A Critical Citizen’s Guide to Large Language Models
Middlebury College DLINQ | August 21st, 2023
Hi! I’m Phil.
I am an applied mathematician,
data scientist,
and STEM educator.
I like…
- Math models of social systems
- Statistics and machine learning
- Equity-oriented data science
- Critical lenses on tech
- Traditional martial arts
- Tea
- Star Trek: Deep Space 9
- Effective pedagogy

Large Language Models
A (generative) language model is an algorithm that generates text in partially random ways.
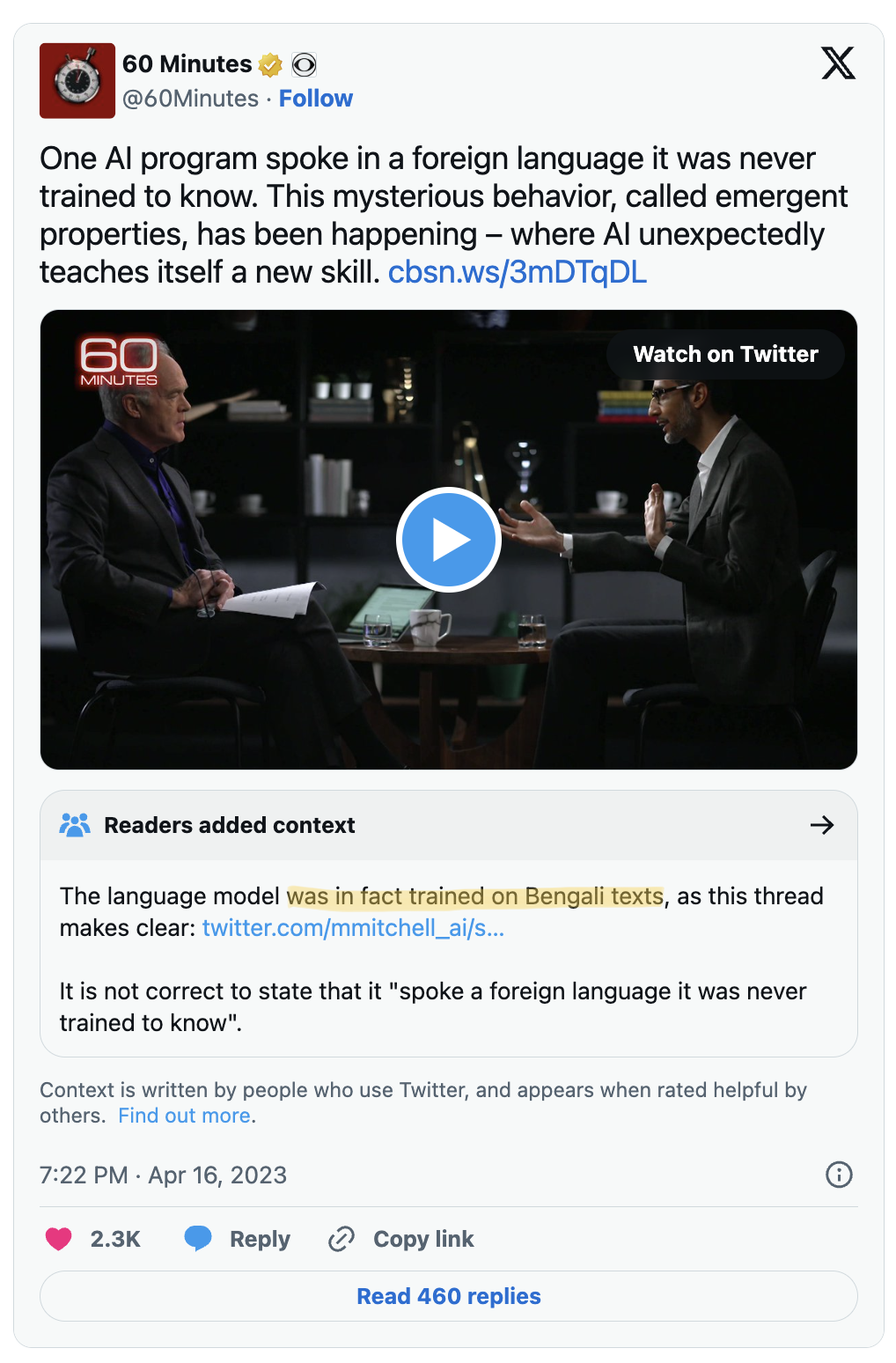
A language model is “large” when it is difficult to explain all of its behaviors purely in terms of structure and training (“emergence”).
