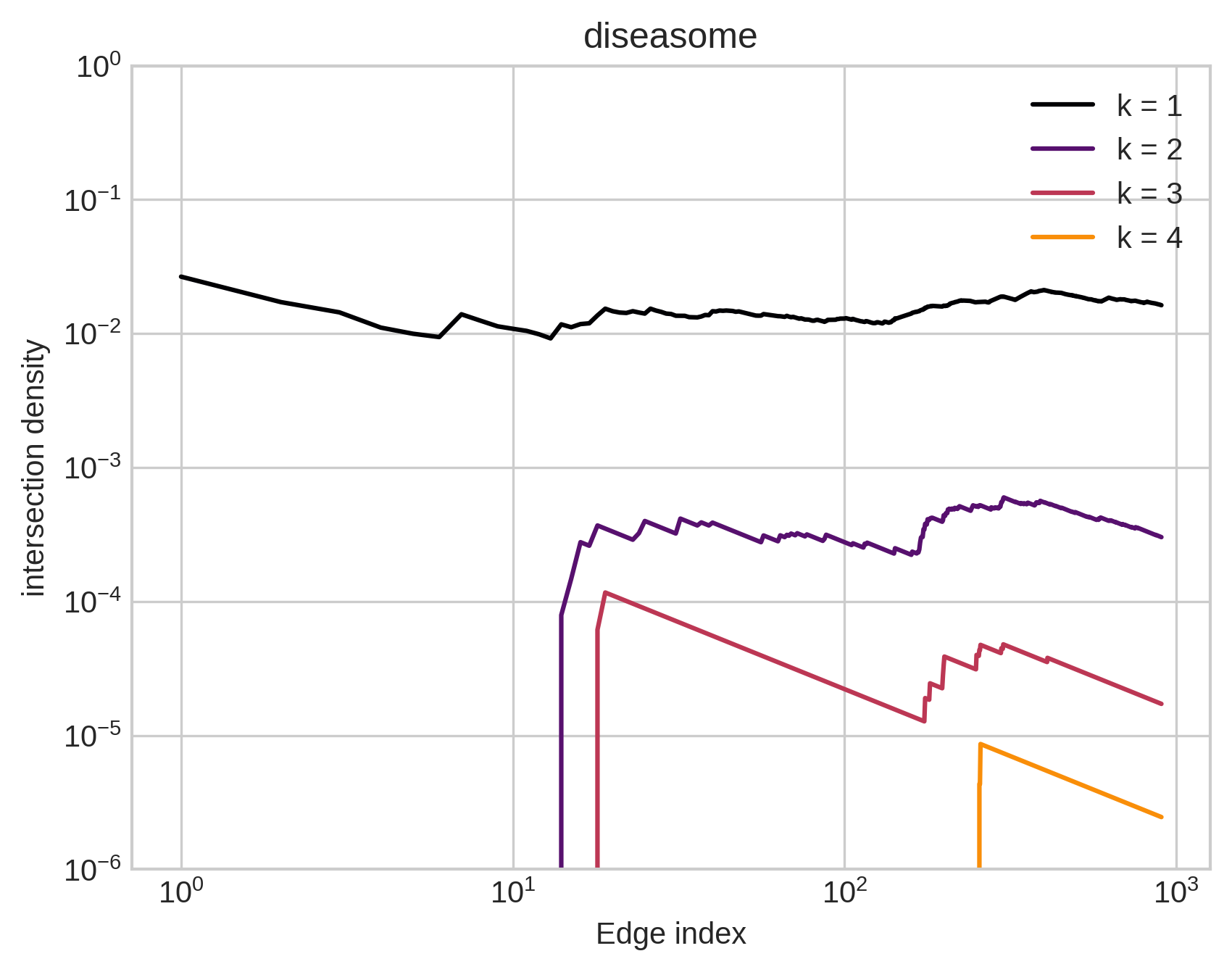
Benson et al. (2018). Simplicial closure and higher-order link prediction. PNAS
Chodrow (2020). Configuration models of random hypergraphs. JCN
Landry, Young, and Eikmeier (2023). The simpliciality of higher-order networks. arXiv:2308.13918
Ongoing work with…

Xie He
Mathematics
Dartmouth College

Peter Mucha
Mathematics
Dartmouth College
Mechanistic, interpretable, learnable models of growing hypergraphs.