Most language models aim to produce text that is human-like and constructive, using:
- Next-token prediction
- Reinforcement learning with human feedback (RLHF)
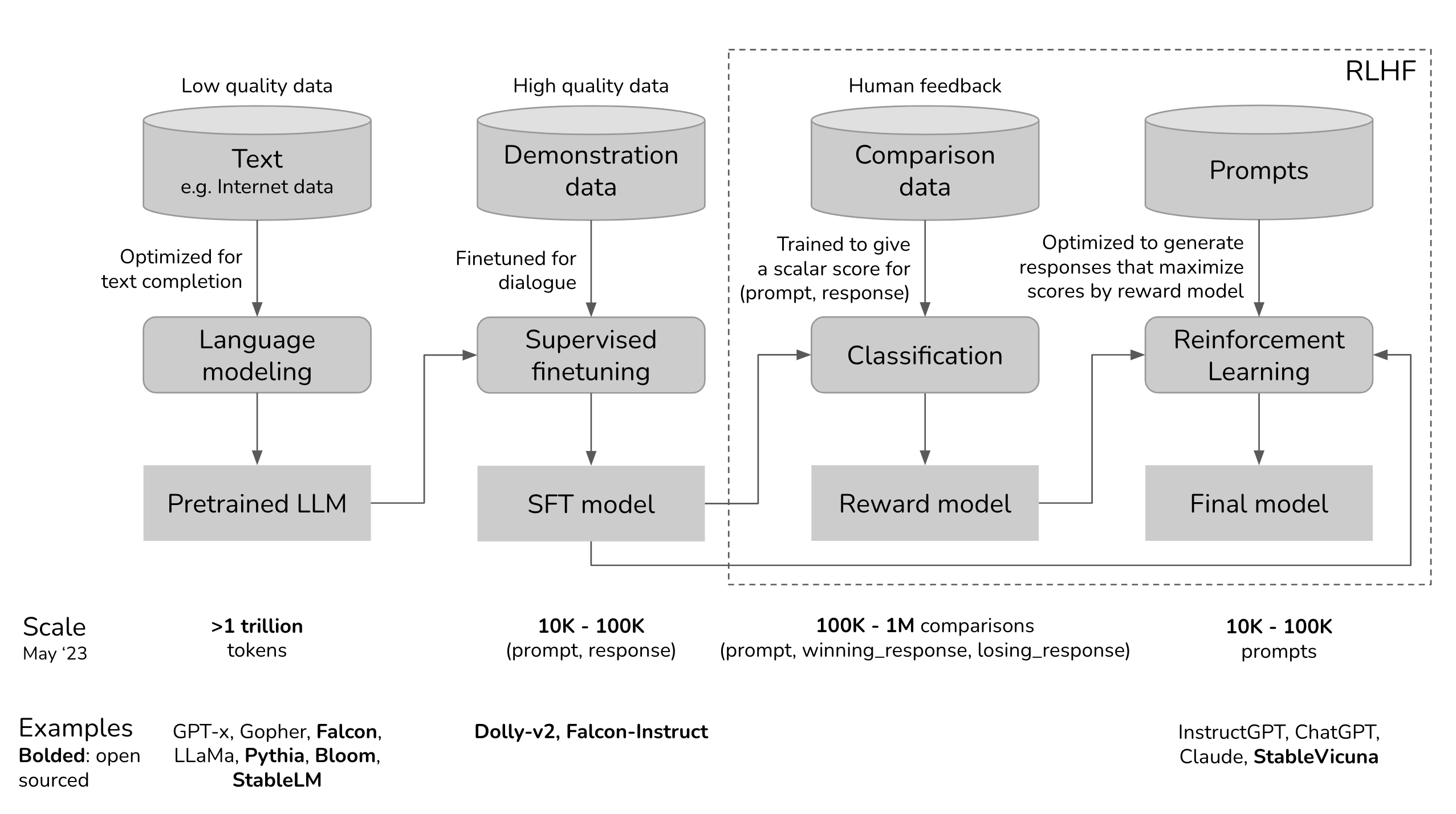
Image source: Chip Huyen
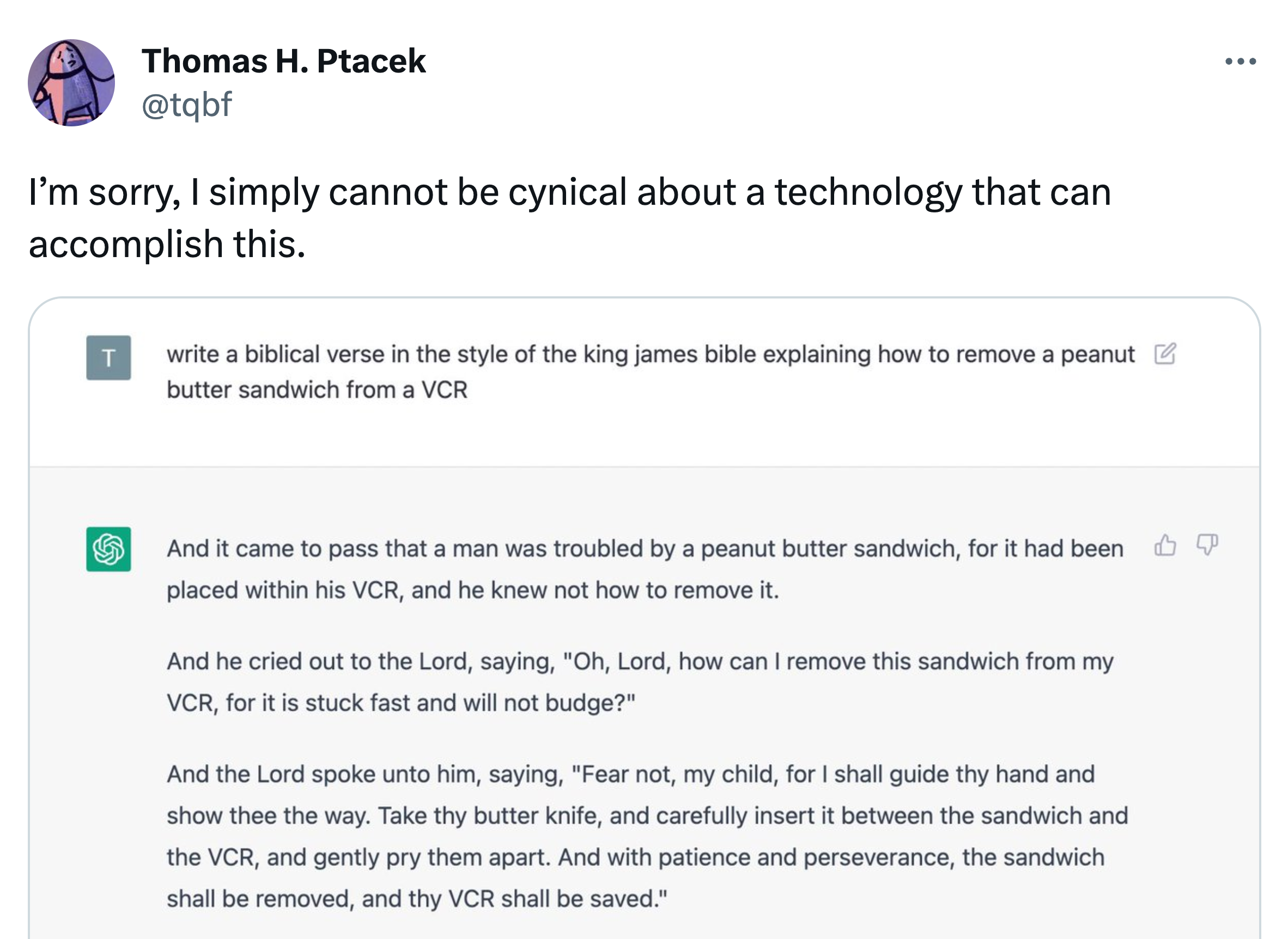
ChatGPT seems so human because it was trained by an AI that was mimicking humans who were rating an AI that was mimicking humans who were pretending