In each timestep…

Select a random edge

Select random nodes from edge

Add nodes from hypergraph
Add novel nodes

Form edge

Repeat

Repeat

Formally
In each timestep \(t\):
- Start with an empty edge \(f = \emptyset\).
- Select an edge \(e \in H\).
- Accept each node from \(e\) into \(f\) with probability \(\alpha\) (condition on at least one).
- Add \(\mathrm{Poisson}(\beta)\) novel nodes.
- Add \(\mathrm{Poisson}(\gamma)\) nodes from \(H \setminus e\).
What can we learn?
A node is selected in this model by first being selected through edge sampling.
So, the edge-selection process samples nodes in proportion to their degrees.
Sound familiar…?
What can we learn?
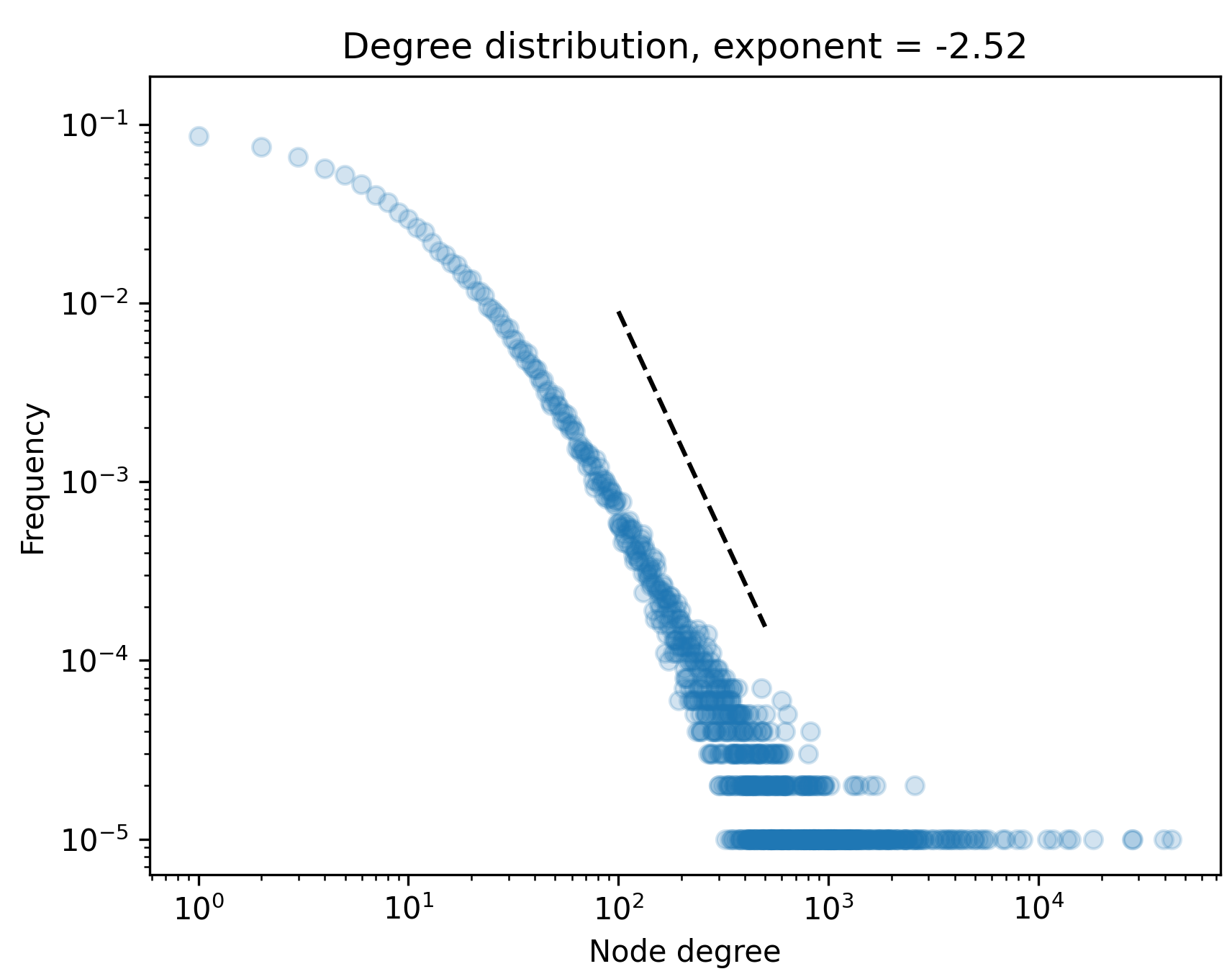
Proposition (He, Chodrow, Mucha ’23): As \(t\) grows large, the degrees of \(H_t\) converge in distribution to a power law with exponent
\[
p = 1 + \frac{1-\alpha +\beta +\gamma }{1-\alpha(1 + \beta + \gamma )}\;.