to be a better version of an AI that was trained on human writing.
Google research estimates “millions” of annotation workers.
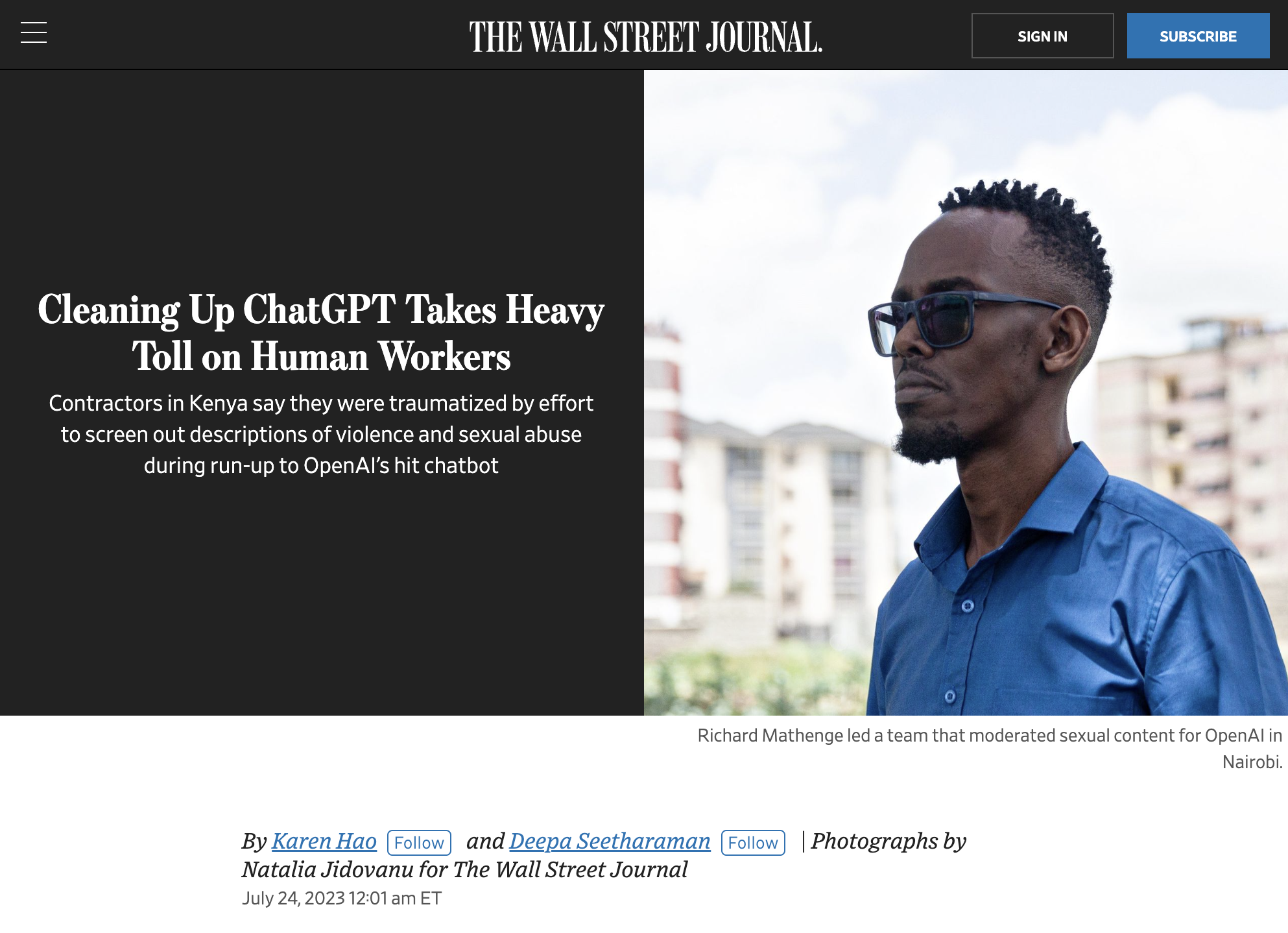





Online Information