\] Proof: We derived this with approximate master equations; formal proof should follow standard techniques.
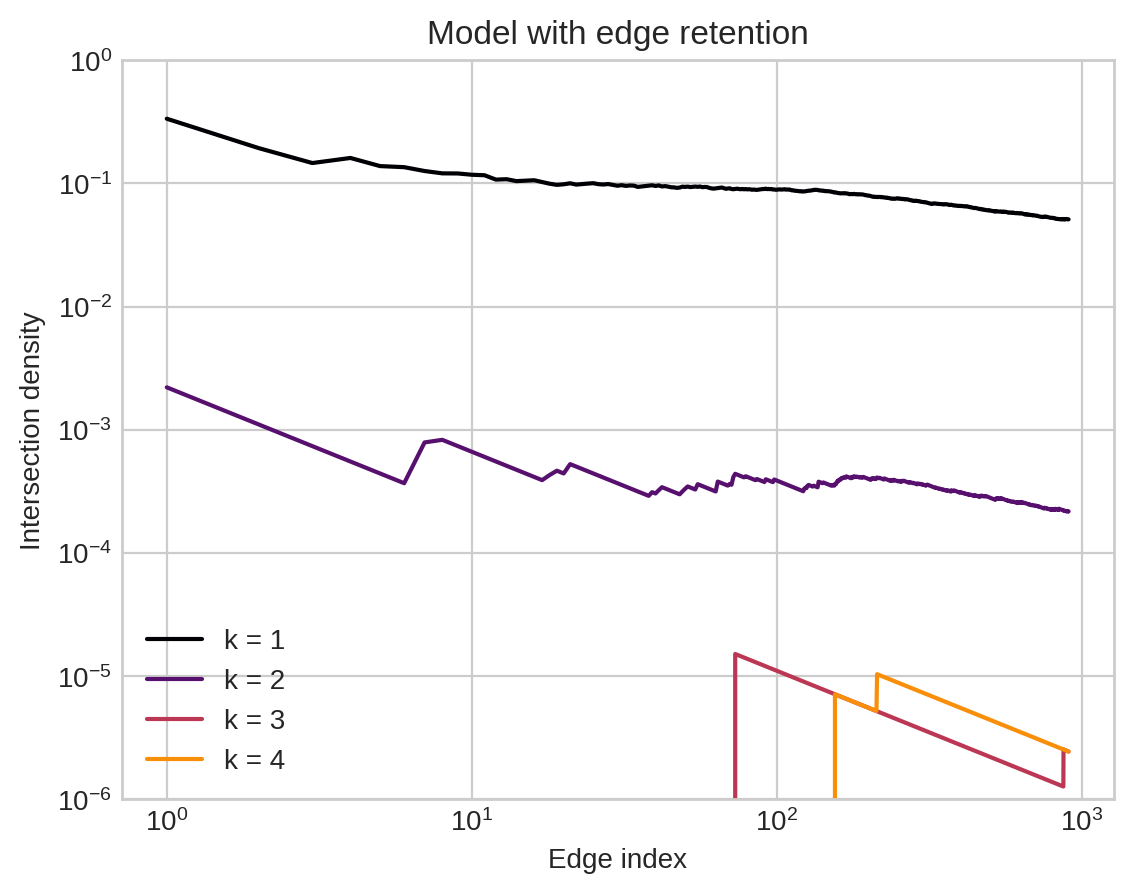
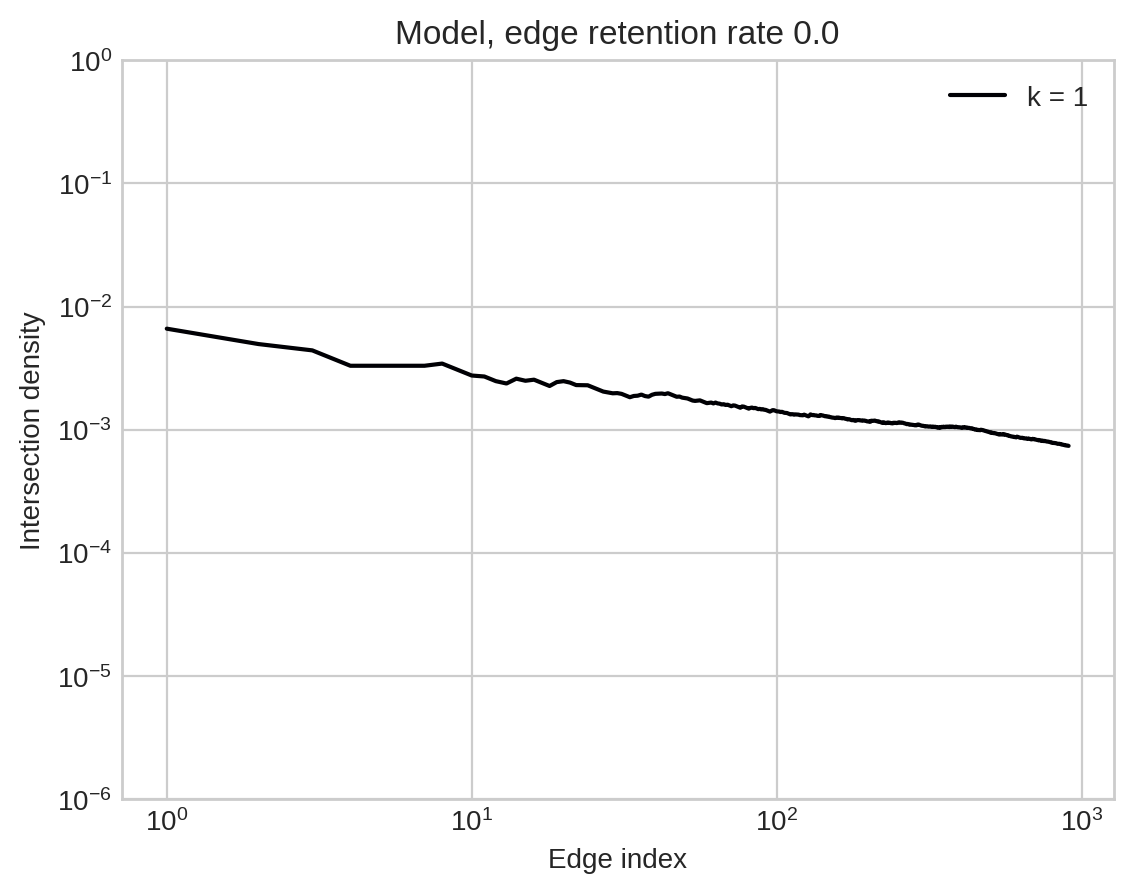
Modeling mechanistic processes helps us get closer to realistic local intersection features.
Some Formal Conjectures
Conjecture (HCM ’23): most models with no edge-retention mechanism have vanishing \(h\) intersections with rate \(g(H_t) = n_t^{-h}\).
In contrast, our model with edge-retention has vanishing \(h\) intersections with rate \(g(H_t) = n_t^{-1}\) for any \(h\).
Some Formal Conjectures
Let \(r_{ijk}^{(t)} = \mathbb{P}(\lvert e\cap f \rvert = t \text{ given that } \lvert e\rvert = i, \lvert f\rvert = j )\).
Conjecture (HCM ’23): There exists a linear map \(M\) with eigenvector \(\mathbf{p}\) such that \(\mathbf{r}^{(t)}n_t \rightarrow \mathbf{p}\) as \(t\rightarrow \infty\).
Strategy: This comes out of a recurrence for \(\mathbb{E}[r_{ijk}^{(t)}]\) but we have lots more work to do…
Ok, but can you learn the model?
Aim: given the sequence of edges \(e_t\), estimate:
- \(\alpha\), the edge retention rate.
- \(\beta\), the expected number of novel nodes.
- \(\gamma\), the expected number of nodes from \(H\).
Expectation maximization:
- For each edge \(e_t\), form a belief about which prior edge \(e \in H_{t-1}\) \(e_t\) was sampled from.
- Maximize the expected complete log-likelihood under this belief.
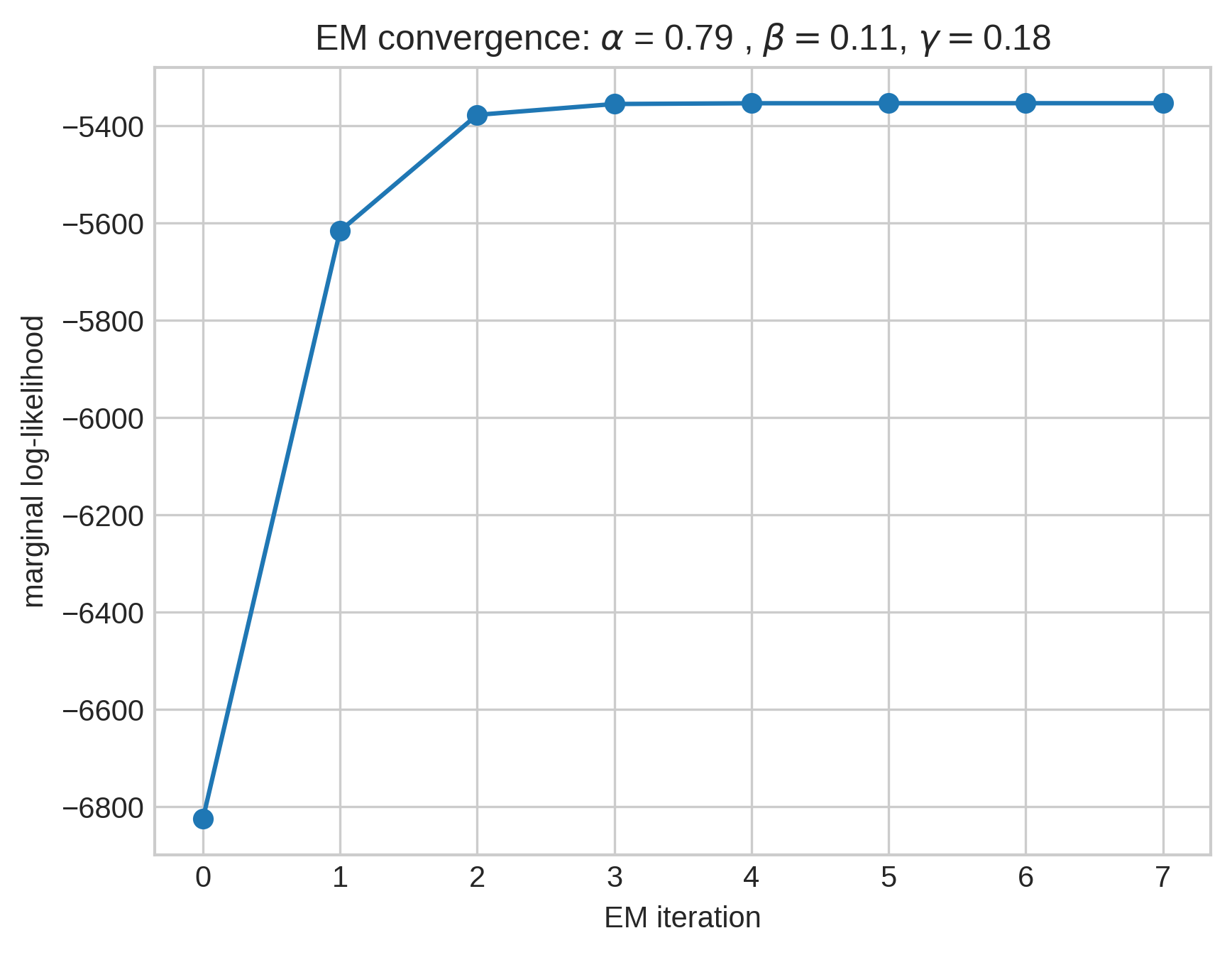
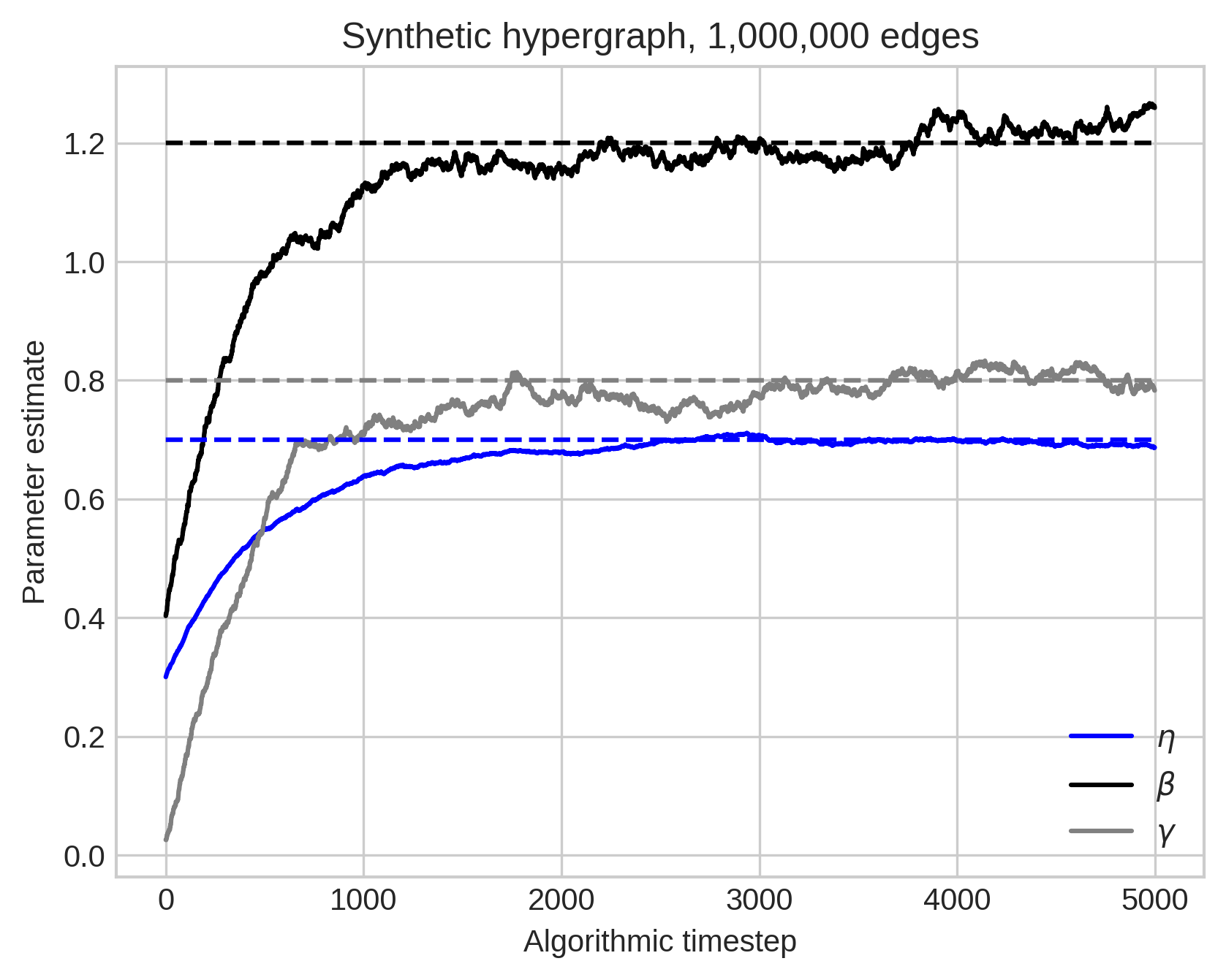
But…
We only did the first \(t = 1,000\) edges because the E-step requires forming and manipulating a \(t\times t\) matrix. This isn’t tractable for \(t > 10,000\) or so.
In stochastic EM, we sample a few edges at a time and update a moving-average of the parameter estimates.
Work in progress…
Summing Up
Hypergraphs are locally distinct from graphs in that they have interesting two-edge motifs (intersections).
Large intersections are much more prevalent than would be expected by chance.
Tractable, learnable models of hypergraph formation give us one route towards understanding this phenomenon.
Thanks everyone!
Xie He
Dartmouth College
Peter Mucha
Dartmouth College