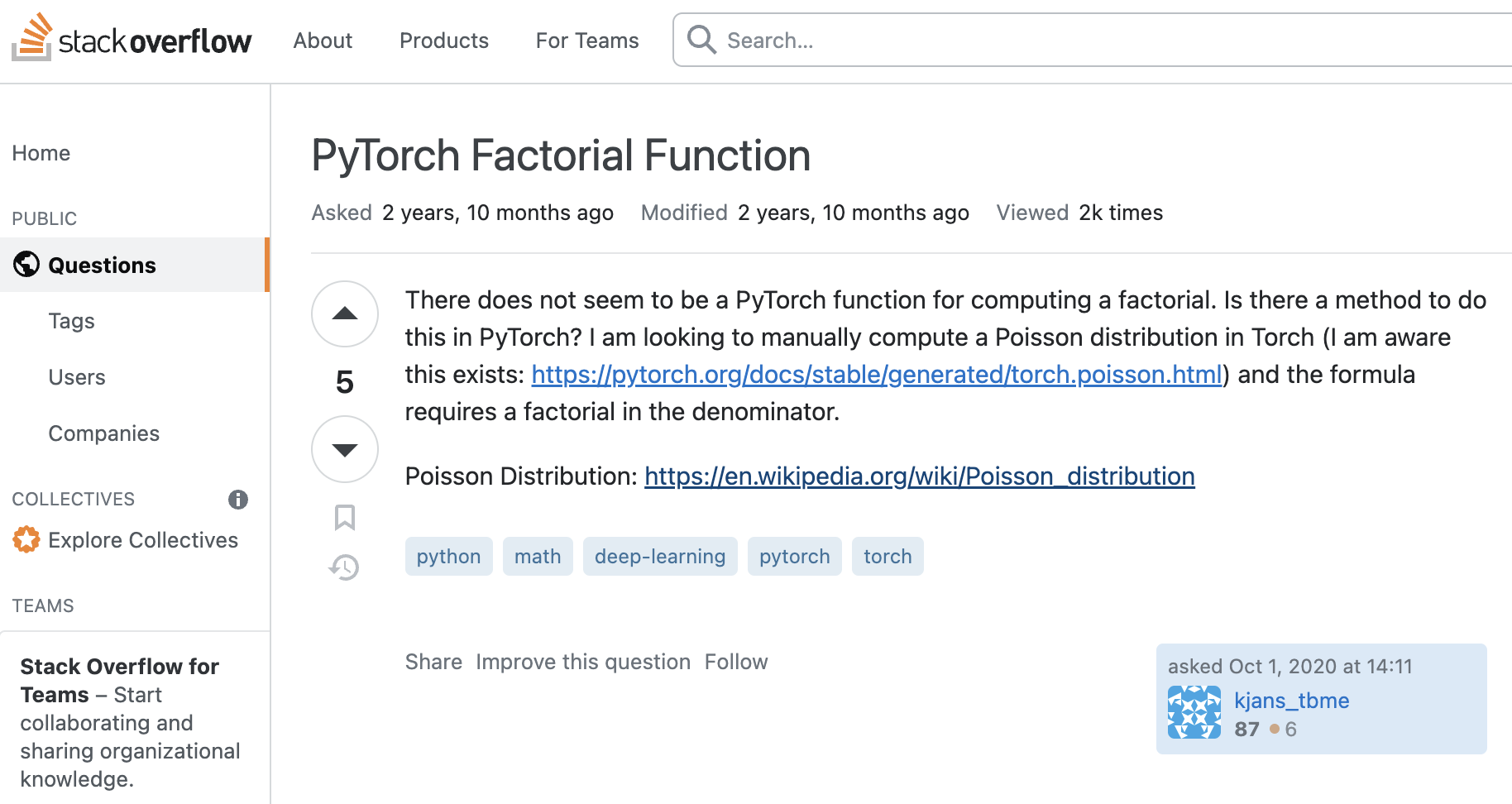
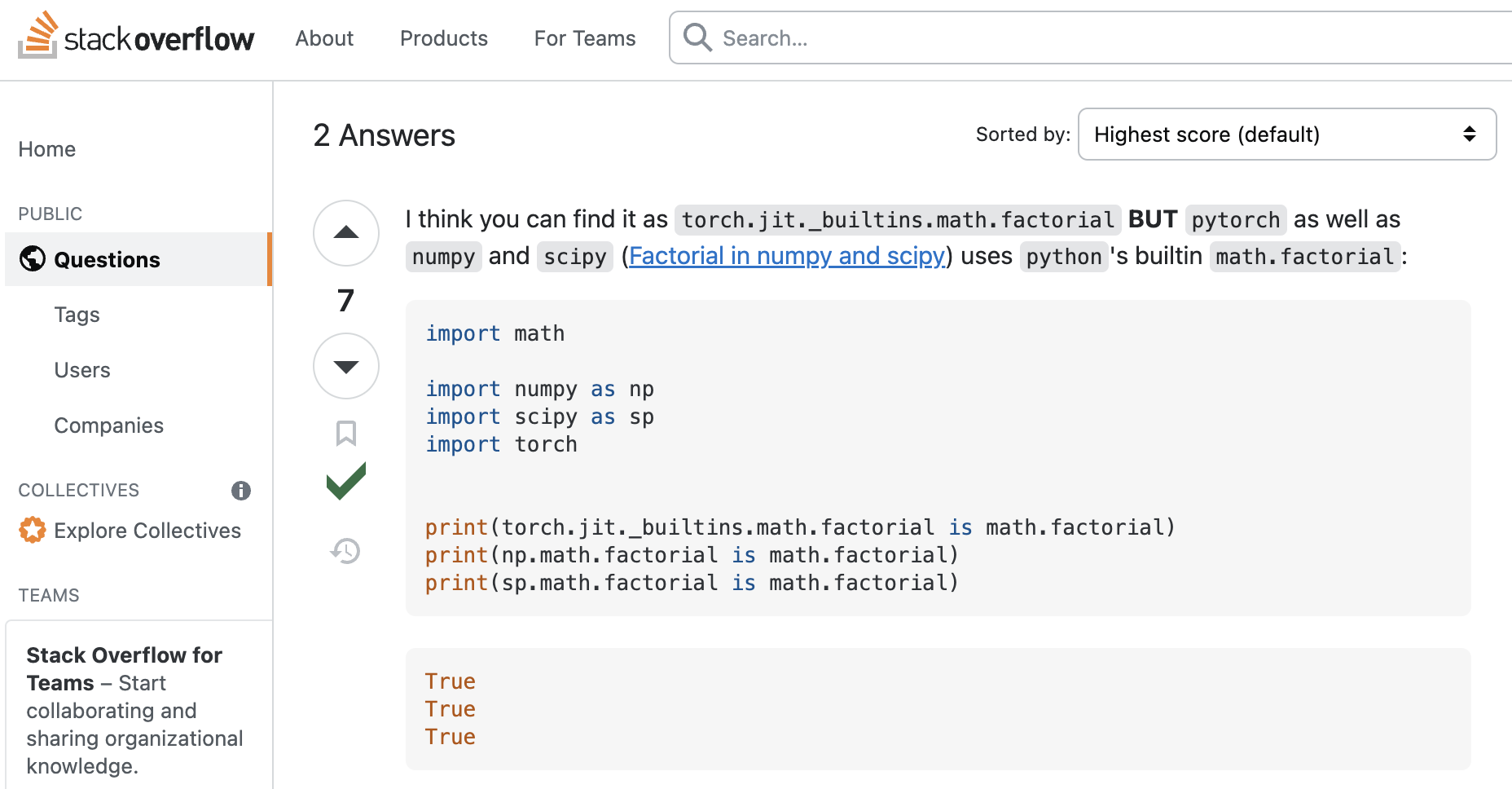
Data visualization by Ayhan Fuat Çelik
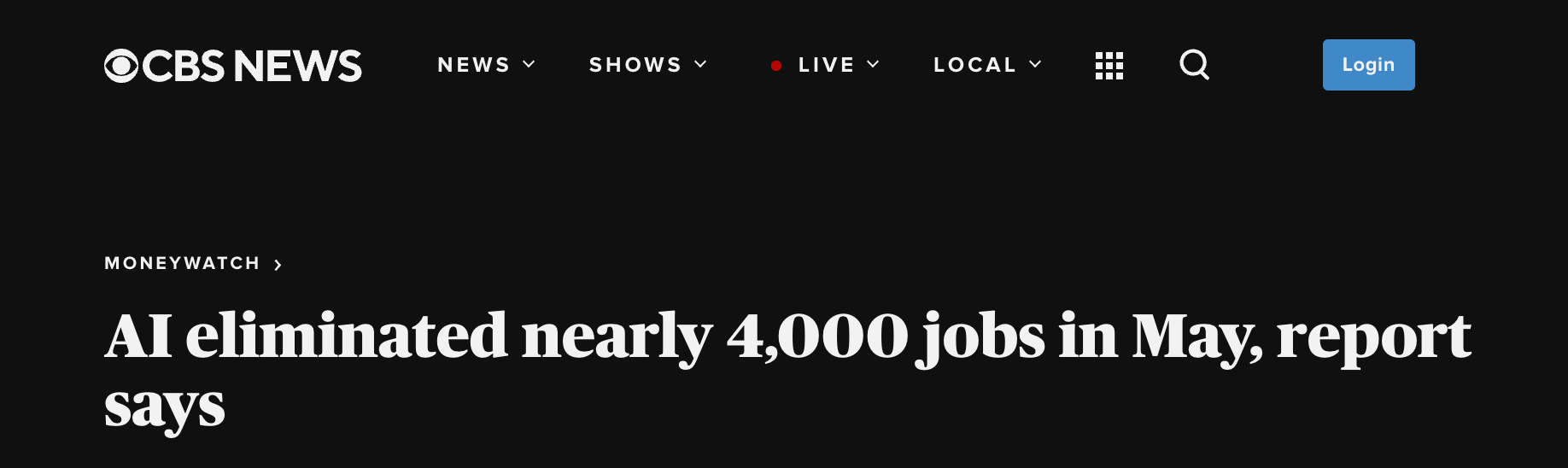
Labor Stability
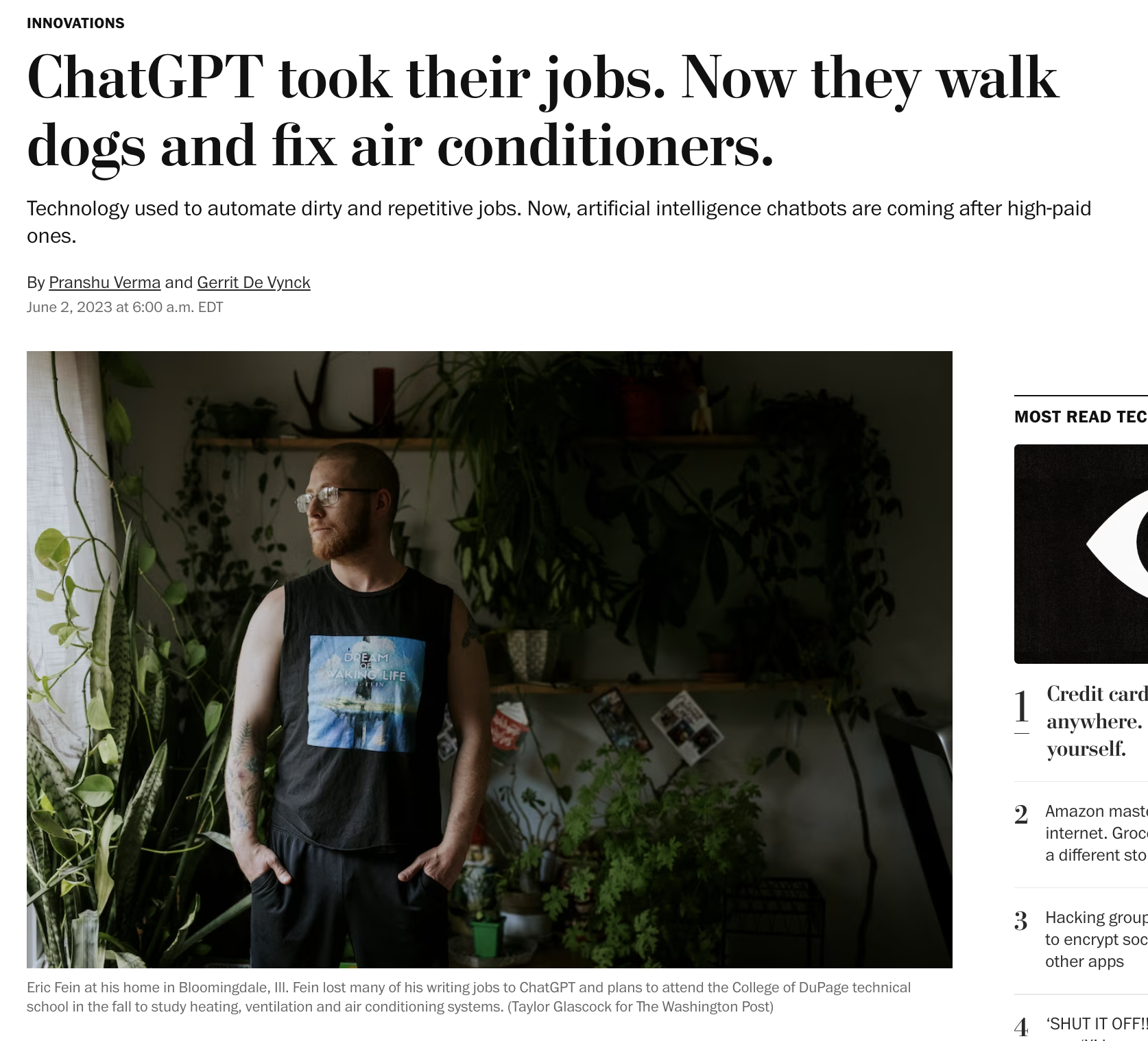
Labor Stability
Labor Stability


ChatGPT needs to “drink” a 500ml bottle of [fresh] water for a simple conversation of roughly 20-50 questions and answers, depending on when and where ChatGPT is deployed.
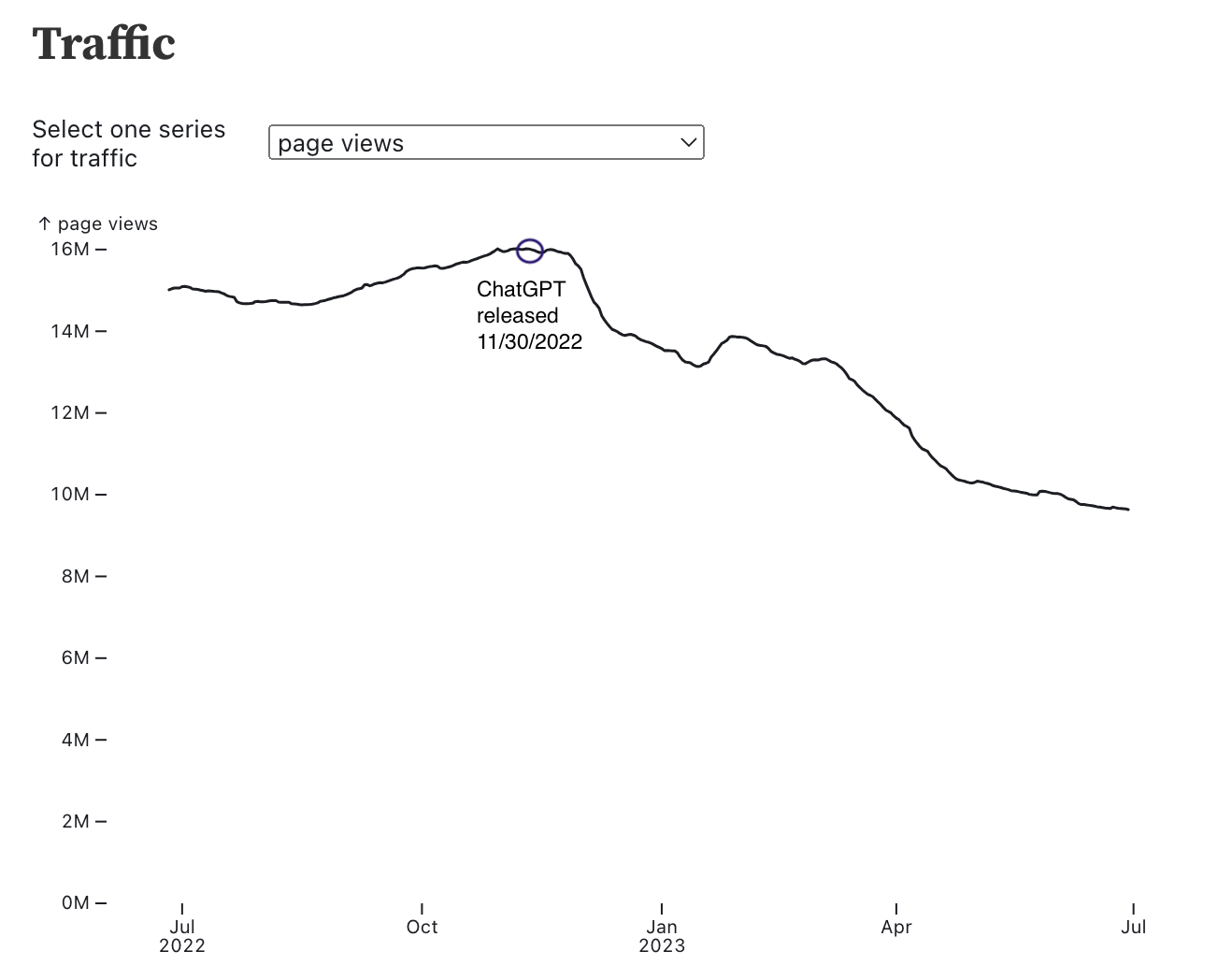
Roughly 1B visitors interacted with with the ChatGPT website in July, for 7 mins on average.
If each user submitted one prompt, that’s roughly 350K-850K liters of water per day.
This is daily drinking water for roughly 100K-300K people.
Li et al, arXiv preprint (2023)
https://www.similarweb.com/website/chat.openai.com/#overview
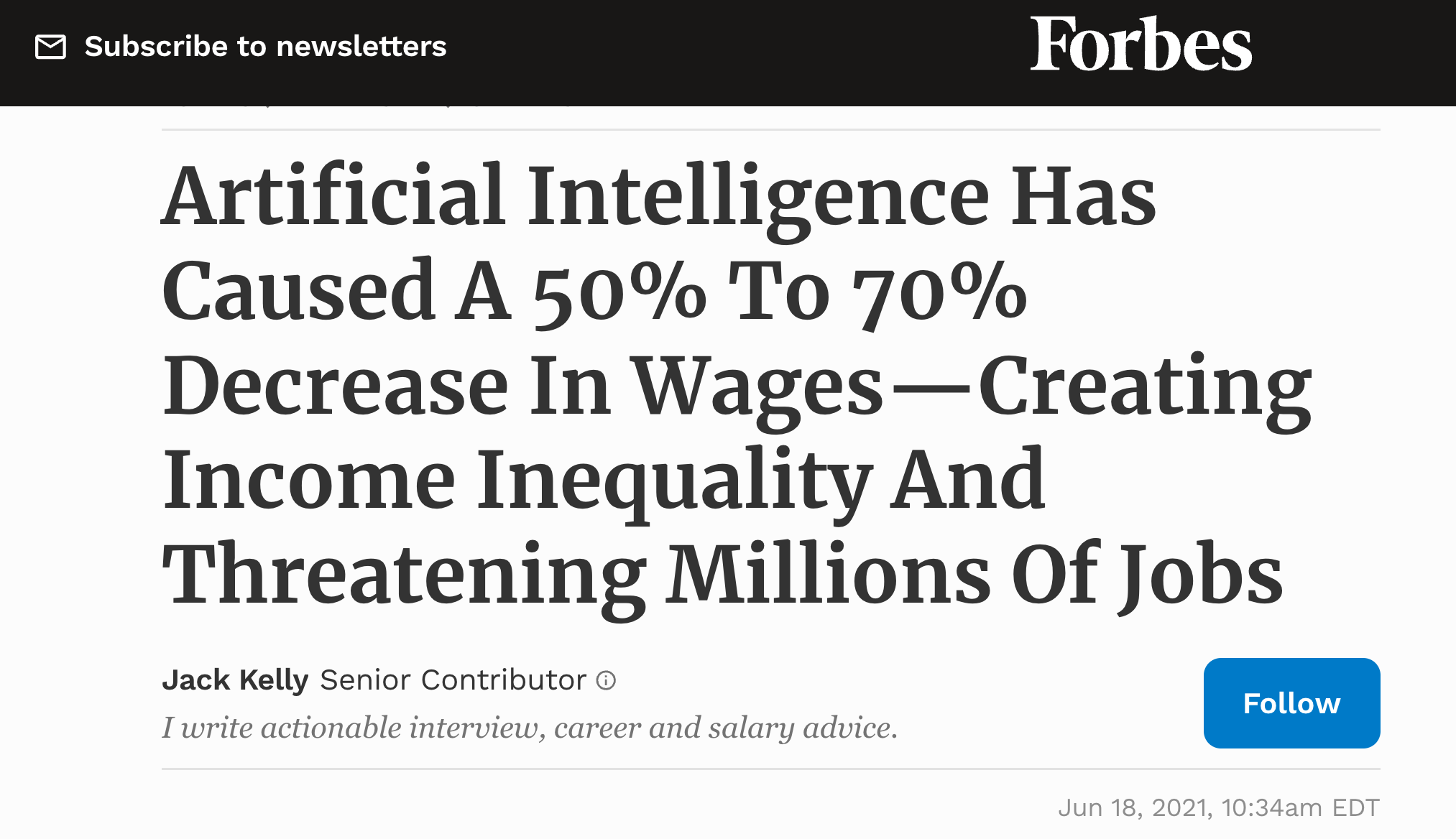
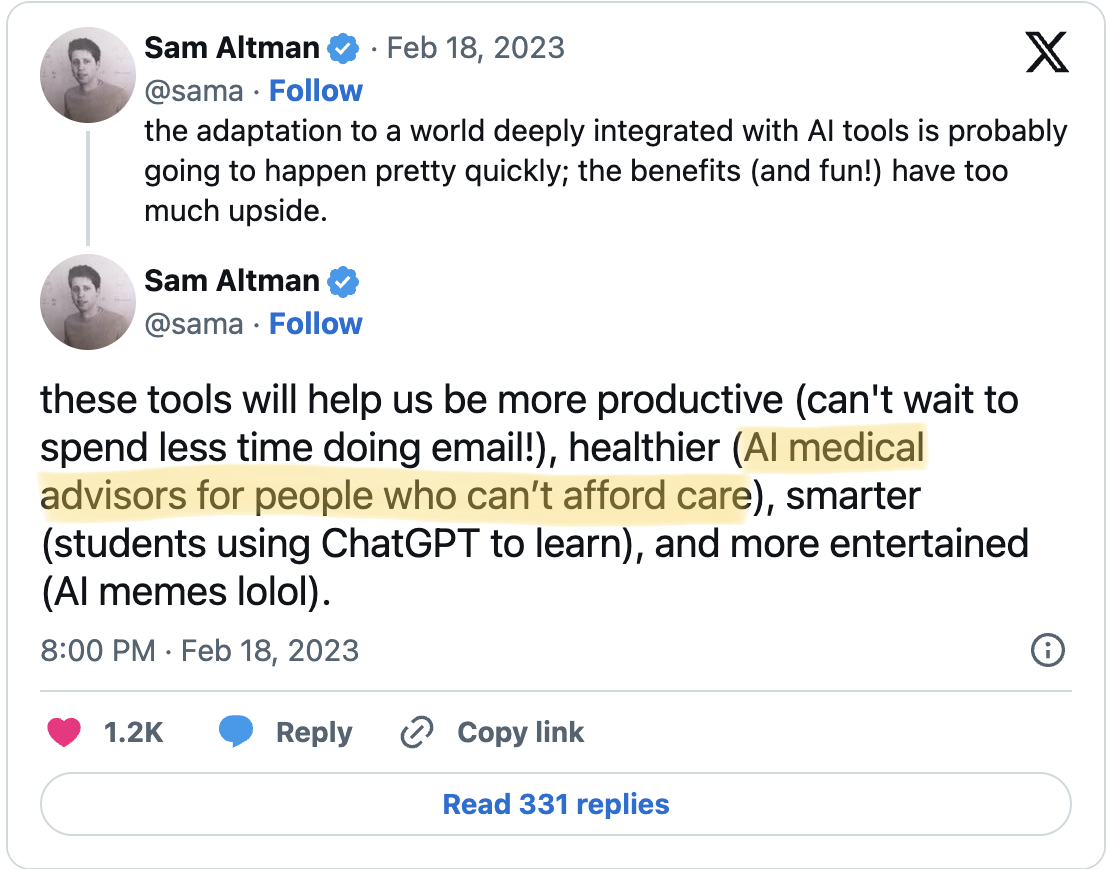
Years of sociotechnical research show that advanced digital technologies, left unchecked, are used to pursue power and profit at the expense of human rights, social justice, and democracy.

Business Insider
Critical Scholarship in AI


Modern automated information systems reproduce harmful representations of marginalized identities.
Safiya Umoja Noble
Critical Scholarship in AI


Ruha Benjamin
Modern automated information systems reinforce ideologies of white supremacy and colonialism.
Critical Scholarship in AI


Joy Buolamwini
Modern automated information systems serve and impact people of color (esp. women of color) in harsher ways.
Critical Scholarship in AI

Virginia Eubanks
Many modern automation systems are explicitly designed to control marginalized populations.
Critical Scholarship in AI


Timnit Gebru
Rhetoric from contemporary tech leaders continues intellectual lineages with roots in eugenics.